










注意:
本文中所有的代码你可以在这里:
https://github.com/qeesung/algorithm/tree/master/chapter11/11-4/openAddressing(这里会及时更新)
或者这里:
http://download.csdn.net/detail/ii1245712564/8891141
找到
散列表之开放定址法
在前面的文章中我们介绍过《散列表之链接法》,在链接法中,如果不同键值却将有相同的映射值,即有不同键值的元素却映射到散列表中的同一位置,那么就采用链表的方法,将映射到同一位置的元素插入到同一个链表之中,当需要删除, 查询元素时,只需要遍历该链表即可,链接法在最坏情况下删除和查询元素的时间代价为 O(n)
今天我们来讲散列表中另外一种解决冲突的方法,那就是开放定址法(open addressing)。
假如你在外面旅游时,吃坏东西,急需上厕所,当你好不容易找到一件洗手间的时候,发现排了好多人,这时你会怎么做?
- 如果是链接法:排队不就行了,我就在外面等,迟早会排到我的
- 如果是开放定址法:直接放弃现有厕所,去寻找新的厕所
没错,放弃已被占用的位置,寻找新的插入位置就是开放定址法的思想,开放定址法中的开放二字指的是没有被占用的位置,定址指的是确定位置。开放定址法中,所有的元素都放在散列表中(链接法放在链表中)。也就是说散列表中的每一个位置,要么有元素,要么没有元素。当需要删除,查询元素时,我们从某一个位置开始,按照某种特定的确定下一个位置的方法来检查所有表项,直到找到目标元素,或者没有找到。
散列表的基本操作
散列表有三种最基本的操作:
- 插入元素:INSERT(ele)
- 查询元素:SEARCH(k)
- 删除元素:DELETE(ele)
下面我们给出开放定址法散列表的定义
template < class T >
class OpenAddressingTable
{
public:
typedef size_t (*Hash_Func_Type)( const T & , size_t , size_t);// [> 定义散列函数的指针 <]
/* 描述表的一个位置的状态 */
enum ELE_STATUS{
EMPTY=0,// 空的
DELETED=1,// 被删除的
FULL=2 //有元素的
};
// ==================== LIFECYCLE =======================================
OpenAddressingTable (size_t array_size ,Hash_Func_Type _hash_func=NULL) ; /** constructor */
~OpenAddressingTable () ; /** destructor */
/** ==================== MUTATORS ======================================= */
bool hash_insert(const T & t) ; /* 向散列表中插入新的元素 */
bool hash_search(const T & t , T & target) const ; /* 在散列表中查找键值 */
bool hash_delete(const T & t) ; /* 在散列表中删除键值对应的元素 */
void hash_clear();
private:
/** ==================== DATA MEMBERS ======================================= */
T * array_ptr ; /* 散列表的数组指针 */
const size_t array_size ; /* 散列表数组的大小 */
ELE_STATUS * status_array_ptr ; /* 用于存放各个位置的状态信息*/
Hash_Func_Type HASH ; /* 采用的散列函数,这个函数用户也可以自己指定 */
}; /** ----- end of template class OpenAddressingTable ----- */
#include "open_addressing.cc"
#endif /* ----- #ifndef OPEN_ADDRESSING_INC ----- */插入操作_INSERT
只要我们找到的位置没有元素在里面,那么表示这个位置可以插入新的元素
/**
* 插入一个元素
* @param t 要插入的元素
*/
template < class T >
bool OpenAddressingTable<T>::hash_insert (const T & t)
{
size_t i = 0;
while(i!= array_size)
{
size_t j = HASH(t , i , array_size); // 取出位置
if(status_array_ptr[j] != FULL) // 判别元素是否是开放为空的
{
array_ptr[j] = t; //插入元素
status_array_ptr[j] = FULL;//并将该位置状态设为已经被插入
return true;
}
++i;
}
std::cerr<<"hash table overflow"<<std::endl;
return false;
} /** ----- end of method OpenAddressingTable<T>::hash_insert ----- */查找操作_SEARCH
查找操作和插入操作比较类似,查找操作是要找到有非空位置,并判断是否是目标元素,当遇到为EMPTY的时候,说明之后元素也不必再检查,因为后面已经没有元素了
/*
* 查找元素
* @param t 要查找的键值
* @param target 返回找到的目标
*/
template < class T >
bool OpenAddressingTable<T>::hash_search (const T & t , T & target) const
{
size_t i = 0;
while(i != array_size)
{
size_t j = HASH(t , i , array_size) ;
if(status_array_ptr[j] == EMPTY) // 之后就再也没有元素了
return false;
else if (status_array_ptr[j] == FULL)
{
if(array_ptr[j].key == t.key )
{
target = array_ptr[j];
return true;
}
}
++i;
}
target = T();
return false;
} /** ----- end of method OpenAddressingTable<T>::hash_search ----- */删除操作_DELETE
删除操作和上面两个操作也比较相似,但是有一点需要注意,那就是已删除元素的散列表位置不能标记为EMPTY,而是要标记为DELETED,因为在查找操作中是以EMPTY作为探查的终止,如果标记为EMPTY,那么在被删元素之后的那些元素就会丢失
template < class T >
bool OpenAddressingTable<T>::hash_delete (const T & t)
{
size_t i = 0;
while(i !=array_size)
{
size_t j = HASH(t , i , array_size);
if(status_array_ptr[j] == EMPTY)
return false;
else if (status_array_ptr[j] == FULL)
{
if(array_ptr[j].key == t.key )
{
status_array_ptr[j] = DELETED;// 不应该是EMPTY
return true;
}
}
++i;
}
return false;
} /** ----- end of method OpenAddresingTable<T>::hash_delete ----- */散列表的探查方法(probe methods)
上文提到,我们从某一个位置开始,按照某种特定的确定下一个位置的方法来检查所有表项,而这种特定的确定下一个位置的方法就是我们这里的探查方法。
在进入正题前,我们首先来看两个问题:
问题一:为什么需要探查?
回答一:前面我们讲过,开放定址法在一个位置被占用时,就会去寻找下一个新的位置,那这个找的方法也不是乱找。那么就需要按照一定的查找规律去一个一个的探查。
问题二:什么样的探查才算是一个好的探查?
回答二:一个好的探查一定是可以等可能的探查散列表中的所有表项的,每个关键字的探查序列等可能的为 <0,1,2,...,m−1> <script type="math/tex" id="MathJax-Element-2"><0,1,2,...,m-1></script>的 m! 种排列中的一种。但是这种探查只是理想化的,我们只能做到尽可能的趋近。
散列表探查的定义
为了使用开放定址法插入一个元素,需要连续的检查散列表,直到找到一个新的空槽来放置带插入的元素为止。检查的顺序不一定是0,1,2,…,m-1的这种顺序,而是要依赖待插入的关键字key,为了确定探查哪些槽,我们将散列函数加以扩充,使之包含探查号作为第二个输入参数,于是散列函数就定义为:
对于每一个关键字 k ,使用开放定址法得到的探查序列
在下面我们将介绍三种探查的方法,这三种探查的方法都能保证每一个关键字的探查序列都是 {0,1,2,3,...,m−1} 的一个排序,但是并不能做到等可能的为 {0,1,2,3,...,m−1}m! 排列中的一个。
线性探查
给定一个辅助散列函数
_h:U→{0,1,2,...,m−1}
,那么线性探查的散列函数为:
首先我们探查
HashTable[_h(k)] modm
位置,如果发现已经被占用,那么就探查
HashTable[_h(k)+1] modm
,如果也被占用了,那么就探查
HashTable[_h(k)+2] modm
,以此类推,直到找到合适的位置,或者探查了
m
次以后到位置
/**
* 辅助散列函数
* @param t 要插入的元素
* @param array_size 散列表的大小
*/
template < class T >
size_t _hash (const T & t , size_t array_size)
{
return t.key%array_size;
} /** ----- end of method OpenAddressingTable<T>::_hash ----- */
/**
* 线性探查
* @param t 要插入的元素
* @param offset 探查号
* @param array_size 散列表大小
*/
template < class T >
size_t linear_probing (const T & t, size_t offset , size_t array_size)
{
return (_hash(t , array_size)+offset)%array_size;
} /** ----- end of method OpenAddresingTable<T>::linear_probing ----- */举个栗子:
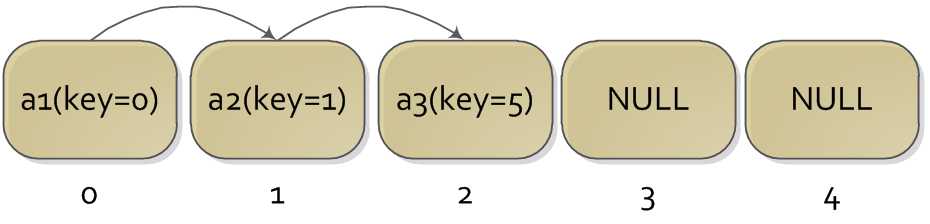
假设现在有大小为 5 的散列表,现在要插入三个元素{a1(key=0),a2(key=1),a3(key=5)} 到散列表中
插入 a1 , h(0,0)=0 ,位置 0 为空,可以直接插入
插入
a2 , h(1,0)=1 ,位置 1 为空,可以直接插入
插入
a3 ,首先探查好 h(5,0)=0 ,发现位置 0 已有元素,那么接下来探查h(5,1)=1 ,发现位置 1 也有元素了,于是继续探查h(5,2)=2 , 2 位置为空,可以插入


可能你也发现上面的问题了,如果我们要查找
二次探查
二次探查相对于线性探查来说,在散列函数中添加了一个二次项:
其中 h 是一个辅助散列函数, c1 , c2 为正常的辅助常数,初始的探查位置是 _h(k) modm 虽然 二次探查不存在像 线性探查哪样的严重群集,但是还是存在一定的群集现象,该群集现象称为 二次群集
/**
* 二次探查
*/
template < class T >
size_t quadratic_probing (const T & t , size_t offset , size_t array_size)
{
return (_hash(t , array_size)+offset*offset)%array_size;
} /** ----- end of method OpenAddressingTable<T>::quadratic_probing ----- */
双重散列
双重散列是用于开放定址法的最好的探查方法之一,因为双重散列对于任何一个键值来说,得到的探查序列都是足够随机的,双重散列采用下面的散列函数:
其中 h1 和 h2 分别是两个辅助散列函数,起始的散列表项为 h1(k) modm
有一个散列函数就已经够头疼的了,现在还多了一个新的辅助散列函数,为了能查找整个散列表,值
h2(k)
必须要与散列表的大小
m
互素。有一种简便的方法可以保证这个条件成立,就是取
比如在我们去 m 为一素数的时候,我们可以讲散列函数设计如下
/**
* 双重散列的第二个辅助函数
*/
template < class T >
size_t _hash1 (const T & t , size_t array_size)
{
return (1+t.key%(array_size-1));
} /** ----- end of method OpenAddressingTable<T>::_hash1 ----- */
/**
* 双重散列
*/
template < class T >
size_t double_hashing (const T & t , size_t offset , size_t array_size)
{
return (_hash(t , array_size)+offset*_hash1(t , array_size))%array_size ;
} /** ----- end of method OpenAddressingTable<T>::double_hash ----- */总结
开放定址法的所有元素都存在于散列表之内,每一个表项要么存在元素,要么就为空,当发生映射值冲突的时候我们可以探查新的位置。最好的探查方法是双重散列,因为双重散列产生的探查序列足够随机,不像线性探查和二次探查哪样存在较为严重的群集现象。
开放定址法相对于链接法来说,可以将存储链表指针的内存空出来存储更多的数据,直接跳过了指针的操作,而是用数组的直接访问来访问元素,但是如果探查散列函数设计差劲的话,将会严重拖慢散列表的速度!















 4523
4523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









