






上一节,我们介绍了梯度上升优化参数算法。并将Python代码和Matlab代码的写法做了分析。同时,前面我们说了梯度下降法有两种(批量和随机) 批量法前面已经有代码。本节我们将上节得到的分类结果可视化(即画出分类线(决策边界)),并且给出随机梯度法和改进的随机梯度法。最后给出一个完整的实例。
1 可视化数据:画出决策边界
前面我们通过梯度法得到最佳的回归系数:
W=[w0,w1,...wn]T
import matplotlib.pyplot as plt
def plotBestDeci(w): # 输入最佳回归系数
# 首先可视化原始数据
data, label = loadData()
m,n = shape(data)
x1 = []; y1 = [] # 记录数据 x y 坐标 方便画图
x2 = []; y2 = []
for i in range(m):
if int(label[i]) == 1:
x1.qppend(data[i, 1])
y1.append(data[i, 2])
else:
x2.append(data[i, 1])
y2.append(data[i, 2])
fig = plt.figure() #创建画布
ax = fig.add_subplot(111) # 1行1列的图
ax.scatter(x1, y1, s=30, c='red', markers='s') # scatter 散点图 s: 方块
ax.scatter(x2, y2, s=30, c='green',) # 最后一个参数 默认是 圆形
x = arange(-3.0, 3.0, 0.1) #arange()类似于内置函数range(),通过指定开始值、终值和步长创建表示等差数列的一维数组,注意得到的结果数组不包含终值
y = (-w[0]-w[1]*x)/w[2]
ax.plot(x, y.tolist()[0]) # tolist() 将矩阵转为list
plt.xlabel('X1')
plt.ylabel('Y1')
ply.show()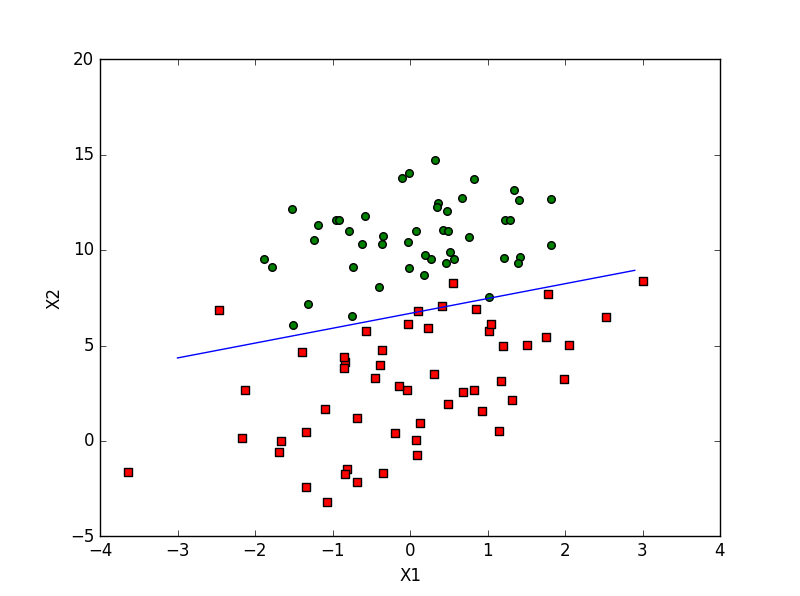
=================================================
2 随机梯度上升法
伪代码
所有回归系数初始化为1
对数据中的每个样本
计算该样本的梯度
使用alpha*gradient更新回归系数值
返回回归系数# Python 代码
from numpy import *
def R_gradientDescent(data, label):
dataMat = mat(data)
labelmat = mat(label).transpose()
m,n = shape(dataMat)
alpha = 0.01
w = ones((n,1))
for i in range(m):
h = sigmod(dataMat[i] * w)
error = labelMat[i] - h
w = w + alpha * error * dataMat[i].transpose()
return w3 改进的随机梯度算法
上述的随机梯度算法存在两个问题: alpha是固定的、 每次选取的样本是按顺序的可能会产生波动。
def Imp_gradientDescent(data, label, num_iter = 150):
#输入都为列表的形式。
# data: [[*,*....],[*,*....]....[*,*....]]
# label : [*,*,.....*]
dataMat = mat(data)
labelmat = mat(label).transpose()
m,n = shape(dataMat)
w = ones((n,1))
for j in range(num_iter):
dataIndex= list(range(m)) # 0---m 用来存储
for i in range(m):
alpha = 4/(1.0+j+i) + 0.01 # 注(a)
randIndex = int(random.uniform(0, len(dataIndex))) # 注(b)
h = sigmod(dataMat[randIndex] * w)
error = labelMat[randIndex] - h
w = w + alpha * error * dataMat[randIndex].transpose()
del(dataIndex[randIndex])
return w注
(a)alpha 动态调整,随着迭代词素增加而不断减小,但永远不会为0 (有常数项)
(b)通过随机选取样本来更新回归系数。最后要从列表中删除该值,再进行下一次迭代
(c) 该程序如果没有给出迭代次数,默认迭代次数150,
(d) dataIndex的作用 :防止某些训练样本多次进行参数优化。
=========================================
之前我们分析了回归系数的优化,但没有具体去实现分类任务,接下来从一个实例来说明。
预测某疾病导致的死亡率
原始数据 共22列,前21列为特征,最后一列为标签。
from numpy import *
def classify(x, W):
# x 为一个样本
h = sigmoid(x * W)
if h > 0.5:
return 1.0
else:
return 0.0
def mainTest():
# 先读取训练数据,标签。并转化为矩阵
frTr = open('horseColicTraining.txt')
frTe = open('horseColicTest.txt')
trainSet = []
trainLabel = []
for i in frTr.readlines():
currLine = i.strip().split()
ArrLine = [] # 中间临时变量
for j in range(21):
ArrLine.append(float(currLine[j]))
trainSet.append(ArrLine)
trainLabel.append(float(currLine[21]))
weights = Imp_gradientDescent(trainSet, trainLabel) #调用函数,得到最佳回归系数
# 测试部分
errorCount = 0.0 # 错误率
testNum = 0
for i in frTe.readlines():
testNum += 1 # 记录测试样本总数
currLine = i.strip().split()
ArrLine = [] # 中间临时变量
for j in range(21):
ArrLine.append(float(currLine[j]))
if classify(ArrLine, weights) != int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec) # 计算错误率
print ("the error rate of this test is: %f" % errorRate)
# return errorRate 
可以多次运行,求出平均值。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









