







今天聊聊 Kotlin 的协程。
协程是 Kotlin 中一个重要的特性支持,而 Kotlin 协程的支持,底层依托于虚拟机的特性。它与线程的关系,依然是 1:1 对应的。而不是类似 Go 语言这种,真的存在更小的执行体,是一种轻量级线程。
Kotlin 的协程,可以理解为一种类似线程池的封装,每个协程执行的背后,都依托于一个线程。而它与线程池相比的优势,在于用更精炼的代码,利用阻塞的思想写出非阻塞式的代码。
技术不管底层如何实现,我们最先了解的依然是如何使用它,它的作用域、操作符等等细节。
接下来推荐来自「九心」的 Kotlin 协程系列的第一篇:《即学即用Kotlin - 协程》,讲解 Kotlin 协程使用。我对原文略作校对和调整,希望更有利于大家的阅读。
前言
上周在内部分享会上大佬同事分享了关于 Kotlin 协程的知识,之前有看过 Kotlin 协程的一些知识,以为自己还挺了解协程的,结果...

在这一次分享中,发现 Flow 和 Channel 这一块儿知识是自己不怎么了解的,本文也将着重和大家聊一聊这一块儿的内容。
目录
一、基础
1. 概念
相信大家或多或少的都了解过,协程是什么,官网上这么说:
“Essentially, coroutines are light-weight threads.
协程是轻量级的线程,为什么是轻量的?可以先告诉大家结论,因为它基于线程池 API,所以在处理并发任务这件事上它真的游刃有余。
有可能有的同学问了,既然它基于线程池,那我直接使用线程池或者使用 Android 中其他的异步任务解决方式,比如 Handler、RxJava等,不更好吗?
协程可以使用阻塞的方式写出非阻塞式的代码,解决并发中常见的回调地狱,这是其最大的优点,后面介绍。
2. 使用
GlobalScope.launch(Dispatchers.Main) {
val res = getResult(2)
mNumTv.text = res.toString()
}
启动协程的代码就是如此的简单。上面的代码中可以分为三部分,分别是 GlobalScope、Dispatcher 和 launch,他们分别对应着协程的作用域、调度器和协程构建器,我们挨个儿介绍。
协程作用域
协程的作用域有三种,他们分别是:
-
runBlocking:顶层函数,它和coroutineScope不一样,它会阻塞当前线程来等待,所以这个方法在业务中并不适用; -
GlobalScope:全局协程作用域,可以在整个应用的声明周期中操作,且不能取消,所以仍不适用于业务开发; -
自定义作用域:自定义协程的作用域,不会造成内存泄漏;
显然,我们不能在 Activity 中调用 GlobalScope,这样可能会造成内存泄漏,看一下如何自定义作用域,具体的步骤我在注释中已给出:
class MainActivity : AppCompatActivity() {
// 1. 创建一个 MainScope
val scope = MainScope()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
// 2. 启动协程
scope.launch(Dispatchers.Unconfined) {
val one = getResult(20)
val two = getResult(40)
mNumTv.text = (one + two).toString()
}
}
// 3. 销毁的时候释放
override fun onDestroy() {
super.onDestroy()
scope.cancel()
}
private suspend fun getResult(num: Int): Int {
delay(5000)
return num * num
}
}
调度器
调度器的作用,是将协程限制在特定的线程执行。主要的调度器类型有:
-
Dispatchers.Main:指定执行的线程是主线程,如上面的代码; -
Dispatchers.IO:指定执行的线程是 IO 线程; -
Dispatchers.Default:默认的调度器,适合执行 CPU 密集性的任务; -
Dispatchers.Unconfined:非限制的调度器,指定的线程可能会随着挂起的函数的发生变化;
什么是挂起?
我们就以吃饭为例,如果到公司对面的广场吃饭得经过:
走到广场 10min > 点餐 5min > 等待上餐 10min > 就餐 30min > 回来 10 min
如果点广场的外卖呢?
九心:下单 5min > 等待(等待的时候可以工作) 30min > 就餐 30min
外卖骑手:到店 > 取餐 > 送外卖
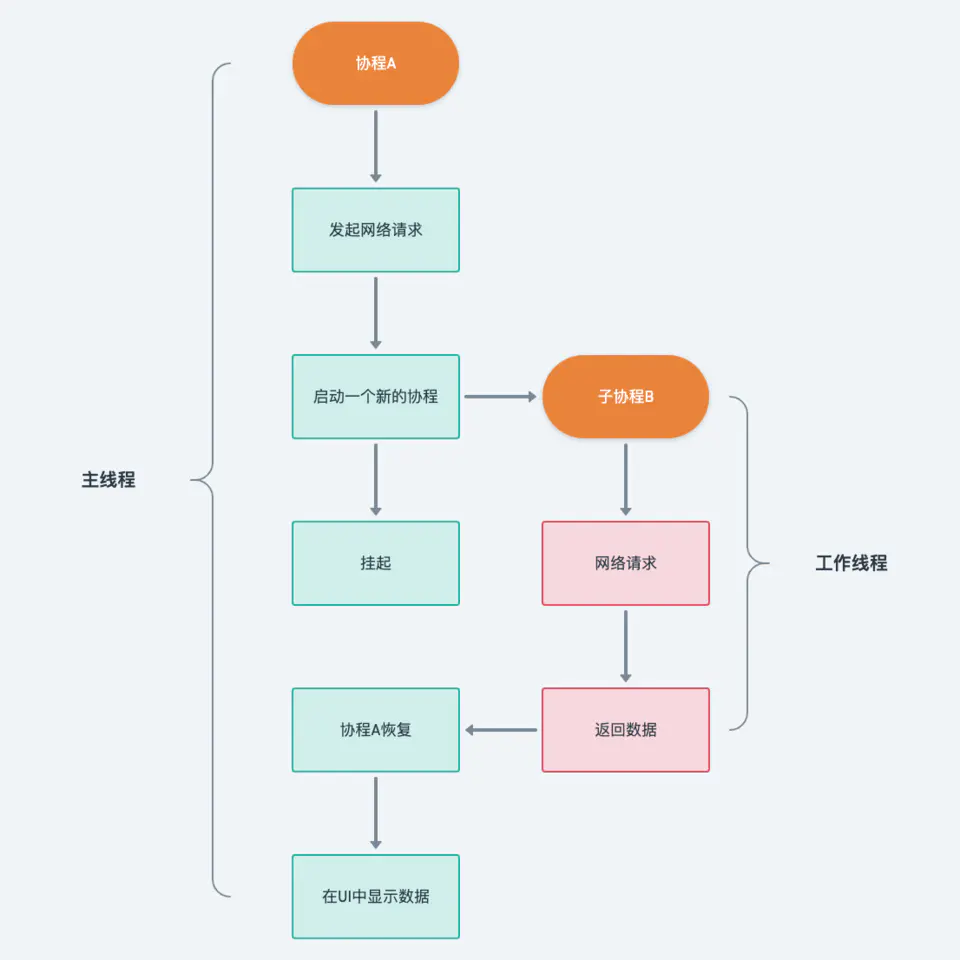
从吃饭的例子可以看出,如果点了外卖,花费的时间较少了,可以空闲出更多的时间做自己的事。再仔细分析一下,其实从公司到广场和等待取餐这个过程并没有省去,只是把这个过程交给了外卖员。
协程的原理跟点外卖的原理是一致的,耗时阻塞的操作并没有减少,只是交给了其他线程:
launch
launch 的作用从它的名称就可以看的出来,启动一个新的协程,它返回的是一个 Job对象,我们可以调用 Job#cancel() 取消这个协程。
除了 launch,还有一个方法跟它很像,就是 async,它的作用是创建一个协程,之后返回一个 Deferred<T>对象,我们可以调用 Deferred#await()去获取返回的值,有点类似于 Java 中的 Future,稍微改一下上面的代码:
class MainActivity : AppCompatActivity() {
// 1. 创建一个 MainScope
val scope = MainScope()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
// 2. 启动协程
scope.launch(Dispatchers.Unconfined) {
val one = async { getResult(20) }
val two = async { getResult(40) }
mNumTv.text = (one.await() + two.await()).toString()
}
}
// 3. 销毁的时候释放
override fun onDestroy() {
super.onDestroy()
scope.cancel()
}
private suspend fun getResult(num: Int): Int {
delay(5000)
return num * num
}
}
与修改前的代码相比,async 能够并发执行任务,执行任务的时间,也因此缩短了一半。
除了上述的并发执行任务,async 还可以对它的 start 入参设置成懒加载
val one = async(start = CoroutineStart.LAZY) { getResult(20) }
这样系统就可以在调用它的时候,再为它分配资源了。
suspend
suspend 是修饰函数的关键字,意思是当前的函数是可以挂起的,但是它仅仅起着提醒的作用。比如,当我们的函数中没有需要挂起的操作的时候,编译器会给我们提醒 Redudant suspend modifier,意思是当前的 suspend 是没有必要的,可以把它删除。
那我们什么时候需要使用挂起函数呢?常见的场景有:
-
耗时操作:使用
withContext切换到指定的 IO 线程去进行网络或者数据库请求; -
等待操作:使用
delay方法去等待某个事件;
withContext 的代码:
private suspend fun getResult(num: Int): Int {
return withContext(Dispatchers.IO) {
num * num
}
}
delay 的代码:
private suspend fun getResult(num: Int): Int {
delay(5000)
return num * num
}
结合 Android Jetpack
在介绍自定义协程作用域的时候,我们需要主动在 Activity 或者 Fragment 中的 onDestroy 方法中调用 job.cancel(),忘记处理可能是程序员经常会犯的错误,如何避免呢?
Google 总是能够解决程序员的痛点,在 Android Jetpack 中的 lifecycle、LiveData 和 ViewModel 已经集成了快速使用协程的方法,如果我们已经引入了 Android Jetpack,可以引入依赖:
dependencies {
def lifecycle_version = "2.2.0"
// ViewModel
implementation "androidx.lifecycle:lifecycle-viewmodel-ktx:$lifecycle_version"
// LiveData
implementation "androidx.lifecycle:lifecycle-livedata-ktx:$lifecycle_version"
// Lifecycles only (without ViewModel or LiveData)
implementation "androidx.lifecycle:lifecycle-runtime-ktx:$lifecycle_version"
}
使用可以结合具体的场景,比如结合 Lifecycle,需要使用 lifecycleScope 协程作用域:
lifecycleScope.launch {
// 代表当前生命周期处于 Resumed 的时候才会执行(选择性使用)
whenResumed {
// ... 具体的协程代码
}
}
即使你不使用 Android Jetpack 组件,由于 Lifecycles 在很早之前就内置在 Android 系统的代码中,所以你仍然可以仅仅引入 Lifecycle 的协程扩展库,因为它会帮助你很好的处理 Activity 或者 Fragment 的生命周期。
引入 Android Jetpack 协程扩展库官方文档:
https://developer.android.com/topic/libraries/architecture/coroutines?hl=zh-cn#lifecyclescope
二、流
长期以来,在 Android 中响应式编程的首选方案是 RxJava,我们今天就来了解一下 Kotlin中的响应式编程 Flow。如果你能熟练使用 RxJava,那你肯定能快速上手 Flow。
曾经我理解:LiveData 的使用类似于 RxJava,现在我收回这句话,事实上,LiveData 更加简单和纯粹,它建立单一的生产消费模型,Flow 才是类似于 RxJava 的存在。
1. 基础
先上一段代码:
lifecycleScope.launch {
// 创建一个协程 Flow<T>
createFlow()
.collect { num->
// 具体的消费处理
// ...
}
}
}
我在 createFlow 这个方法中,返回了 Flow<Int> 的对象,所以我们可以这样对比。

创建 Flow 对象
我们暂不考虑 RxJava中的背压和非背压,直接先将 Flow 对标 RxJava 中的 Observable。
和 RxJava 一样,在创建 Flow 对象的时候我们也需要调用 emit 方法发射数据:
fun createFlow(): Flow<Int> = flow {
for (i in 1..10)
emit(i)
}
一直调用 emit 可能不便捷,因为 RxJava 提供了 Observable.just() 这类的操作符,显然,Flow 也为我们提供了快速创建操作:
-
flowof(vararg elements: T):帮助可变数组生成Flow实例; -
扩展函数
.asFlow():面向数组、列表等集合;
比如可以使用 (1..10).asFlow() 代替上述的 Flow 对象的创建。
消费数据
collect 方法和 RxJava 中的 subscribe 方法一样,都是用来消费数据的。除了简单的用法外,这里有两个问题得注意一下:
-
collect函数是一个suspend方法,所以它必须发生在协程,或者带有suspend的方法里面,这也是我为什么在一开始的时候启动了lifecycleScope.launch; -
lifecycleScope是我使用的Lifecycle的协程扩展库当中的,你可以替换成自定义的协程作用域;
2. 线程切换
我们学习 RxJava 的时候,大佬们都会说,RxJava 牛逼,牛逼在哪儿呢?
切换线程,同样的,Flow 的协程切换也很牛逼。Flow 是这么切换协程的:
lifecycleScope.launch {
// 创建一个协程 Flow<T>
createFlow()
// 将数据发射的操作放到 IO 线程中的协程
.flowOn(Dispatchers.IO)
.collect { num ->
// 具体的消费处理
// ...
}
}
}
和 RxJava 对比:

改变数据发射的线程
flowOn 使用的参数是协程对应的调度器,它实质改变的是协程对应的线程。
改变消费数据的线程
我在上面的表格中,并没有写到在 Flow 中如何改变消费线程,这并不意味着 Flow 不可以指定消费线程。
Flow 的消费线程,在我们启动协程指定调度器的时候,就确认好了,对应着启动协程的调度器。比如在上面的代码中 lifecycleScope 启动的调度器是 Dispatchers.Main,那么 collect 方法就消费在主线程。
3. 异常和完成
异常捕获
Flow 中的 catch 对应着 RxJava 中的 onError,catch 操作:
lifecycleScope.launch {
flow {
//...
}.catch {e->
}.collect(
)
}
除此以外,你可以使用声明式捕获 try { } catch (e: Throwable) { } 去捕获异常,不过 catch 本质上是一个扩展方法,它是对声明式捕获的封装。
完成
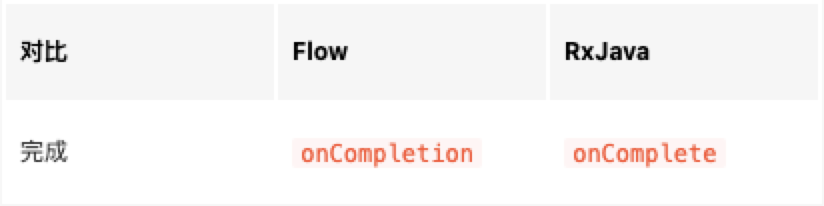
Flow 中的 onCompletion 对应着 RxJava 中的 onComplete 回调,onCompletion操作:
lifecycleScope.launch {
createFlow()
.onCompletion {
// 处理完成操作
}
.collect {
}
}
除此以外,我们还可以通过捕获式 try {} finally {} 去获取完成情况。
4. Flow的特点
我们在对 Flow 已经有了一些基础的认知了,再来聊一聊 Flow 的特点,Flow 具有以下特点:
-
冷流;
-
有序;
-
协作取消;
如果你对 Kotlin 中的 Sequence 有一些认识,那么你应该可以轻松的 Get 到前两个点。
冷流
有点类似于懒加载,当我们触发 collect 方法的时候,数据才开始发射。
lifecycleScope.launch {
val flow = (1..10).asFlow().flowOn(Dispatchers.Main)
flow.collect { num ->
// 具体的消费处理
// ...
}
}
}
也就是说,在第2行的时候,虽然流创建好了,但是数据一直到第四行发生 collect 才开始发射。
有序
看代码比较容易理解:
lifecycleScope.launch {
flow {
for(i in 1..3) {
Log.e("Flow","$i emit")
emit(i)
}
}.filter {
Log.e("Flow","$it filter")
it % 2 != 0
}.map {
Log.e("Flow","$it map")
"${it * it} money"
}.collect {
Log.e("Flow","i get $it")
}
}
得到的日志:
E/Flow: 1 emit
E/Flow: 1 filter
E/Flow: 1 map
E/Flow: i get 1 money
E/Flow: 2 emit
E/Flow: 2 filter
E/Flow: 3 emit
E/Flow: 3 filter
E/Flow: 3 map
E/Flow: i get 9 money
从日志中,我们很容易得出这样的结论,每个数据都是经过 emit、filter 、map和 collect 这一套完整的处理流程后,下个数据才会开始处理,而不是所有的数据都先统一 emit,完了再统一 filter,接着 map,最后再 collect。
协作取消
Flow 采用和协程一样的协作取消,也就是说,Flow 的 collect 只能在可取消的挂起函数中挂起的时候取消,否则不能取消。
如果我们想取消 Flow,得借助 withTimeoutOrNull 之类的顶层函数,不妨猜一下,下面的代码最终会打印出什么?
lifecycleScope.launch {
val f = flow {
for (i in 1..3) {
delay(500)
Log.e(TAG, "emit $i")
emit(i)
}
}
withTimeoutOrNull(1600) {
f.collect {
delay(500)
Log.e(TAG, "consume $it")
}
}
Log.e(TAG, "cancel")
}
5. 操作符对比
限于篇幅,我仅介绍一下 Flow 中操作符的作用,就不一一介绍每个操作符具体怎么使用了。
普通操作符:
普通 Flow 操作的作用:
-
map:转换操作符,将 A 变成 B; -
take:后面跟Int类型的参数,表示接收多少个emit出的值; -
filter:过滤操作符;
特殊的操作符
总会有一些特殊的情况,比如我只需要取前几个,我只要最新的数据等,不过在这些情况下,数据的发射就是并发执行的。
特殊 Flow 操作符的作用:
-
buffer:数据发射并发,collect不并发; -
conflate:发射数据太快,只处理最新发射的; -
collectLatest:接收处理太慢,只处理最新接收的;
组合操作符
组合 Flow 操作符的作用:
-
zip:组合两个流,双方都有新数据才会发射处理; -
combine:组合两个流,在经过第一次发射以后,任意方有新数据来的时候就可以发射,另一方有可能是已经发射过的数据;
展平流操作符
展平流有点类似于 RxJava 中的 flatmap,将你发射出去的数据源转变为另一种数据源。
展平流操作符的作用:
-
flatMapConcat:串行处理数据; -
flatMapMerge:并发collect数据; -
flatMapLatest:在每次emit新的数据以后,会取消先前的collect;
末端操作符
顾名思义,就是帮你做 collect 处理,collect 是最基础的末端操作符。
末端流操作符的作用:
-
collect:最基础的消费数据; -
toList:转化为List集合; -
toSet:转化为Set集合; -
first:仅仅取第一个值; -
single:确保流发射单个值; -
reduce:规约,如果发射的是Int,最终会得到一个Int,可做累加操作; -
fold:规约,可以说是reduce的升级版,可以自定义返回类型;
其他还有一些操作符,我这里就不一一介绍了,感兴趣可以查看 API。
三、通道
Channel是一个面向多协程之间数据传输的 BlockQueue。它的使用方式超级简单:
lifecycleScope.launch {
// 1. 生成一个 Channel
val channel = Channel<Int>()
// 2. Channel 发送数据
launch {
for(i in 1..5){
delay(200)
channel.send(i * i)
}
channel.close()
}
// 3. Channel 接收数据
launch {
for( y in channel)
Log.e(TAG, "get $y")
}
}
实现协程之间的数据传输需要三步。
1. 创建 Channel
创建的 Channel的方式可以分为两种:
-
直接创建对象:方式跟上述代码一致。
-
扩展函数
produce
如果使用了扩展函数,代码就变成了:
lifecycleScope.launch {
// 1. 生成一个 Channel
val channel = produce<Int> {
for(i in 1..5){
delay(200)
send(i * i)
}
close()
}
// 2. 接收数据
// ... 省略 跟之前代码一致
}
直接将第一步和第二步合并了。
2. 发送数据
发送数据使用的 Channel#send() 方法,当我们数据发送完毕的时候,可以使用 Channel#close() 来表明通道已经结束数据的发送。
3. 接收数据
正常情况下,我们仅需要调用 Channel#receive() 获取数据,但是该方法只能获取一次传递的数据,如果我们仅需获取指定次数的数据,可以这么操作:
repeat(4){
Log.e(TAG, "get ${channel.receive()}")
}
但如果发送的数据不可以预估呢?这个时候我们就需要迭代 Channel 了
for( y in channel)
Log.e(TAG, "get $y")
四、多协程数据处理
多协程处理并发数据的时候,原子性同样也得不到保证,协程中出了一种叫 Mutex 的锁,区别是它的 lock 操作是挂起的,非阻塞的,感兴趣的同学可以自行查看。
总结
个人感觉协程的主要作用,是简化代码的逻辑,减少了代码的回调地狱,结合 Kotlin,既可以写出优雅的代码,还能降低我们犯错的概率。
至于协程能带来比线程池更高的效率?呵~不存在的。
references:
-
https://juejin.im/post/6844904037586829320
-
https://www.kotlincn.net/docs/reference/coroutines/coroutines-guide.html
-
https://juejin.im/post/6844903949686800392















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









