






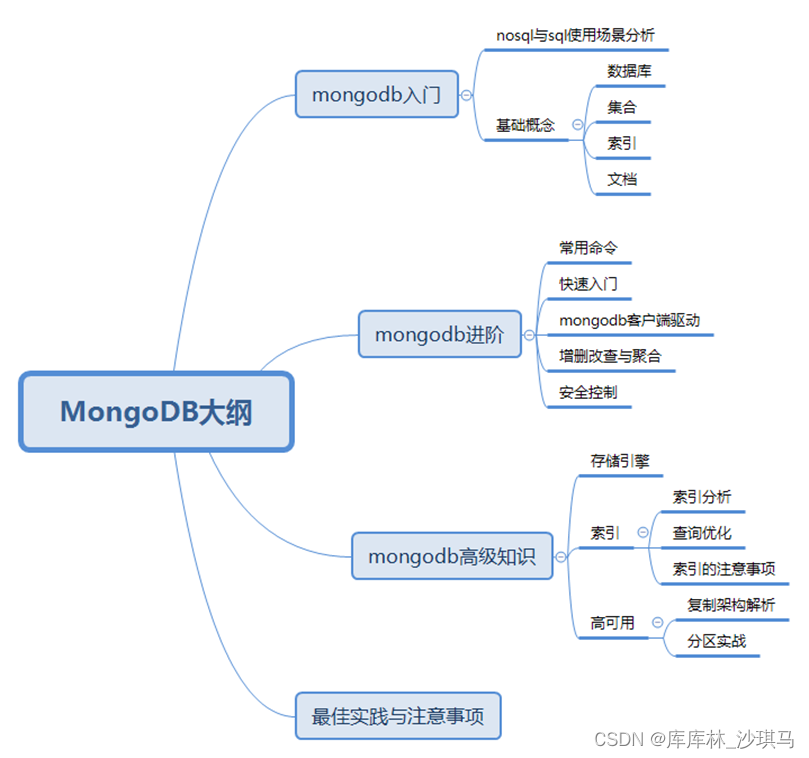
课程述概
 什么是Nosql
什么是Nosql
NoSQL:Not Only SQL ,本质也是一种数据库的技术,相对于传统数据库技术,它不会遵循一些约束,比如:sql标准、ACID属性,表结构等。
Nosql优点
- 满足对数据库的高并发读写
- 对海量数据的高效存储和访问
- 对数据库高扩展性和高可用性
- 灵活的数据结构,满足数据结构不固定的场景
Nosql缺点
- 一般不支持事务
- 实现复杂SQL查询比较复杂
- 运维人员数据维护门槛较高
- 目前不是主流的数据库技术
NoSql分类
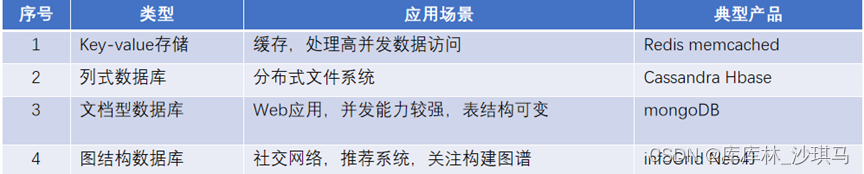
数据库流行程度排行
什么是MongoDB?
MongoDB是一个基于分布式文件存储的NoSQL数据库,由C++语言编写,旨在为高性能、高可扩展性的应用提供存储支持。MongoDB将数据存储在一个类似JSON的二进制格式BSON中,这使得它非常灵活和高效。
特性
- 面向集合文档的存储:适合存储Bson(json的扩展)形式的数据;
- 格式自由,数据格式不固定,生产环境下修改结构都可以不影响程序运行;
- 强大的查询语句,面向对象的查询语言,基本覆盖sql语言所有能力;
- 完整的索引支持,支持查询计划;
- 支持复制和自动故障转移;
- 支持二进制数据及大型对象(文件)的高效存储;
- 使用分片集群提升系统扩展性;
- 使用内存映射存储引擎,把磁盘的IO操作转换成为内存的操作;
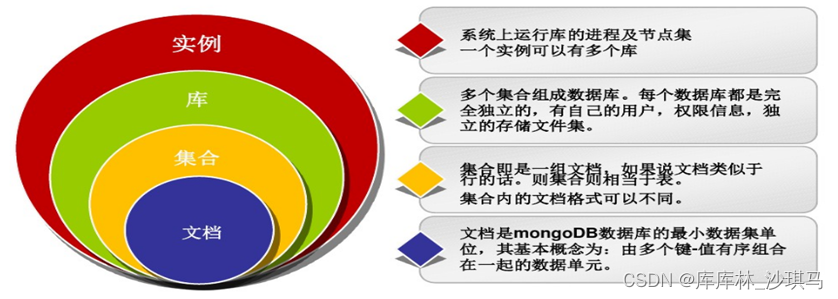
MongoDB基本概念
应不应该用MongoDB?
并没有某个业务场景必须要使用 MongoDB才能解决,但使用 MongoDB 通常能让你以更低的成本解决问题(包括学习、开发、运维等成本)
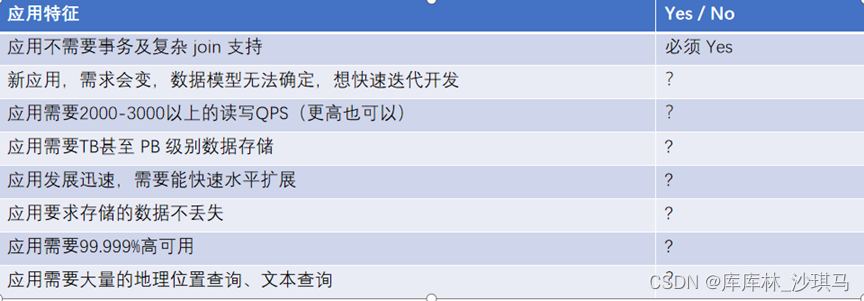
如果上述有1个 Yes,可以考虑 MongoDB,2个及以上的 Yes,选择MongoDB绝不会后悔!
MongoDB使用场景
MongoDB 的应用已经渗透到各个领域,比如游戏、物流、电商、内容管理、社交、物联网、视频直播等,以下是几个实际的应用案例:
- 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新
- 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
- 社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能
- 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
- 视频直播,使用 MongoDB 存储用户信息、礼物信息等
- ......
不使用MongoDB的场景
- 高度事务性系统:例如银行、财务等系统。MongoDB对事物的支持较弱;
- 传统的商业智能应用:特定问题的数据分析,多数据实体关联,涉及到复杂的、高度优化的查询方式;
- 使用sql方便的时候;数据结构相对固定,使用sql进行查询统计更加便利的时候;
启动MongoDB服务
Windows和macOS:
mongod --dbpath <your_db_path>
Linux:
sudo service mongod start
连接到MongoDB:
mongo
基本操作
创建数据库
use testDatabase
插入文档
db.testCollection.insertOne({ name: "Alice", age: 25 })
- users是一个未创建的文档
db.users.insertOne({name:"沙琪马"})
- 插入多条数据到集合中
db.users.insertMany([{name:"李四"},{name:"王五"}])
查询文档
db.testCollection.find({ name: "Alice" })
-
限制查询返回结果数量
db.testCollection.find().limit(要返回的数量)
例如,返回一条数据
db.users.find().limit(1)
-
排序查询
db.testCollection.find().sort({level: 1})
注意:1代表升序,-1代表降序
当然也可以按照多个字段进行排序
db.testCollection.find().sort({level: 1, name: -1})
-
条件查询
db.users.find({level:3})
这个代表查询 level为3的数据
注意:Mongodb的数据类型是非常严格的,传入的数据类型如果错误,这不会返回任何数据
-
限制字段
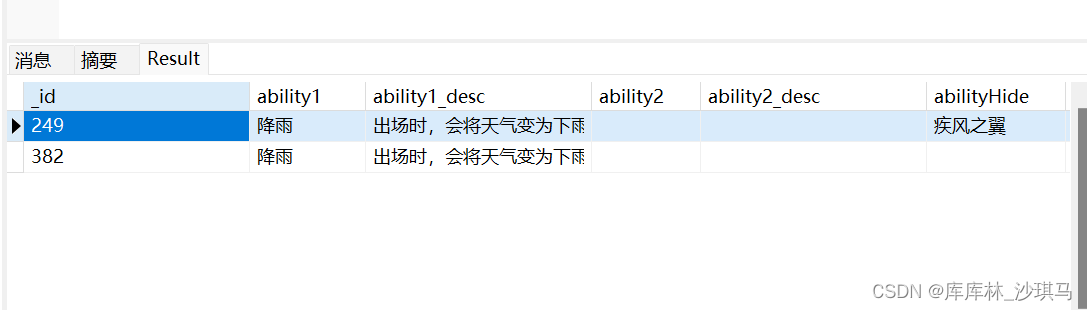
db.pokemon.find({ability1: '降雨'},{name:1,stat:1})
解释:
find()内第一个{}是查询条件,第二个{}是显示的字段,
默认会显示_id字段,可以加上_id:-1就不会返回_id字段
当然也可以排除某个字段:
db.pokemon.find({ability1: '降雨'},{name:0})
-
比较运算符
大于
db.users.find({level:{$gt: 3}})
小于
db.users.find({level:{$lt: 3}})
$in 查询level为1或者3的数据
db.users.find({level:{$in: [1,3]}})
$nin() 查询level1和3以外的数据
db.users.find({level:{$nin: [1,3]}})
-
逻辑运算符号
1 $exists 查询某个字段是否存在
db.users.find({email: {$exists: true}})
true也可以换为1
false也可以换为0
注意:exists是判断字段是否存在,数据即便为null也是可以返回的
2 and Mongodb会默认把两个条件and起来
db.users.find({level:{$gte: 3, $lte: 5}})
当然可以自己指定
db.users.find({$and: [{level:{$gte:3},{level:{$lte: 5}}}]})
3 or 同上
db.users.find({$or: [{level:{$gte:3},{level:{$lte: 5}}}]})
4 not 运算符
db.users.find({level: {$not: {$eq: 3}}})
5 正则表达式
db.users.find({name: {$regex: /张/ }})
-
聚合/统计
1 countDocuments 统计文档数量
db.users.countDocuments()
当然也可以带有查询条件
db.users.countDocuments({level: {$gte: 3}})
2 findOne() 返回第一条数据
db.users.findOne({level: {$gte: 3}})
更新文档
- 更新一条数据
db.testCollection.updateOne({ name: "Alice" }, { $set: { age: 26 } })
- 更新多条数据
db.testCollection.updateMany({ age: 22 }, { $set: { age: 26 } })
查找年龄为22岁的,改为26岁
删除文档
db.testCollection.deleteOne({ name: "Alice" })
高级功能
聚合操作
db.testCollection.aggregate([ { $match: { age: { $gt: 20 } } }, { $group: { _id: "$age", total: { $sum: 1 } } } ])
索引
db.testCollection.createIndex({ name: 1 })
常见命令
- 查看当前数据库:
- db
- 查看所有数据库:
- show dbs
- 查看当前数据库中的集合:
- show collections
备份与恢复
备份数据库
mongodump --db testDatabase --out /path/to/backup
恢复数据库
mongorestore --db testDatabase /path/to/backup/testDatabase
docker 部署 mongodb 集群
1、基本信息如下
副本集名称 rs
容器节点及端口映射
m0 37017:27017
m1 47017:27017
m2 57017:27017
注:机器环境安装docker
2、部署步骤
2.1、下载mongo镜像
docker pull mongo
2.2、启动三个节点
docker run --name m0 -p 37017:27017 -d mongo --replSet "rs"
docker run --name m1 -p 47017:27017 -d mongo --replSet "rs"
docker run --name m2 -p 57017:27017 -d mongo --replSet "rs"
--replSet "rs"如果不集群,就不要添加这个,添加了访问不了。
2.3、连接任意一个节点,进行副本集配置
- 进入其中一个容器
随便进入一个即可,没有要求。也并不是说进入这个就是住节点。
docker exec -it m0 /bin/bash
- 连接三个节点中的任意一个,注意
ip地址为宿主机ip.
好像链接的这个节点就是主节点了
mongo --host 你的ip --port 37017
此时已连接到m0节点,进行副本集配置。我们值在m0这台mongodb中配置就可以了,其他两个副本不需要配置的。
var config={
_id:"rs",
members:[
{_id:0,host:"www.it307.top:37017"},
{_id:1,host:"www.it307.top:47017"},
{_id:2,host:"www.it307.top:57017"}
]};
rs.initiate(config)
响应应该类似下面,注意此时命令提示符已经发生变化,由原来的 > 变成了rs:SECONDARY>
2.4、查看副本集配置信息
rs.conf()
2.5、查看副本集状态
rs.status()
这样就搭建完成了。
3、测试
有空再说吧
docker快速搭建mongodb的分片集群
Docker 确实能够用于创建和部署 MongoDB 集群,而且可以部署进行分片存储和选举机制。以下是一种简化的方式来实现这个需求,通过使用 Docker Compose 来配置 MongoDB 分片集群,其中主节点将由集群选举产生。
在Ubuntu系统上利用Docker容器创建一个具有分片存储机制的MongoDB集群,并且主节点不固定(即高可用的配置),我们需要完成以下几个步骤:
1. 安装Docker和Docker Compose
首先,确保Ubuntu系统中已经安装了Docker和Docker Compose。
# 更新软件包索引
sudo apt-get update
# 安装Docker
sudo apt-get install -y docker.io
# 启动Docker服务
sudo systemctl start docker
# 让Docker服务开机启动
sudo systemctl enable docker
# 安装Docker Compose
sudo apt-get install -y curl
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 授予Docker Compose执行权限
sudo chmod +x /usr/local/bin/docker-compose
# 验证Docker Compose安装
docker-compose --version2. 配置和启动MongoDB分片集群
接下来创建一个Docker Compose文件来配置和启动MongoDB分片集群。新建一个目录并在目录中创建Docker Compose文件。
mkdir mongodb-sharded-cluster
cd mongodb-sharded-cluster
nano docker-compose.yml在docker-compose.yml文件中,包含以下内容:
version: '3.8'
services:
configsvr1:
image: mongo:latest
container_name: configsvr1
command: --replSet configReplSet --port 27017 --configsvr --bind_ip_all
ports:
- 27017:27017
volumes:
- configsvr1-data:/data/db
configsvr2:
image: mongo:latest
container_name: configsvr2
command: --replSet configReplSet --port 27018 --configsvr --bind_ip_all
ports:
- 27018:27018
volumes:
- configsvr2-data:/data/db
configsvr3:
image: mongo:latest
container_name: configsvr3
command: --replSet configReplSet --port 27019 --configsvr --bind_ip_all
ports:
- 27019:27019
volumes:
- configsvr3-data:/data/db
shard1:
image: mongo:latest
container_name: shard1
command: --replSet shard1ReplSet --port 27020 --shardsvr --bind_ip_all
ports:
- 27020:27020
volumes:
- shard1-data:/data/db
shard2:
image: mongo:latest
container_name: shard2
command: --replSet shard2ReplSet --port 27021 --shardsvr --bind_ip_all
ports:
- 27021:27021
volumes:
- shard2-data:/data/db
shard3:
image: mongo:latest
container_name: shard3
command: --replSet shard3ReplSet --port 27022 --shardsvr --bind_ip_all
ports:
- 27022:27022
volumes:
- shard3-data:/data/db
mongos:
image: mongo:latest
container_name: mongos
command: >
sh -c '
sleep 10;
mongo --eval "sh.addShard(\"shard1ReplSet/shard1:27020\")";
mongo --eval "sh.addShard(\"shard2ReplSet/shard2:27021\")";
mongo --eval "sh.addShard(\"shard3ReplSet/shard3:27022\")";
mongo --eval "sh.enableSharding(\"mydatabase\")";
mongos --configdb configReplSet/configsvr1:27017,configsvr2:27018,configsvr3:27019 --bind_ip_all
'
depends_on:
- configsvr1
- configsvr2
- configsvr3
- shard1
- shard2
- shard3
ports:
- 27023:27017
volumes:
configsvr1-data:
configsvr2-data:
configsvr3-data:
shard1-data:
shard2-data:
shard3-data:3. 初始化配置服务器和分片服务器的副本集
我们需要手动到每个节点容器去初始化副本集。
先启动容器:
docker-compose up -d初始化配置服务器副本集:
docker exec -it configsvr1 mongo --port 27017 --eval 'rs.initiate({_id: "configReplSet", configsvr: true, members: [{_id: 0, host: "configsvr1:27017"}, {_id: 1, host: "configsvr2:27018"}, {_id: 2, host: "configsvr3:27019"}]})'初始化分片服务器的副本集 (分别为每个分片执行如下命令)::
docker exec -it shard1 mongo --port 27020 --eval 'rs.initiate({_id: "shard1ReplSet", members: [{_id: 0, host: "shard1:27020"}]})'
docker exec -it shard2 mongo --port 27021 --eval 'rs.initiate({_id: "shard2ReplSet", members: [{_id: 0, host: "shard2:27021"}]})'
docker exec -it shard3 mongo --port 27022 --eval 'rs.initiate({_id: "shard3ReplSet", members: [{_id: 0, host: "shard3:27022"}]})'4. 添加分片到集群
在mongos(路由器)上添加分片:
docker exec -it mongos mongo --port 27017添加每个分片:
在 mongo shell 中,执行以下命令:
sh.addShard("shard1ReplSet/shard1:27020");
sh.addShard("shard2ReplSet/shard2:27021");
sh.addShard("shard3ReplSet/shard3:27022");5. 测试和验证集群
连接到mongos端点然后验证分片:
docker exec -it mongos mongo --port 27017
# 查看分片状态
sh.status()通过以上命令应该看到关于集群的详细信息,包括配置信息和分片信息。
至此,你应该已经成功搭建起一个高可用的MongoDB分片集群。可以进一步在cluster上进行测试,插入数据并从多个节点读取数据,以验证集群的正确性和健壮性。
验证集群配置的终极步骤
-
插入和查找数据
验证集群正常工作,可以使用实际的数据库操作,例如创建数据库和集合、插入数据和查询数据:
首先,确保你连接到 mongos 实例:
docker exec -it mongos mongo --port 27017
// 创建集合
use myk
启用数据库分片
你需要为目标数据库启用分片:
sh.enableSharding("myk") // 你要有这个数据库
然后在该数据库中创建集合并进行分片。例如,使用 _id 作为分片键:
db.createCollection("testcollection")
// 分片集合,使用 _id 作为分片键
sh.shardCollection("myk.testcollection", { "_id": "hashed" })
// 插入数据
for (let i = 0; i < 1000; i++) { db.testcollection.insert({name: "doc" + i, value: i}) }
// 检查数据的分布
db.testcollection.getShardDistribution()














 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









