






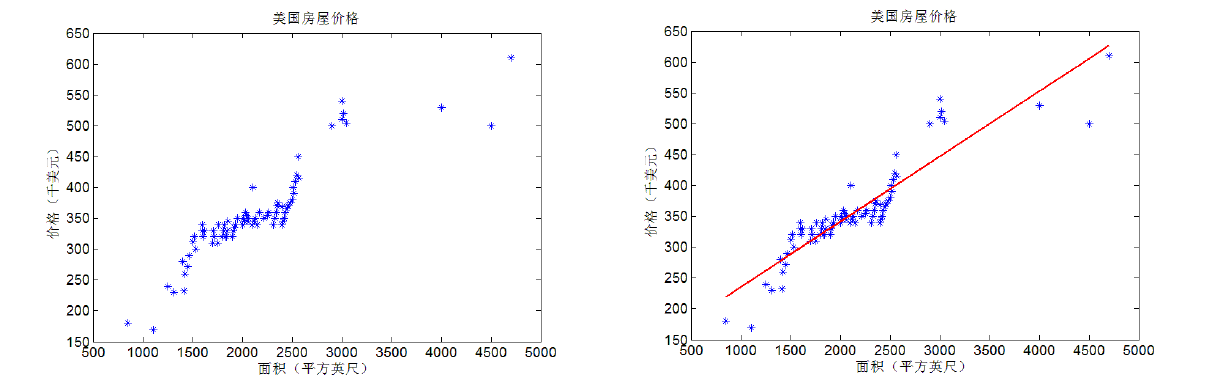
回归的理解
回归其实就是对已知公式的未知参数进行估计(梯度下降,迭代思想,最小二乘也通可通过这种方法求解)。大家可以简单的理解为,在给定训练样本点和已知的公式后,对于一个或多个未知参数,机器会自动枚举参数的所有 可能取值(对于多个参数要枚举它们的不同组合),直到找到那个最符合样本点分布的参数(或参数组合)。(当然,实际运算有一些优化算法,肯定不会去枚举 的)。注意,回归的前提是公式已知,否则回归无法进行。而现实生活中哪里有已知的公式啊(G=m*g 也是牛顿被苹果砸了脑袋之后碰巧想出来的不是?哈哈),因此回归中的公式基本都是数据分析人员通过看大量数据后猜测的(其实大多数是拍脑袋想出来的, 嗯…)。根据这些公式的不同,回归分为线性回归和非线性回归。线性回归中公式都是“一次”的(一元一次方程,二元一次方程…),而非线性则可以有 各种形式(N元N次方程,log方程 等等)。
数学模型
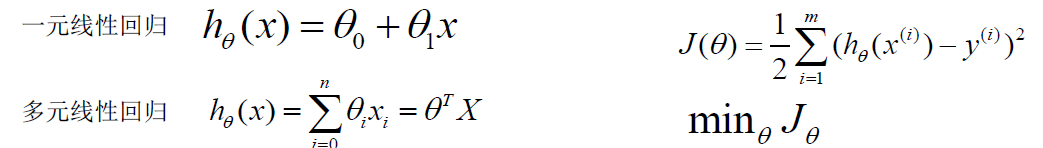
批量梯度下降算法
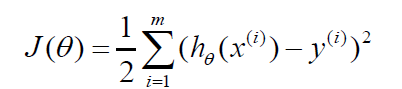
J(θ)的极小值问题-> 梯度下降法:
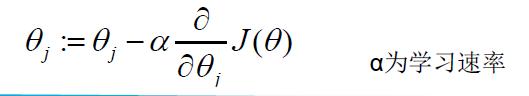
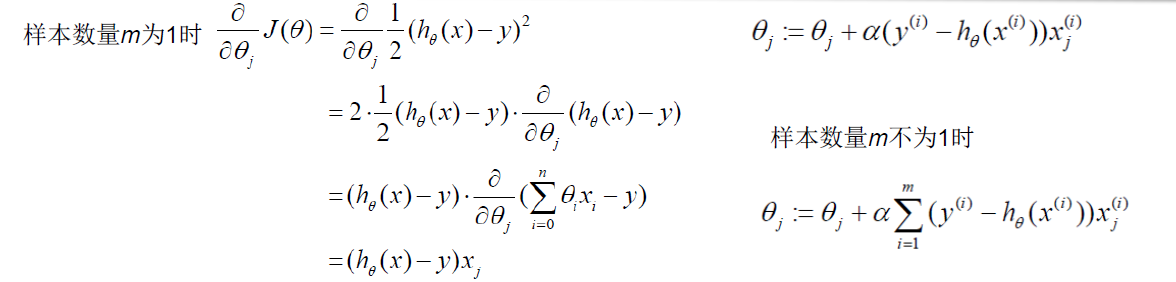
随机梯度下降算法
当样本集数据量m很大时,批量梯度下降算法每迭代一次的复杂度为O(mn),复杂度很高。
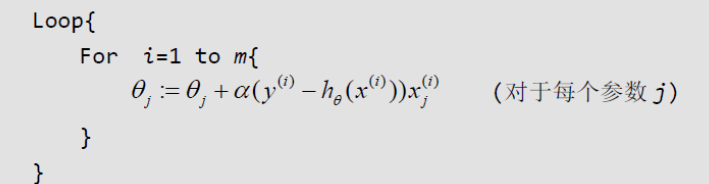
即每读取一条样本,就迭代对 进行更新,这样迭代一次的算法复杂度为O(n)。
源码分析
MLlib的线性回归模型采用随机梯度下降算法来优化目标函数,MLlib实现了分布式的随机梯度下降算法,其分布方法是:在每次迭代中,随机抽取一定比例的样本作为当前迭代的计算样本;对计算样本中的每一个样本分别计算梯度(分布式计算每个样本的梯度);然后再通过聚合函数对样本的梯度进行累加,得到该样本的平均梯度及损失;最后根据最新的梯度及上次迭代的权重进行权重的更新。

LinearRegressionWithSGD //**线性回归伴生对象** LinearRegressionWithSGD是基于随机梯度下降的线性回归的伴生对象
train //train是LinearRegressionWithSGD对象的静态方法,该方法是根据设置线性回归参数 新建线性回归类,并执行run方法进行训练
LinearRegressionWithSGD //LinearRegressionWithSGD类
run //un是LinearRegressionWithSGD线性回归类继承GeneralizedLinearAlgorithm广义线性回归类的run方法,该方法主要用optimizer.optimize方法进行权重的优化计算。
runMiniBatchSGD // **权重优化计算**GradientDescent类继承了optimizer,GradientDescent类的optimizer方法其实是调用了GradientDescent伴生对象的runMiniBatchSGD方法 ,runMiniBatchSGD方法是根据训练样本迭代运行随机梯度计算,得到最优权重;每次迭代主要计算样本的梯度及更新梯度。
gradient.compute //**梯度计算**调用LeastSquaresGradient.compute方法,该方法是计算样本的梯度
updater.compute //**权重更新**调用SimpleUpdater.compute方法,该方法是权重的更新方法
LinearRegressionModel //线性回归模型
predict //GeneralizedLinearModel类predict方法,该方法是根据线性回归模型计算样本的预测值object LinearRegressionWithSGD {
def train(
input: RDD[LabeledPoint], //训练样本
numIterations: Int, //迭代次数
stepSize: Double, //每次迭代步长
miniBatchFraction: Double, //每次参与计算的样本比例
initialWeights: Vector //初始化权重
): LinearRegressionModel = {
new LinearRegressionWithSGD(stepSize, numIterations, 0.0, miniBatchFraction)
.run(input, initialWeights)
}
}class LinearRegressionWithSGD private[mllib] (
private var stepSize: Double,
private var numIterations: Int,
private var regParam: Double,
private var miniBatchFraction: Double)
extends GeneralizedLinearAlgorithm[LinearRegressionModel] with Serializable {
//采用最小平方损失函数的梯度下降方法用于线性回归
private val gradient = new LeastSquaresGradient()
//采用简单梯度更新方法,无正则化
private val updater = new SimpleUpdater()
//根据梯度下降方法、梯度更新方法新建梯度优化计算方法
@Since("0.8.0")
override val optimizer = new GradientDescent(gradient, updater)
.setStepSize(stepSize)
.setNumIterations(numIterations)
.setRegParam(regParam)
.setMiniBatchFraction(miniBatchFraction)GeneralizedLinearAlgorithm类:
//特征维度
if (numFeatures < 0) {
numFeatures = input.map(_.features.size).first()
}
//输入样本检测
if (input.getStorageLevel == StorageLevel.NONE) {
logWarning("The input data is not directly cached, which may hurt performance if its"
+ " parent RDDs are also uncached.")
}
//输入样本检测
// Check the data properties before running the optimizer
if (validateData && !validators.forall(func => func(input))) {
throw new SparkException("Input validation failed.")
}
。。。。。。。。。。。。。。。。。。。。。。。。
val initialWeightsWithIntercept = if (addIntercept && numOfLinearPredictor == 1) {
appendBias(initialWeights)
} else {
/** If `numOfLinearPredictor > 1`, initialWeights already contains intercepts. */
initialWeights
}
val weightsWithIntercept = optimizer.optimize(data, initialWeightsWithIntercept)
val intercept = if (addIntercept && numOfLinearPredictor == 1) {
weightsWithIntercept(weightsWithIntercept.size - 1)
} else {
0.0
}def runMiniBatchSGD(
data: RDD[(Double, Vector)],
gradient: Gradient,
updater: Updater,
stepSize: Double,
numIterations: Int,
regParam: Double,
miniBatchFraction: Double,
initialWeights: Vector,
convergenceTol: Double): (Vector, Array[Double]) = {
//核心部分:迭代直至收敛
while (!converged && i <= numIterations) {
val bcWeights = data.context.broadcast(weights)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + l, c._3 + 1)
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
if (miniBatchSize > 0) {
/**
* lossSum is computed using the weights from the previous iteration
* and regVal is the regularization value computed in the previous iteration as well.
*/
stochasticLossHistory += lossSum / miniBatchSize + regVal
val update = updater.compute(
weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble),
stepSize, i, regParam)
weights = update._1
regVal = update._2
previousWeights = currentWeights
currentWeights = Some(weights)
if (previousWeights != None && currentWeights != None) {
converged = isConverged(previousWeights.get,
currentWeights.get, convergenceTol)
}
} else {
logWarning(s"Iteration ($i/$numIterations). The size of sampled batch is zero")
}
i += 1
}
}核心:给定一组初始权重向量,梯度下降迭代直至收敛,得到收敛函数,就是我们的拟合函数。
以上步骤得到线性回归模型。
class LinearRegressionModel @Since("1.1.0") (
@Since("1.0.0") override val weights: Vector, //(a1,a2,...an)
@Since("0.8.0") override val intercept: Double)//偏置值,a0
extends GeneralizedLinearModel(weights, intercept) with RegressionModel with Serializable
with Saveable with PMMLExportable得到模型之后,我们要进行预测:
def predict(testData: RDD[Vector]): RDD[Double] = {
// A small optimization to avoid serializing the entire model. Only the weightsMatrix
// and intercept is needed.
val localWeights = weights //权重
val bcWeights = testData.context.broadcast(localWeights) //对常量进行广播
val localIntercept = intercept //偏置
//对每行数据进行预测
testData.mapPartitions { iter =>
val w = bcWeights.value
iter.map(v => predictPoint(v, w, localIntercept))
}
}//Y = w*X + b
override protected def predictPoint(
dataMatrix: Vector,
weightMatrix: Vector,
intercept: Double): Double = {
weightMatrix.asBreeze.dot(dataMatrix.asBreeze) + intercept
}实例:
def validatePrediction(predictions: Seq[Double], input: Seq[LabeledPoint]) {
val numOffPredictions = predictions.zip(input).count { case (prediction, expected) =>
// A prediction is off if the prediction is more than 0.5 away from expected value.
math.abs(prediction - expected.label) > 0.5
}
// At least 80% of the predictions should be on.
assert(numOffPredictions < input.length / 5)
}
// Test if we can correctly learn Y = 10*X1 + 10*X2
test("linear regression without intercept") {
val testRDD = sc.parallelize(LinearDataGenerator.generateLinearInput(
0.0, Array(10.0, 10.0), 100, 42), 2).cache()
val linReg = new LinearRegressionWithSGD().setIntercept(false)
linReg.optimizer.setNumIterations(1000).setStepSize(1.0)
val model = linReg.run(testRDD)
assert(model.intercept === 0.0)
val weights = model.weights
assert(weights.size === 2)
assert(weights(0) >= 9.0 && weights(0) <= 11.0)
assert(weights(1) >= 9.0 && weights(1) <= 11.0)
val validationData = LinearDataGenerator.generateLinearInput(
0.0, Array(10.0, 10.0), 100, 17)
val validationRDD = sc.parallelize(validationData, 2).cache()
// Test prediction on RDD.
validatePrediction(model.predict(validationRDD.map(_.features)).collect(), validationData)
// Test prediction on Array.
validatePrediction(validationData.map(row => model.predict(row.features)), validationData)
}
// Test if we can correctly learn Y = 3 + 10*X1 + 10*X2
test("linear regression") {
val testRDD = sc.parallelize(LinearDataGenerator.generateLinearInput(
3.0, Array(10.0, 10.0), 100, 42), 2).cache()
val linReg = new LinearRegressionWithSGD().setIntercept(true)
linReg.optimizer.setNumIterations(1000).setStepSize(1.0)
val model = linReg.run(testRDD)
assert(model.intercept >= 2.5 && model.intercept <= 3.5)
val weights = model.weights
assert(weights.size === 2)
assert(weights(0) >= 9.0 && weights(0) <= 11.0)
assert(weights(1) >= 9.0 && weights(1) <= 11.0)
val validationData = LinearDataGenerator.generateLinearInput(
3.0, Array(10.0, 10.0), 100, 17)
val validationRDD = sc.parallelize(validationData, 2).cache()
// Test prediction on RDD.
validatePrediction(model.predict(validationRDD.map(_.features)).collect(), validationData)
// Test prediction on Array.
validatePrediction(validationData.map(row => model.predict(row.features)), validationData)
}
test("model save/load") {
val model = LinearRegressionSuite.model
val tempDir = Utils.createTempDir()
val path = tempDir.toURI.toString
// Save model, load it back, and compare.
try {
model.save(sc, path)
val sameModel = LinearRegressionModel.load(sc, path)
assert(model.weights == sameModel.weights)
assert(model.intercept == sameModel.intercept)
} finally {
Utils.deleteRecursively(tempDir)
}
}















 5623
5623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









