






逻辑回归
import org.apache.spark.ml.classification.LogisticRegression
// Load training data
val training = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// Fit the model
val lrModel = lr.fit(training)
// Print the coefficients and intercept for logistic regression
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
// We can also use the multinomial family for binary classification
val mlr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
.setFamily("multinomial")
val mlrModel = mlr.fit(training)
// Print the coefficients and intercepts for logistic regression with multinomial family
println(s"Multinomial coefficients: ${mlrModel.coefficientMatrix}")
println(s"Multinomial intercepts: ${mlrModel.interceptVector}")setRegParam 即λ,正则化参数(泛化能力),加正则化的前提是特征值要进行归一化。
在实际应该过程中,为了增强模型的泛化能力,防止我们训练的模型过拟合,特别是对于大量的稀疏特征,模型复杂度比较高,需要进行降维,我们需要保证在训练误差最小化的基础上,通过加上正则化项减小模型复杂度。在逻辑回归中,有L1、L2进行正则化。可参与:http://blog.csdn.net/illbehere/article/details/53191711,损失函数如下:
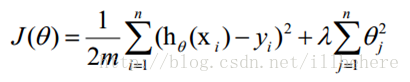
setElasticNetParam即α,用来设置梯度下降的步长。递度下降公式如下,同可参考http://blog.csdn.net/illbehere/article/details/53191711:
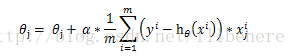
决策树
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer}
// Load the data stored in LIBSVM format as a DataFrame.
val data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
// Index labels, adding metadata to the label column.
// Fit on whole dataset to include all labels in index.
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(data)
// Automatically identify categorical features, and index them.
val featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(4) // features with > 4 distinct values are treated as continuous.
.fit(data)
// Split the data into training and test sets (30% held out for testing).
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
// Train a DecisionTree model.
val dt = new DecisionTreeClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")
// Convert indexed labels back to original labels.
val labelConverter = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictedLabel")
.setLabels(labelIndexer.labels)
// Chain indexers and tree in a Pipeline.
val pipeline = new Pipeline()
.setStages(Array(labelIndexer, featureIndexer, dt, labelConverter))
// Train model. This also runs the indexers.
val model = pipeline.fit(trainingData)
// Make predictions.
val predictions = model.transform(testData)
// Select example rows to display.
predictions.select("predictedLabel", "label", "features").show(5)
// Select (prediction, true label) and compute test error.
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println("Test Error = " + (1.0 - accuracy))
val treeModel = model.stages(2).asInstanceOf[DecisionTreeClassificationModel]
println("Learned classification tree model:\n" + treeModel.toDebugString)朴素贝叶斯
import org.apache.spark.ml.classification.NaiveBayes
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
// Load the data stored in LIBSVM format as a DataFrame.
val data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
// Split the data into training and test sets (30% held out for testing)
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3), seed = 1234L)
// Train a NaiveBayes model.
val model = new NaiveBayes()
.fit(trainingData)
// Select example rows to display.
val predictions = model.transform(testData)
predictions.show()
// Select (prediction, true label) and compute test error
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println("Test set accuracy = " + accuracy)线性回归
import org.apache.spark.ml.regression.LinearRegression
// Load training data
val training = spark.read.format("libsvm")
.load("data/mllib/sample_linear_regression_data.txt")
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// Fit the model
val lrModel = lr.fit(training)
// Print the coefficients and intercept for linear regression
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
// Summarize the model over the training set and print out some metrics
val trainingSummary = lrModel.summary
println(s"numIterations: ${trainingSummary.totalIterations}")
println(s"objectiveHistory: [${trainingSummary.objectiveHistory.mkString(",")}]")
trainingSummary.residuals.show()
println(s"RMSE: ${trainingSummary.rootMeanSquaredError}")
println(s"r2: ${trainingSummary.r2}")kmeans聚类
输入格式:
Param name | Type(s) | Default | Description
featuresCol | Vector | “features” | Feature vector
输出格式:
Param name | Type(s) | Default | Description
predictionCol | Int | “prediction” | Predicted cluster center
mport org.apache.spark.ml.clustering.KMeans
// Loads data.
val dataset = spark.read.format("libsvm").load("data/mllib/sample_kmeans_data.txt")
// Trains a k-means model.
val kmeans = new KMeans().setK(2).setSeed(1L)
val model = kmeans.fit(dataset)
// Evaluate clustering by computing Within Set Sum of Squared Errors.
val WSSSE = model.computeCost(dataset)
println(s"Within Set Sum of Squared Errors = $WSSSE")
// Shows the result.
println("Cluster Centers: ")
model.clusterCenters.foreach(println)kmeans一般通过computeCost来决定k的个数。
LDA
import org.apache.spark.ml.clustering.LDA
// Loads data.
val dataset = spark.read.format("libsvm")
.load("data/mllib/sample_lda_libsvm_data.txt")
// Trains a LDA model.
val lda = new LDA().setK(10).setMaxIter(10)
val model = lda.fit(dataset)
val ll = model.logLikelihood(dataset)
val lp = model.logPerplexity(dataset)
println(s"The lower bound on the log likelihood of the entire corpus: $ll")
println(s"The upper bound bound on perplexity: $lp")
// Describe topics.
val topics = model.describeTopics(3)
println("The topics described by their top-weighted terms:")
topics.show(false)
// Shows the result.
val transformed = model.transform(dataset)
transformed.show(false)ALS协同过滤
作者:小黑
链接:https://www.zhihu.com/question/31509438/answer/52268608
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
整理一下自己的理解。
对于一个users-products-rating的评分数据集,ALS会建立一个user*product的m*n的矩阵
其中,m为users的数量,n为products的数量
但是在这个数据集中,并不是每个用户都对每个产品进行过评分,所以这个矩阵往往是稀疏的,用户i对产品j的评分往往是空的
ALS所做的事情就是将这个稀疏矩阵通过一定的规律填满,这样就可以从矩阵中得到任意一个user对任意一个product的评分,ALS填充的评分项也称为用户i对产品j的预测得分
所以说,ALS算法的核心就是通过什么样子的规律来填满(预测)这个稀疏矩阵
它是这么做的:
假设m*n的评分矩阵R,可以被近似分解成U*(V)T
U为m*d的用户特征向量矩阵
V为n*d的产品特征向量矩阵((V)T代表V的转置,原谅我不会打转置这个符号。。)
d为user/product的特征值的数量
关于d这个值的理解,大概可以是这样的
对于每个产品,可以从d个角度进行评价,以电影为例,可以从主演,导演,特效,剧情4个角度来评价一部电影,那么d就等于4
可以认为,每部电影在这4个角度上都有一个固定的基准评分值
例如《末日崩塌》这部电影是一个产品,它的特征向量是由d个特征值组成的
d=4,有4个特征值,分别是主演,导演,特效,剧情
每个特征值的基准评分值分别为(满分为1.0):
主演:0.9(大光头还是那么霸气)
导演:0.7
特效:0.8
剧情:0.6
矩阵V由n个product*d个特征值组成
对于矩阵U,假设对于任意的用户A,该用户对一部电影的综合评分和电影的特征值存在一定的线性关系,即电影的综合评分=(a1*d1+a2*d2+a3*d3+a4*d4)
其中a1-4为用户A的特征值,d1-4为之前所说的电影的特征值
参考:
协同过滤中的矩阵分解算法研究
那么对于之前ALS算法的这个假设
m*n的评分矩阵R,可以被近似分解成U*(V)T
就是成立的,某个用户对某个产品的评分可以通过矩阵U某行和矩阵V(转置)的某列相乘得到
那么现在的问题是,如何确定用户和产品的特征值?(之前仅仅是举例子,实际中这两个都是未知的变量)
采用的是交替的最小二乘法
在上面的公式中,a表示评分数据集中用户i对产品j的真实评分,另外一部分表示用户i的特征向量(转置)*产品j的特征向量(这里可以得到预测的i对j的评分)
用真实评分减去预测评分然后求平方,对下一个用户,下一个产品进行相同的计算,将所有结果累加起来(其中,数据集构成的矩阵是存在大量的空打分,并没有实际的评分,解决的方法是就只看对已知打分的项)
参考:
ALS 在 Spark MLlib 中的实现http://www.dataguru.cn/article-7049-1.html
但是这里之前问题还是存在,就是用户和产品的特征向量都是未知的,这个式子存在两个未知变量
解决的办法是交替的最小二乘法
首先对于上面的公式,以下面的形式显示:
为了防止过度拟合,加上正则化参数
首先用一个小于1的随机数初始化V
根据公式(4)求U
此时就可以得到初始的UV矩阵了,计算上面说过的差平方和
根据计算得到的U和公式(5),重新计算并覆盖V,计算差平方和
反复进行以上两步的计算,直到差平方和小于一个预设的数,或者迭代次数满足要求则停止
取得最新的UV矩阵
则原本的稀疏矩阵R就可以用R=U(V)T来表示了
以上公式内容截图来自:
基于矩阵分解的协同过滤算法
总结一下:
ALS算法的核心就是将稀疏评分矩阵分解为用户特征向量矩阵和产品特征向量矩阵的乘积
交替使用最小二乘法逐步计算用户/产品特征向量,使得差平方和最小
通过用户/产品特征向量的矩阵来预测某个用户对某个产品的评分
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}
val ratings = spark.read.textFile("data/mllib/als/sample_movielens_ratings.txt")
.map(parseRating)
.toDF()
val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))
// Build the recommendation model using ALS on the training data
val als = new ALS()
.setMaxIter(5)
.setRegParam(0.01)
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
val model = als.fit(training)
// Evaluate the model by computing the RMSE on the test data
val predictions = model.transform(test)
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
val rmse = evaluator.evaluate(predictions)
println(s"Root-mean-square error = $rmse")














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









