







目录
1.简介
Logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘 ,Logistic回归虽说是回归,但实际更属于判别分析。
2.应用范围
① 适用于流行病学资料的危险因素分析
② 实验室中药物的剂量-反应关系
③ 临床试验评价
④ 疾病的预后因素分析
3.分类
①按因变量的资料类型分:
二分类
多分类
其中二分较为常用
② 按研究方法分:
条 件Logistic回归
非条件Logistic回归
两者针对的资料类型不一样,前者针对配对研究,后者针对成组研究。
3.应用条件
① 独立性。各观测对象间是相互独立的;
② LogitP与自变量是线性关系;
③ 样本量。经验值是病例对照各50例以上或为自变量的5-10倍(以10倍为宜),不过随着统计技术和软件的发展,样本量较小或不能进行似然估计的情况下可采用精确logistic回归分析,此时要求分析变量不能太多,且变量分类不能太多;
④ 当队列资料进行logistic回归分析时,观察时间应该相同,否则需考虑观察时间的影响(建议用Poisson回归)。
4.原理详解
4.1 sigmod分类函数
之所以在这里介绍,是因为下面会用到这个函数
Sigmoid函数:
曲线表示:
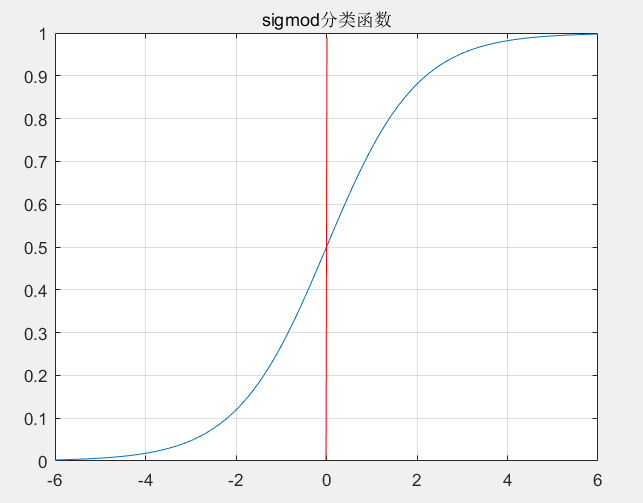
由图可见当范围为0-1,当X<0时,Y趋向于0,X>0时,Y趋向于1,适合用于0-1二分类。
所以我们就可以设分类函数如下:
其中为自变量,即特征数据。实际因变量为
,为0-1变量,
为预测值范围为0-1。显然这个模型需要求解的变量为
。
4.2 建立目标函数
对于输入变量,设
为输出为1的概率,则
为输出0的概率。则可表示成如下:
求解损失函数:用概率论中的极大似然估计的方法,构建概率函数如下,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4572
4572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









