






实例分析(Matlab)
实例 1 来源于 http://blog.csdn.net/zhulf0804/article/details/52424809 加以整理分析
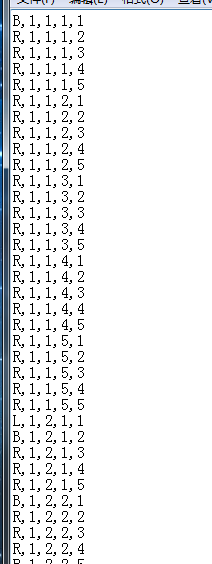
数据说明:
共5列, 有625个训练样例 第一列为标签,剩余4列为属性(x1 x2 x3 x4)
标签 :R L B 属性值 为 1 2 3 4 5
我们在这里序号末尾为1的样本当作测试集,共有63个,其他的作为训练集,共有562个
clc;clear;close all;
% 没有头文件并且全是数字用load,有头文件并且数据类型统一用importdata
% 如果没有文件头,importdata读出来的是一个数组,不再是数据结构,不能用A.data去访问
% 数据,直接用A就可以了
file = importdata('data.txt'); % importdata 读取txt,返回data和textdata两个变量 data存储数据矩阵(只有数字) textdata存储元素矩阵
data = file.data; % 得到数据矩阵
m = size(file.textdata, 1); % 得到数据大小
% 将标签 L B R 用1 2 3 代替
label = zeros(m,1);
for i=1:m
if (file.textdata{i,1} == 'L') % file.data为cell形式,可通过file.data{i,j} 调用第i个cell里的第j个值 还可以通过 strcmp(A,B)函数来实现
label(i) = 1;
elseif (file.textdata{i,1} == 'B')
label(i) = 2;
else
label(i) = 3;
end
end
% 朴素贝叶斯算法实现分类问题(三类 1 2 3)
% 我们在这里序号末尾为1的样本当作测试集,共有63个,其他的作为训练集,共有562个
% 联系前面的公式 V={1,2,3} 属性为{x1 x2 x3 x4} 属性值为(1,2,3,4,5)
% 比如一个实例<x1=1,x2=3,x3=4,x4=5>
m_test = 63;
m_train = 562;
count1 = 0; % 第一类样本的数量 用于计算P(V_i)
count2 = 0;
count3 = 0;
count_1 = zeros(4,5); % 存储第一类 第i个属性 值为j的样本个数 用于计算P(i = j|v_i)
count_2 = zeros(4,5);
count_3 = zeros(4,5);
%test = [];
counttemp = 1;
% 抽出训练矩阵和测试矩阵,并计算每个属性值出现的数量
for i=1:m
if (mod(i,10)==1) % 序号末尾为1的样本
test(counttemp,:) = data(i,:);
test_label(counttemp,:) = label(i,:);
counttemp = counttemp+1;
else
train = data(i,:); % 1*4 向量
if label(i)==1 %如果是第一类样本
count1 = count1+1; % 计算第一类样本的总数量
for j=1:4 % 第i个属性
for k=1:5 % 第j个属性
if (train(j)==k) % 属性值同
count_1(j,k) = count_1(j,k)+1; % 第一类,第i个属性 ,值为j的样本个数
break; % 为什么用break????
end
end
end
elseif (label(i)==2)
count2 = count2+1; % 计算第一类样本的总数量
for j=1:4 % 第i个属性
for k=1:5 % 第j个属性
if (train(j)==k) % 属性值同
count_2(j,k) = count_2(j,k)+1; % 第2类,第i个属性 ,值为j的样本个数
break; % 为什么用break????
end
end
end
else
count3 = count3+1; % 计算第一类样本的总数量
for j=1:4 % 第i个属性
for k=1:5 % 第j个属性
if (train(j)==k) % 属性值同
count_3(j,k) = count_3(j,k)+1; % 第3类,第i个属性 ,值为j的样本个数
break; % 为什么用break????
end
end
end
end
end
% 利用上面的数量来求频率
p1 = count1/m_train; %P(V_i)
p2 = count2/m_train;
p3 = count3/m_train;
% 然后求P(i = j|v_i)
for i=1:4
for j=1:5
p_1(i,j) = count_1(i,j)/count1; % 第一类 属性i值为j的概率
p_2(i,j) = count_2(i,j)/count2;
p_3(i,j) = count_3(i,j)/count3;
end
end
end
%%% 接下来做预测!! 求V_NB
rate = 0; %正确率
for i=1:m_test
X = test(i,:);
Y = test_label(i);
% 分别求出三类的朴素贝叶斯概率
Vnb_1 = p1*p_1(1,X(1))*p_1(2,X(2))*p_1(3,X(3))*p_1(4,X(4)); % 共四个属性,用测试样本来实例化
Vnb_2 = p2*p_2(1,X(1))*p_2(2,X(2))*p_2(3,X(3))*p_2(4,X(4));
Vnb_3 = p3*p_3(1,X(1))*p_3(2,X(2))*p_3(3,X(3))*p_3(4,X(4));
% 下面求出正确率
if (max(Vnb_1,max(Vnb_2,Vnb_3)) == Vnb_1) % 判断三个里面最大的 判为该类
if Y == 1 % 如果实际分类和得到的分类相同
rate = rate+1;
end
end
if (max(Vnb_1,max(Vnb_2,Vnb_3))== Vnb_2) % 判断三个里面最大的 判为该类
if Y == 2 % 如果实际分类和得到的分类相同
rate = rate+1;
end
end
if (max(Vnb_1,max(Vnb_2,Vnb_3))== Vnb_3) % 判断三个里面最大的 判为该类
if Y == 3 % 如果实际分类和得到的分类相同
rate = rate+1;
end
end
end
fprintf('rate is %f', rate/m_test*100);
%%
% 输出 rate is 85.7143
%%代码: 链接:http://pan.baidu.com/s/1kVflcGJ 密码:78af
===================================================
实例 2 设计基于最小风险的贝叶斯分类器,将行人与背景进行分类
已知把行人分为背景的风险为1.5, 背景判为行人的风险是 0.5,假设出现背景的先验概率为0.95,出现行人的先验概率为0.05
由于是有监督的学习,所以要把样本随即划分为 等量的训练样本集和测试样本集。
原始行人样本和背景样本 都为 500*252 随机分割 250个样本
function [train, test] = randSeg(X)
%返回 随机选取的饿训练、测试样本集 基于最小风险的贝叶斯分类器
理论:

逐行写代码:
% 随机函数得到行人 背景 训练测试数据 hm_tr hm_test bg_tr bg_test 都为[250, 252]
M_hm = sum(hm_tr,1)/250; % 理论里面的 M1
M_bg = sum(bg_tr,1)/250; % M2
E_hm = (hm_tr-repmat(M_hm,250,1))*(hm_tr-repmat(M_hm,250,1))';
E_bg = (hm_bg-repmat(M_bg,250,1))*(hm_bg-repmat(M_bg,250,1))';
% 设计判决函数
count=0
for i=1:250
R1 = log(0.5)+log(0.95)+log(abs(det(E_bg)))/2-((hm_test(i,:)-M_bg)'*inv(E_bg)*(hm_test(i,:)-M_bg));
R2 = log(1.5) + log(0.05)+log(abs(det(E_hm)))/2-((hm_test(i,:)-M_hm)'*inv(E_hm)*(hm_test(i,:)-M_hm));
if (R1<=R2)
count = count+1; % 计数器,统计分类正确的个数
end
end
rate = count/250;














 2793
2793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









