






python 代码分析
1 * 使用朴素贝叶斯实现朴素贝叶斯分类器* (从实例出发)
首先构建数据 : 从文本中构建词向量,也就是说将句子转换为向量。
def loadDataSet():
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
# 给出6个文本list
classVec = [0,1,0,1,0,1] # 人为给出标签 1 有侮辱性文字 0 正常
return postingList, classVec
def creatVocabList(dataSet):
VocabSet = set([]) # 创建一个空list,并使用set的数据类型,保证字典中无重复
for word in dataSet:
VocabSet = VocabSet | set(word) # 操作符‘|’表示两个集合的并集
return list(VocabSet) # 返回list的数据类型
def setOfWords2Vec(vocabList, inputSet): #词集模型
# input为输入要对比的样本 比如postingList[0]
returnVec = [0]*len(vocabList) # 创建所有为0的向量
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1 #vocabList.index(word) 为word在vocabList中的索引值 如果在vocabList中有这个单词,相应位置设为1
else:
print("the word %s is not in VocabList" % word)
return returnVec
# 输出文档向量,向量的元素为0或者1,分别表示字典中的单词在输入文档中是否没出现还是出现。该程序运行结果:
输出字典:['problems', 'posting', 'him', 'garbage', 'my', 'love', 'dalmation', 'park', 'has', 'stupid', 'food', 'help', 'is', 'cute', 'ate', 'please', 'to', 'buying', 'dog', 'take', 'licks', 'stop', 'I', 'how', 'quit', 'not', 'worthless', 'mr', 'maybe', 'so', 'flea', 'steak'] 为list数据结构,无序。
输出的returnVec(比如第一个样本):[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0]
算法核心
伪代码
计算每个类别中的文档数目
对每篇训练文档:
对每个类别:
如果词条出现在文档中---》增加该词条的计数值
增加所有词条的计数值
对每个类别:
对每个词条:
将该词条的数目除以总词条的数目得到条件概率
返回每个类别的条件概率# 训练算法:计算概率
from numpy import *
def trainNB(trainMatrix, trainLabel): # 输入训练数据矩阵 和 训练标签
numTrainDocs = len(trainMatrix) # 训练样本个数
numWords = len(trainMatrix[0]) # 字典的长度 相当于属性个数
pAbusive = sum(trainLabel)/float(numTrainDocs ) # P(Vj) V={1,0} 含有侮辱性文档的概率,由于是二分类,另外一个 可以用1减去即可。
p0Num = zeros(numWords) # 第0类文档中每个词条出现的总数量
p1Num = zeros(numWords)
p0Denom = 0.0 # 第0类文档所有词条的数量
p1Denom = 0.0
for i in range(numTrainDocs): # 遍历所有的文档 对每篇训练文档:
if (trainLabel[i] == 1): # 对每个类别
p1Num += trainMatrix[i] # 增加该词条的计算值
p1Denom += sum(trainMatrix[i]) # 增加所有词条的计数值
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom # 对每个类别,对每个词条,计算条件概率
p0Vect = p0Num/p0Denom # 对每个元素除以该类别中的总词数,(用一个数组除以浮点数即可实现)
return p0Vect,p1Vect,pAbusive # 返回两个向量 一个概率以上两个程序进行测试
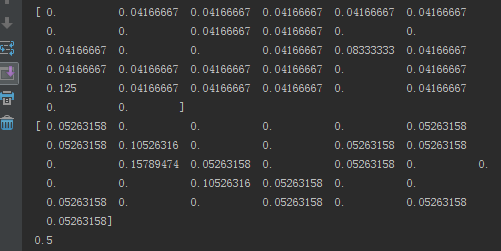
注意: 输出的连个向量与字典长度相同,里面为某一类每个元素的条件概率。最终pAb为0.5,也就说我们输入的文档侮辱性概率为一半,与我们给的标签概率一样。
修改算法:
上述代码存在一些问题:
1 贝叶斯分类器,最终是要计算多个概率
p(ai|vj)
之积,来求得最终分类的概率。如果里面有一个为0,那最终都为0, 可以通过将所有概率初始化为1,并将分母初始化为2来解决。
nc+mpn+m
这里(m=2, p=1/2)
p0Num = ones(numWords) # 第0类文档中每个词条出现的总数量
p1Num = ones(numWords)
p0Denom = 2.0 # 第0类文档所有词条的数量
p1Denom = 2.02 下溢出问题。 很多很小的数相乘,python最后会四舍五入到0., 通过取对数(ln)解决, f(x)和ln(f(x))曲线在相同区域内同增同减,并且在相同点上取得极值。
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom) #测试算法 : 朴素贝叶斯分类器
# p(v_j)*(多个P(ai|vj)相乘)
def classifyNB(Vect2classify, p0Vec, p1Vec, pAb): # 朴素贝叶斯分类器
# 输入Vect2classify 为要分类的文档,已经变为向量形式
p1 = sum(Vect2classify*p1Vec) + log(pAb) # log(ab)=log(a)+log(b)
p0 = sum(Vect2classify*p0Vec) + log(1-pAb) # 计算V_NB 括号里面的想成为对应元素相乘
if p1>p0: # 分类
return 1
else:
return 0
def testingNB():
data, label = loadDataSet()
Vocab = creatVocabList(data)
trainMat = []
for i in data:
trainMat.append(setOfWords2Vec(Vocab, i))
p0Vec, p1Vec, pAb = trainNB(trainMat, label)
test1 = ['love','my','dalmation']
test2 = ['stupid','garbage','love','dog']
testDoc1 = array(setOfWords2Vec(Vocab, test1)) # 为什么要用array数组?? 注(a)
testDoc2 = array(setOfWords2Vec(Vocab, test2))
print(test1,'classified as: ', classifyNB(testDoc1, p0Vec, p1Vec, pAb))
print(test2,'classified as: ', classifyNB(testDoc2, p0Vec, p1Vec, pAb))

注
(a) 用numpy 中的数组来计算两个向量之积,对应元素相乘。但要保证相乘的为array结构,list不能相乘。
==============================================
python 实例 过滤垃圾邮件
1 数据处理
之前,我们对数据的处理是基于某个词是否出现,这成为词集模型。但如果一个词出现的不是一次,那么词集模型不能用来描述。词袋模型就派上用场。在词袋中,每个单词可以出现多次。当遇到相同单词时,增加字典相应位置的数量。
def bagOfWords2Vec(vocabList, inputSet): #词袋模型
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1 # 增加相应位置数量
return returnVec原始邮件数据数据都是txt文档:

而非我们前面的list(词向量)形式,所有我们要经过分割达到list形式的源数据。
python string.split()
import re # re 模块
emailText = open('email/ham/1.txt').read()
pattern = re.compile(r'\W*') # 编译
list = re.split(pattern, emailText) # 分割
# [tok.lower() for tok in list if len(tok)>0] # 将所有元素变为小写
可以将上面的代码封装为函数
def textSeg(emailText): # 数据处理函数
import re # re 模块
pattern = re.compile(r'\W*') # 编译
list = re.split(pattern, emailText) # 分割
return [tok.lower() for tok in list if len(tok)>2] # 去除长度小于2的词完整代码
from numpy import *
def creatVocabList(dataSet):
def bagOfWords2Vec(vocabList, inputSet):
def trainNB(): # 上面已经解读
def classifyNB():
def textSeg(emailText):
def spamTest(): # 垃圾邮件测试
DocList = [] #
labelList = [] # 标签list
FullList = [] #
for i in range(1, 26): # 每个文件夹下25个txt文件
emailText = open('email/spam/%d.txt' % i).read()
wordList = textSeg(emailText)
DocList.append(wordList) # append extend 区别,决策树里面有详细讲解
FullList.extend(wordList)
labelList.append(1) # 人为标记
emailText = open('email/ham/%d.txt' % i).read()
wordList = textSeg(emailText)
DocList.append(wordList) # append extend 区别,决策树里面有详细讲解
FullList.extend(wordList)
labelList.append(0) # 人为标记
Vocab = creatVocabList(DocList) # 创建字典
# 随机抽取训练测试样本,总共50个样本 选取10个测试
traingSetIndex = list(range(50))
testSetIndex = []
for i in range(10):
index = int(random.uniform(0,50)) # 随机生成0-50的数
testSetIndex.append(traingSetIndex[index]) # 选出来的放入 testSetIndex
del(traingSetIndex[index]) # 还要删除traingSetIndex相应的位置索引
trainMat = []
trainLabel = []
for i in traingSetIndex:
trainMat.append(bagOfWords2Vec(Vocab, DocList[i]))
trainLabel.append(labelList[i])
p0Vec, p1Vec, pAb = trainNB(trainMat, trainLabel)
errorcount = 0
for i in testSetIndex: # 测试
test = bagOfWords2Vec(Vocab, DocList(i))
if classifyNB(test, p0Vec, p1Vec, pAb) != labelList[i]:
errorcount += 1
print('the error is: ', float(errorcount)/len(testSetIndex)) 














 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









