






本系列文章是自己学习过程中的记录,如果有错误,欢迎各位交流指正。
基本思想: 输入无标签的数据,首先提取新特征,并与测试集中的每一个数据进行比较,然后从样本中提取k个最近邻(最相似)数据特征的分类标签, 统计这K个最近邻数据中出现次数最多的分类,将其作为新数据的类别。
伪代码:(对未知类别属性的数据集中的每个点执行以下操作)
(1)计算已知类别数据集中的点与当前点之间的距离。
(2)按照距离递增排序
(3)选取与当前距离最近的k个点
(4)确定前k个点所在类别出现的频率
(5)返回前k个点出现频率最高的类别作为当前点的预测分类
注:
在样本有限的情况下,KNN算法的误判概率和距离的具体测量有直接关系。通常常用: 欧式距离、马氏距离、曼哈顿距离等。其中欧式距离(二范数)最常用。
matlab代码:
% trainData 训练样本 n*p (n:个数 p: 维数)
% trainLabel 训练标签 n*1
% testData 测试样本 m*p
function target = KNN(trainData, trainlabel, testData, k)
classlabel = unique(trainlabel) % 得到样本标签(有哪几种标签)
c = length(classlabel) % 得到标签个数(共几类标签)
n = size(trainData,1) %得到训练样本个数
dist = zeros(n,1) % 存储 一个测试样本与所有训练样本的距离
for j=1:size(testData,1) % 遍历测试集中的每一个样本
cnt = zeros(c,1) % 存储前k个点所在类别出现的频率(个数)
for i=1:n % 遍历训练集中的每一个点
dist(i)=norm(trainData(i,:)-testData(j,:)) %计算一个测试点与所有训练数据距离。
end
[d,index] = sort(dist) % 递增排序 d:排序过后的值 index 为d中相对应值在原dist中的索引
for i=1:K
ind = find(classlabel == trainlabel(index(i))) %返回前k个点所在类别对应的标签 返回的ind值为{1,2,.... c}里面的 ** find的用法后面会提及。
cnt[ind] = cnt[ind]+1 % 标签出现一次 相对应的cnt位置加1.相当于计算前k个点所在类别出现的频率
end
[m,ind] = max(cnt) %返回前k个点出现频率最高的类别。 m为最大值,ind为最大值在cnt中对应的索引位置
target(j) = classlabel(ind) % 返回最终标签
end 注 find()的用法:
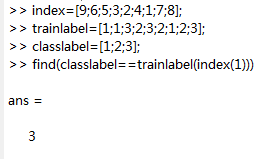
find()返回的是位置索引。
python 代码
KNN算法: 存在一个样本数据集合(训练样本集),并且每个数据都有标签。输入测试数据后(无标签的新数据)将新数据的每个特征与样本中数据对应的特征进行比较,然后算法提取样本集 中 特征最相似(近邻)的分类标签。一般来说,我们只选择样本数据集 中 前K个最相似数据。
- 使用python导入数据
from numpy import * # 导入numpy模块(科学计算包 矩阵运算)
import operator # 导入运算符模块
def creatDataset(): #定义一个函数 生成数据 4个样本 2类
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #注意格式
labels = ['A','A','B','B']
return group, labels这里有4组数据,每组数据有两个我们已知的属性或特征。
2. 实施KNN算法
根据上面的伪代码来解释每行代码的含义。
def classify(testdata, traindata, labels, k):
[m,n] = traindata.shape #等价于 m=traindata.shape[0] 获得行数
# n=traindata.shape[1] 列数
# (1)计算距离 欧式距离(第1步)
diffMat = tile(testdata,(m,1))-traindata # tile()相当于matla中的 repmat函数,将testdata重组为 m行1列。
sqdiffMat = diffMat**2 # **表示次方
sqdistance = sqdiffMat.sum(axis=1) # axis=0, 表示按列加。axis=1, 表示按行加行
distance = sqdistance**0.5
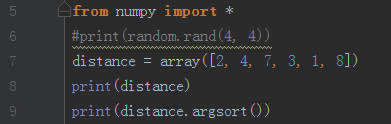
sorteddistance = distance.argsort() #返回排序后的索引 (第2步)
classcount={}#创建一个字典用来存储类别出现的频率
for i in range(k):# 第三步选前k个点对应的label
votelabel = labels[sorteddistance[i]]
classcount[votelabel] = classcount.get(votelabel,0)+1 # 第4步
#get(ith_label,0) : if dictionary 'vote' exist key 'ith_label', return vote[ith_label]; else return 0
sortedclasscount = sorted(classcount.items(), key=operator.itemgetter(1), reverse=True) #reverse=True 从大到小排列
return sortedclasscount[0][0]注
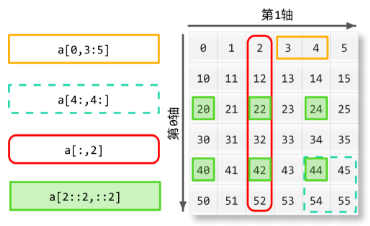
(a) python二维数组:
(b) 欧式距离: 计算两个向量点xA和xB之间的距离
(xA0−xB0)2+(xA1−xB1)2−−−−−−−−−−−−−−−−−−−−−−−−√
(c) numpy.sort() 函数
Returns the indices that would sort an array. 返回数组排序后的index(索引) 索引从0开始
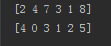
结果:
(d) 字典的get()函数 get(ith_label,0) :
if dictionary ‘vote’ exist key ‘ith_label’, return vote[ith_label]; else return 0
如果字典vote存在ith_label 键 则返回 vote[ith_label]的值 否则返回 0
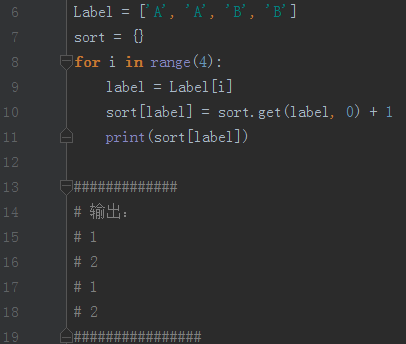
(e) iteritems() 用于返回本身字典列表操作后的迭代
在3.x 里 用 items()替换iteritems() ,可以用于 for 来循环遍历。
(f)

(g) key=operator.itemgetter(1) 等价于 lambda x: x[1]
operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为一些序号(即需要获取的数据在对象中的序号) 要注意,operator.itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值。

(h) sortedclasscount = sorted(classcount.items(), key=operator.itemgetter(1), reverse=True) 分析
classcount 是一个字典 如 {‘A’:1, ‘B’:2}
item() 返回元组对列表 如 [(‘A’,1), (‘B’,2)]
key=operator.itemgetter(1) 返回一个函数。在这里 就是以元组里面索引是1的元素排序。即按照数字1,2 排序
最终返回 [(‘B’,2),(‘A’,1)]
sortedclasscount[0][0] 先取出 list的第一个元素 (‘B’,2) 再取出元组的第一个元素‘B’. 为最终标签















 3104
3104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









