






本文来源于 Machine Learning in Action
**使用KNN改进约会网站的匹配效果**
步骤:原始数据预处理—分析数据—-训练算法—测试算法—-使用算法
1 原始数据预处理
本书中提供的原始数据(TXT)格式如下:
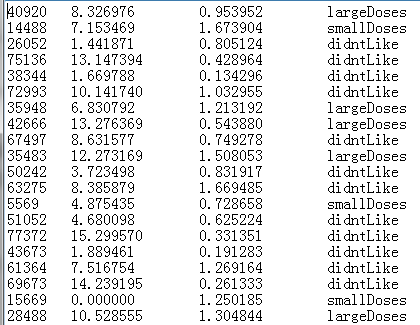
前3列为特征(飞机的里程数、玩游戏耗费时间、每周消费冰激凌的公斤数)。最后一列 为类别(不喜欢的、魅力一般的、极具魅力的)
显然,最后一列不利于数值分析以及数值范围不一致 不利于画图。所以在预处理阶段要执行两个步骤: 将文本记录转化为适合数值分析的矩阵 、 数值归一化
准备: numpy模块
说明文档: https://docs.scipy.org/doc/numpy-dev/reference/index.html#reference
1.1 将文本记录转化为适合数值分析的矩阵形式
from numpy import *
def text2matrix(filename):
file = open(filename) # 打开文件
arraylines = file.readlines() # 按行读取文件 readlines() 自动将文件内容分析成一个行的列表 可用for循环来处理
numberlines = len(arraylines) #行数
returnMat = zeros((numberlines,3))# 存储格式化后的数据 注(a)
classlabel = [] #存储标签
classlabeltemp=[]
index = 0
for line in arraylines:
line = line.strip() # 去除每行开头、结尾处的空格
listFromline = line.split('\t') #按‘\t’ 分割数据, 返回list
returnMat[index,:] = listFromline[0:3] # 切片形式是 左闭右开 将listFromline的前3列数据放入returnMat的第一行
classlabeltemp.append(int(listFromline[-1]))# -1表示最后一个元素
for x in classlabeltemp:
if x == 'didntLike':
x = int(1) #要声明是int 要不然append后是以string形式加入的
elif x == 'smallDoses':
x = int(2)
else:
x = int(3)
classlabel.append(x)
index+=1
return returnMat, classlabel注
(a) numpy.zeros(shape[, dtype, order]) 后面两个参数 一般用不到
依据给定形状和类型(shape[, dtype, order])返回一个新的元素全部为0的数组。
shape一般为 int或者int的元组形式

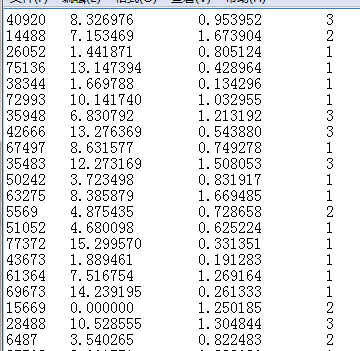
(b) 最后的格式为:
1.2 数据归一化
在处理不同取值范围的特征值时,通常采用数值归一化将取值范围处理到0到1之间。
newvalue=(oldvalue−min)/(max−min)
def autoNorm(dataset):
minvalue = dataset.min(0) # min(0)操作是对列进行的,选出每一列的最小值,相应的min(1)就是对于行操作的。
maxvalue = dataset.max(0)
ranges = maxvalue - minvalue
[m,n] = dataset.shape # shape[0] shape[1]
normData = (dataset-tile(minvalue, (m,1)))/tile(ranges, (m,1)) # / 除法 结果为 float // 为除法去整
return normData, ranges, minvalue2 分析数据 (我们下一节具体分析代码)
为了更加直观的分析数据,我们将数据用图形化的方式表现出来。python 用 Matplotlib 模块来画图:
Matplotlib 是一个由 John Hunter 等开发的,用以绘制二维图形的 Python 模块。它利用了 Python 下的数值计算模块 Numeric 及 Numarray,克隆了许多 Matlab 中的函数, 用以帮助用户轻松地获得高质量的二维图形。Matplotlib 可以绘制多种形式的图形包括普通的线图,直方图,饼图,散点图以及误差线图等;可以比较方便的定制图形的各种属性比如图线的类型,颜色,粗细,字体的大小 等;它能够很好地支持一部分 TeX 排版命令,可以比较美观地显示图形中的数学公式。Matplotlib 掌握起来也很容易,由于 Matplotlib 使用的大部分函数都与 Matlab 中对应的函数同名,且各种参数的含义,使用方法也一致,这就使得熟悉 Matlab 的用户使用起来感到得心应手。对那些不熟悉的 Matlab 的用户而言,这些函数的意义往往也是一目了然的,因此只要花很少的时间就可以掌握。
3 训练、测试、使用算法
3.1 测试算法 (即用自带数据测试上节课的KNN分类器)
机器学习算法的一个很重要的工作就是评估算法的正确率,通常我们用已提供数据的90%进行训练,其余进行测试,来检测正确率。(随机选取 训练。测试数据)
对于分类器来说, 正确率就是分类器给出正确结果的次数除以测试数据的总数。(0-1)
代码中,我们设置一个计数器,每次分类正确,计数器加1,最后程序结束后,用计数器的结果除以数据点总数就是正确率。
def classtest():
Ratio = 0.1 # 10%的数据进行测试
data, label = text2matrix("datingTestSet.txt")# 调用函数 整理数据
normMat, ranges, minvals = autoNorm(data) # 归一化
n = normMat.shape[0]
numtest = int(m*Ratio)
count = 0
for i in range(numtest):
classfierresult = classify(normMat[i,:],normMat[numtest:m,:],label[numtest:m],3) #调用KNN的核心算法函数(第一节课中) classify(testdata, traindata, labels, k)
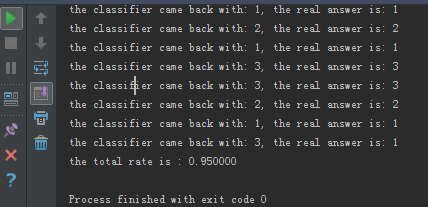
print("the classifier came back with: %d, the real answer is: %d" % (classfierresult, label[i]))
if (classfierresult == label[i]):
count += 1
print("the total rate is : %f" % (count/float(numtest)))运行结果:
完整代码:
# -*- coding: utf-8 -*-
from numpy import *
import operator
def text2matrix(filename):
file = open(filename) # 打开文件
arraylines = file.readlines() # 按行读取文件 readlines() 自动将文件内容分析成一个行的列表 可用for循环来处理
numberlines = len(arraylines) #行数
returnMat = zeros((numberlines,3))# 存储格式化后的数据 注(a)
classlabel = [] #存储标签
classlabeltemp=[]
index = 0
for line in arraylines:
line = line.strip() # 去除每行开头、结尾处的空格
listFromline = line.split('\t') #按‘\t’ 分割数据, 返回list
returnMat[index, :] = listFromline[0:3] # 切片形式是 左闭右开 将listFromline的前3列数据放入returnMat的第一行
classlabeltemp.append((listFromline[-1])) # -1表示最后一个元素
for x in classlabeltemp:
if x == 'didntLike':
x = int(1) #要声明是int 要不然append后是以string形式加入的
elif x == 'smallDoses':
x = int(2)
else:
x = int(3)
classlabel.append(x)
index += 1
return returnMat, classlabel
def autoNorm(dataset):
minvalue = dataset.min(0) # min(0)操作是对列进行的,选出每一列的最小值,相应的min(1)就是对于行操作的。
maxvalue = dataset.max(0)
ranges = maxvalue - minvalue
m = dataset.shape[0] # shape[0] shape[1]
normData = (dataset-tile(minvalue, (m,1)))/tile(ranges, (m,1)) # / 除法 结果为 float // 为除法去整
return normData, ranges, minvalue
def classify(testdata, traindata, labels, k):
[m,n] = traindata.shape #等价于 m=traindata.shape[0] 获得行数
# n=traindata.shape[1] 列数
# (1)计算距离 欧式距离(第1步)
diffMat = tile(testdata,(m,1))-traindata # tile()相当于matla中的 repmat函数,将testdata重组为 m行1列。
sqdiffMat = diffMat**2 # **表示次方
sqdistance = sqdiffMat.sum(axis=1) # axis=0, 表示按列加。axis=1, 表示按行加行
distance = sqdistance**0.5
sorteddistance = distance.argsort() #返回排序后的索引 (第2步)
classcount={}#创建一个字典用来存储类别出现的频率
for i in range(k):# 第三步选前k个点对应的label
votelabel = labels[sorteddistance[i]]
classcount[votelabel] = classcount.get(votelabel,0)+1 # 第4步
sortedclasscount = sorted(classcount.items(), key=operator.itemgetter(1), reverse=True) #reverse=True 从大到小排列
return sortedclasscount[0][0]
def classifyperson():
resultlist = ['不喜欢', '有点魅力', '很有魅力']
percenTats = float(input("打游戏时间:")) # python3.X 将raw_input改为input
ffMiles = float(input("每年获得的飞行里程数:"))
icecream = float(input("吃冰激凌的公斤数:"))
data, label = text2matrix("datingTestSet.txt")# 调用函数 整理数据
normMat, ranges, minvals = autoNorm(data) # 归一化
inArr = array([ffMiles, percenTats, icecream])
normT = (inArr-minvals)/ranges
classfierresult = classify(normT, data, label, 3)
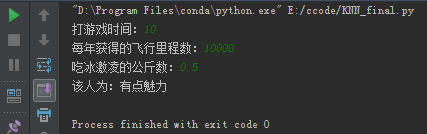
print("该人为:%s" % resultlist[classfierresult-1]) # 因为输出标签 为1 2 3, 而 resultlist索引从0开始,所以要减去1
if __name__ == '__main__':
classifyperson()运行结果:















 2805
2805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









