






1.KNN算法概述
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
2.KNN算法原理
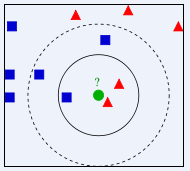
如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。
KNN 算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适
3.KNN算法流程
对每一个未知点执行:
1.计算未知点到所有已知类别点的距离
2.按距离排序(升序)
3.选取其中前k个与未知点离得最近的点
4.统计k个点中各个类别的个数
5.上述k个点里类别出现频率最高的作为未知点的类别
4.Python实现
import matplotlib.pyplot as plt
import matplotlib
from math import sqrt
#初始化数据集#
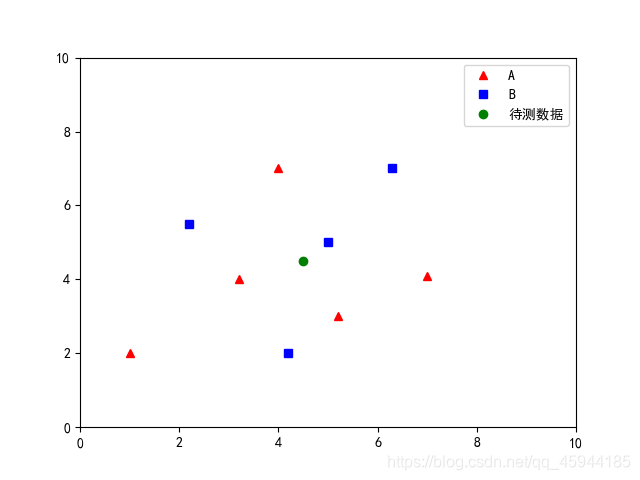
data_A = [[1,2],[3.2,4],[4,7],[5.2,3],[7,4.1]]#数据集A
data_B = [[2.2,5.5],[4.2,2],[5,5],[6.3,7]]#数据集B
test_data = [[4.5,4.5]]#测试集
len_A = len(data_A)
len_B = len(data_B)
#计算距离并排序#
distance_A = []#与A类数据之间的距离
distance_B = []#与B类数据之间的距离
distance = []#全部距离
#计算距离(使用欧氏距离)
for i in range(len_A):
d = sqrt((test_data[0][0]-data_A[i][0])**2+(test_data[0][1]-data_A[i][1])**2)
distance_A.append(d)
for i in range(len_B):
d = sqrt((test_data[0][0]-data_B[i][0])**2+(test_data[0][1]-data_B[i][1])**2)
distance_B.append(d)
#由小到大排序(此处使用冒泡排序)
distance = distance_A + distance_B
for i in range(len(distance)-1):
for j in range(len(distance)-i-1):
if distance[j] > distance[j+1]:
distance[j],istance[j+1]=distance[j+1],distance[j]
print("距离所有A类数据的距离为:")
print(distance_A)
print("距离所有B类数据的距离为:")
print(distance_B)
print()
print("对所有的距离升序排序:")
print(distance)
print()
#按K最近领对测试集进行分类#
K = 5#这里默认K值为5,也可以自行更改
number_A = 0
number_B = 0
#定义删除函数,避免对同一个数据重复计算
def delete(a,b,ls):
for i in range(b):
if ls[i]==a:
ls.pop(i)
break
#找出与测试数据最接近的K个点
for i in range(K):
if distance[i] in distance_A:
number_A += 1
delete(distance[i],len(distance_A),distance_A)
continue
if distance[i] in distance_B:
number_B += 1
delete(distance[i],len(distance_B),distance_B)
continue
print("最终结果:")
print("距离待测数据最近的K={:}个数据中,A类数据有{:}个,B类数据有{:}个".format(K,number_A,number_B))
if number_A > number_B:
print("所以K={:}时,待测数据划分为A类".format(K))
else:
print("所以K={:}时,待测数据划分为B类".format(K))
#画图#
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
for i in range(len_A):#A类,用红色三角形表示
if i!=len_A-1:
plt.plot(data_A[i][0],data_A[i][1],'bo',marker='^',color='red')
else:
plt.plot(data_A[i][0],data_A[i][1],'bo',marker='^',label='A',color='r')
#使用if..else...是为了避免在图形中重复出现多个标签
for i in range(len_B):#B类,用蓝色正方形表示
if i!=len_B-1:
plt.plot(data_B[i][0],data_B[i][1],'bo',marker='s',color='blue')
else:
plt.plot(data_B[i][0],data_B[i][1],'bo',marker='s',label='B',color='b')
plt.plot(test_data[0][0],test_data[0][1],'bo',label='待测数据',color='g')#测试集
plt.xlim(0,10)
plt.ylim(0,10)
plt.legend()
plt.show()
5.鸢尾花实列分析
import numpy as np
from math import sqrt
#对003-AI-KNN-datasets-Iris.txt数据进行处理
raw_data_X=np.loadtxt('003-AI-KNN-datasets-Iris.txt',dtype=float,delimiter=',',usecols=(0,1,2,3))
raw_data_y=np.loadtxt('003-AI-KNN-datasets-Iris.txt',dtype=str,delimiter=',',usecols=(4))
#把整个数据集以1:4的比例随机分为测试集和训练集
arr = np.random.choice(int(len(raw_data_X)),size=30,replace=False)
X_train=np.delete(raw_data_X,arr,axis=0)
y_train=np.delete(raw_data_y,arr)
print("训练集数据")
print(X_train)
x_test=[]
y_test=[]
for i in arr:
x_test.append(raw_data_X[i])
y_test.append(raw_data_y[i])
X_test=np.array(x_test)
print("测试集数据")
print(X_test)
k=9#k值可以自己设定
#欧式距离,曼哈顿距离#
def oushi(x_train,X_test,j):
return d=sqrt(np.sum((x_train - X_test[j])**2))
def manhadun(x_train,X_test,j):
return d=np.sum(abs(x_train-X_test[j]))
e=0
for j in range(len(X_test)):
distance=[]
for x_train in X_train:
#oushi(x_train,X_test,j)欧式距离
#manhadun(x_train,X_test,j)曼哈顿距离
distance.append(d)
nearest=np.argsort(distance)
b=0
c=0
a=0
for l in nearest[:k]:
#print(l)
if y_train[l]=='Iris-setosa':
a=a+1
elif y_train[l]=='Iris-versicolor':
b=b+1
else:
c=c+1
if a==max(a,b,c):
print('第{}组,预测值:Iris-setosa,真实值:{}'.format(j+1,y_test[j]))
d='Iris-setosa'
elif b==max(a,b,c):
print('第{}组,预测值:Iris-versicolor,真实值:{}'.format(j+1,y_test[j]))
d='Iris-versicolor'
else:
print('第{}组,预测值:Iris-virginica,真实值:{}'.format(j + 1, y_test[j]))
d='Iris-virginica'
#print(d)
if d==y_test[j]:
e=e+1
print("准确率")
print(e/len(y_test))
欧式距离:
第1组,预测值:Iris-versicolor,真实值:Iris-versicolor
第2组,预测值:Iris-versicolor,真实值:Iris-versicolor
第3组,预测值:Iris-virginica,真实值:Iris-virginica
第4组,预测值:Iris-versicolor,真实值:Iris-versicolor
第5组,预测值:Iris-virginica,真实值:Iris-virginica
第6组,预测值:Iris-versicolor,真实值:Iris-versicolor
第7组,预测值:Iris-versicolor,真实值:Iris-versicolor
第8组,预测值:Iris-virginica,真实值:Iris-virginica
第9组,预测值:Iris-setosa,真实值:Iris-setosa
第10组,预测值:Iris-versicolor,真实值:Iris-versicolor
第11组,预测值:Iris-setosa,真实值:Iris-setosa
第12组,预测值:Iris-virginica,真实值:Iris-virginica
第13组,预测值:Iris-virginica,真实值:Iris-virginica
第14组,预测值:Iris-virginica,真实值:Iris-virginica
第15组,预测值:Iris-setosa,真实值:Iris-setosa
第16组,预测值:Iris-virginica,真实值:Iris-virginica
第17组,预测值:Iris-virginica,真实值:Iris-virginica
第18组,预测值:Iris-virginica,真实值:Iris-virginica
第19组,预测值:Iris-setosa,真实值:Iris-setosa
第20组,预测值:Iris-versicolor,真实值:Iris-versicolor
第21组,预测值:Iris-versicolor,真实值:Iris-versicolor
第22组,预测值:Iris-versicolor,真实值:Iris-versicolor
第23组,预测值:Iris-virginica,真实值:Iris-virginica
第24组,预测值:Iris-setosa,真实值:Iris-setosa
第25组,预测值:Iris-versicolor,真实值:Iris-versicolor
第26组,预测值:Iris-setosa,真实值:Iris-setosa
第27组,预测值:Iris-virginica,真实值:Iris-virginica
第28组,预测值:Iris-virginica,真实值:Iris-virginica
第29组,预测值:Iris-setosa,真实值:Iris-setosa
第30组,预测值:Iris-virginica,真实值:Iris-versicolor
准确率:
0.9666666666666667














 2622
2622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









