






1. CUDA线程组织与GPU架构
1.1 CUDA线程组织
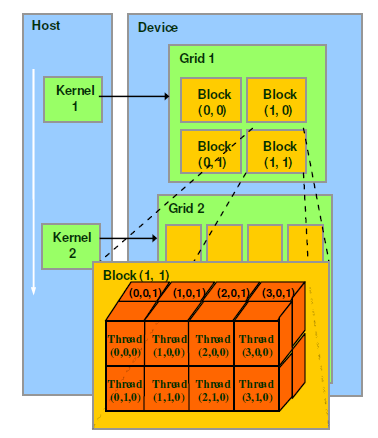
一个核函数对应一个grid,grid里面有若干block,block里面有若干thread,32个thread称为一个warp。
下面这四段介绍copy自:理解CUDA中的thread,block,grid和warp - 知乎 (zhihu.com)
SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
当一个kernel被执行时,grid中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread(SIMT)。
一个CUDA core可以执行一个thread,一个SM的CUDA core会分成几个warp(即CUDA core在SM中分组),由warp scheduler负责调度。尽管warp中的线程从同一程序地址,但可能具有不同的行为,比如分支结构,因为GPU规定warp中所有线程在同一周期执行相同的指令,warp发散会导致性能下降。一个SM同时并发的warp是有限的,因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器,所以SM的配置会影响其所支持的线程块和warp并发数量。
一个warp中的线程必然在同一个block中,如果block所含线程数目不是warp大小的整数倍,那么多出的那些thread所在的warp中,会剩余一些inactive的thread,也就是说,即使凑不够warp整数倍的thread,硬件也会为warp凑足,只不过那些thread是inactive状态,需要注意的是,即使这部分thread是inactive的,也会消耗SM资源。由于warp的大小一般为32,所以block所含的thread的大小一般要设置为32的倍数。
1.2 GPU架构
GPU
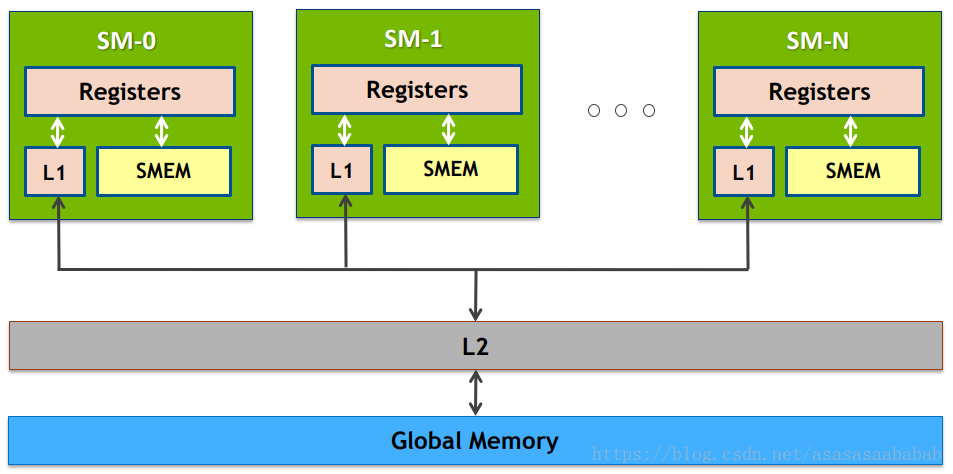
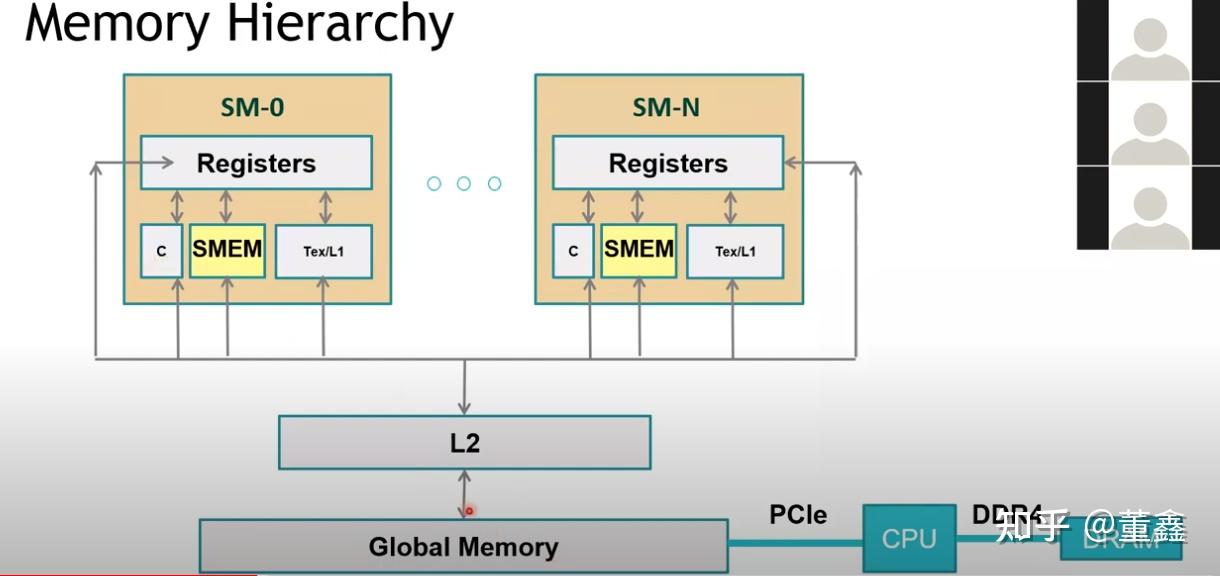
下图是一个GPU的架构图,里面有许多SM。
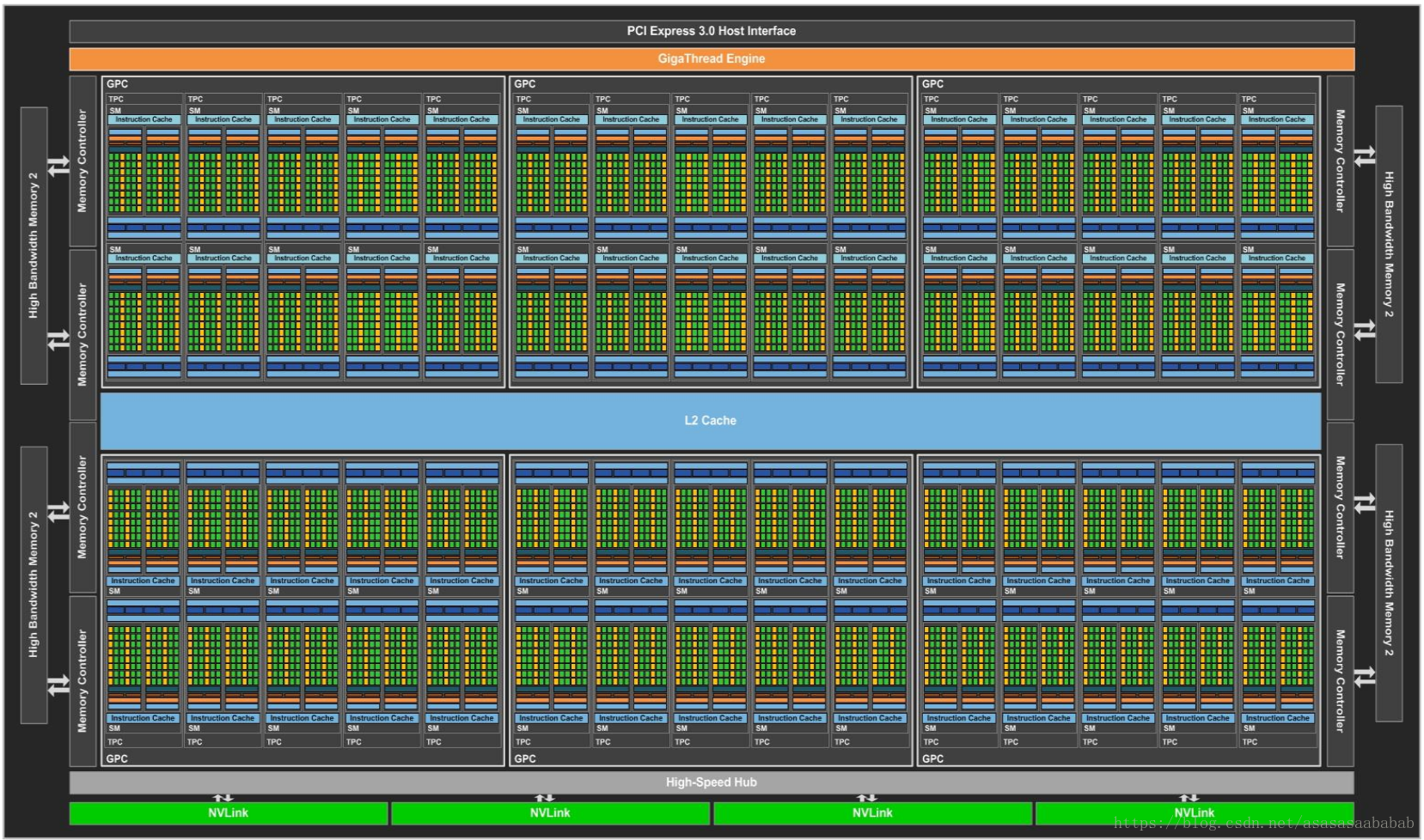
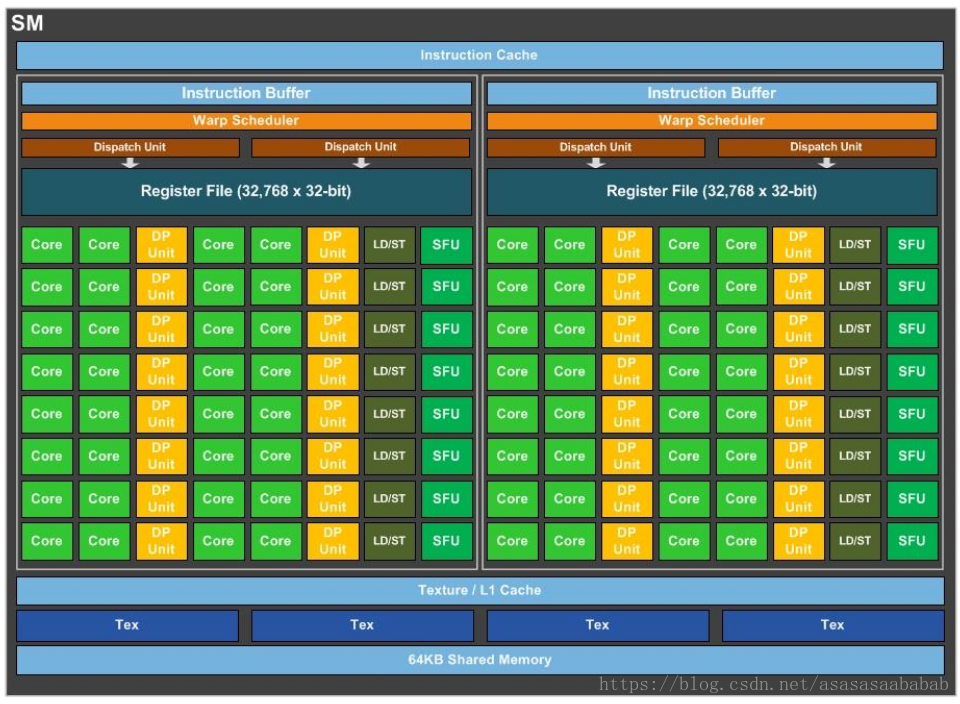
SM (Streaming MultiProcessor)
一个SM里面有两个SMP (SM Processing Block)。绿色的方块Core就是CUDA core;深绿色的方块LD/ST是内存操作load/store;要注意,CUDA core做的是单精度浮点数的运算,DP Unit做的是双精度浮点数的运算,二者数量比为2:1;绿色方块SFU指的是Special Function Unit,做一些特殊函数的计算,比如sin、cos等。
每个SM有自己的指令缓存、L1缓存、共享内存。每个SMP有自己的warp scheduler、Register File等。
CUDA core
GPU内存架构
Global Memory就是平常说的显存(GPU Memory),L1缓存指的就是共享内存(第五章会细说)。
每次shared memory (也就是L1)要去访问Global Memory时,就会先看看L2里面有没有,有的话,就不用去global memory了。
2. Hello World
GPU只是一个设备,要它工作的话,需要有一个主机来给它下达命令。这个主机就是CPU。
主机对设备的调用都是通过核函数(kernel function)来实现的。所以,一个简单的cuda程序的结构具有下面这种形式:
int main() {
主机代码
核函数的调用
主机代码
return 0;
}
核函数的前面必须有***__global__***来修饰,并且返回值类型必须是void,比如下面这样:
__global__ void hello_from_gpu() {
printf("Hello World From the GPU!");
}
__global__ 和 void 的次序可以交换
上述核函数需要被主机调用才能发挥作用,如下:
#include<stdio.h>
__global__ void hello_from_gpu() {
printf("Hello World From the GPU!");
}
int main() {
hello_from_gpu<<<1, 1>>>();
cudaDeviceSynchronize();
return 0;
}
- hello_from_gpu<<<1, 1>>>() : 主机在调用一个核函数时,需要指明给设备分配多少线程。第一个参数是grid_size,第二个参数是block_size。也就是说,第一个参数是block的数量,第二个参数是一个block中thread的数量。
- cudaDeviceSynchronize() : 输出流先存放在缓冲区中,而缓冲区不会自动刷新,只有程序遇到某种同步操作时缓冲区才会刷新,这个函数可以同步主机与设备,进而能够促使缓冲区刷新。
3. 数组相加
#include<stdio.h>
#include<math.h>
const double a = 1.11;
const double b = 2.22;
__global__ void add(const double *x, const double *y, double *z);
int main() {
const int N = 10000;
const int M = sizeof(double) * N;
double *h_x = (double*)malloc(M);
double *h_y = (double*)malloc(M);
double *h_z = (double*)malloc(M);
for (int i = 0; i < N; i++) {
h_x[i] = a;
h_y[i] = b;
}
double *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, M);
cudaMalloc((void**)&d_y, M);
cudaMalloc((void**)&d_z, M);
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
const int block_size = 128;
const int grid_size = N / block_size;
add<<<grid_size, block_size>>>(d_x, d_y, d_z);
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);
free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}
__global__ void add(const double *x, const double *y, double *z) {
const int tid = blockIdx.x * blockDim.x + threadIdx.x;
z[tid] = x[tid] + y[tid];
}
C++ VS CUDA
使用C++写数组相加,需要一层for循环 for(int i = 0; i < N; i++){z[i] = x[i] + y[i]},但使用CUDA时,使用的是“单指令-多线程”,即SIMT,将数组元素与线程一一对应起来,每一个线程执行一对数组元素的加法,即每个线程都会执行 z[tid] = x[tid] + y[tid],无需那一层for循环。
内存分配、释放、复制
-
cudaMalloc : 分配设备内存,函数原型如下:
cudaError_t cudaMalloc(void **address, size_t size);
address是待分配设备内存的指针,即地址的指针,是个双重指针。size是待分配内存的字节数。
(void**)是强制转换,可以不写,也就是说设备内存分配也可以这样写:cudaMalloc(&d_x, M);
-
cudaFree : 释放设备内存,cudaMalloc分配的内存需要使用cudaFree来释放。函数原型如下:
cudaError_t cudaFree(void* adress); -
cudaMemcpy : 设备与主机之间的数据传递,函数原型如下:
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);dst是目标地址;src是源地址;count是复制的字节数;kind是一个枚举类型的变量,表示数据传递方向,有五个值:cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, cudaMemcpyDefault(根据dst和src自动判断传输方向,这要求系统具有统一虚拟寻址的功能)
-
隐形的设备初始化:在CUDA运行时API中,没有明显地初始化设备的函数。在第一次调用一个和设备管理及版本查询功能无关的运行时API函数时,设备将自动初始化。
当N % block_size != 0时
前面,指定N=100000000,是block_size的整数倍,恰好781250个block,每个block有128个thread,每个thread负责一对数组元素的加法。但是当N不是block_size的整数倍时呢?比如当N=100000001时,应该指定grid_size=781251,也就是最后一个block里面的128个thread只需处理一对数组元素的加法,那么应该注意到,继续按照上面的写法z[tid] = x[tid] + y[tid]的话,会产生越界访问,因此应写一个if,如下所示:
if (tid < N) {
z[tid] = x[tid] + y[tid];
}
此外,前面的grid_size赋值也应修改一下
grid_size = (N % block_size == 0) ? (N / block_size) : (N / block_size + 1)
4. 设备函数
核函数可以调用不带执行配置的自定义函数,这样的自定义函数被称为设备函数(device function)。
__global__ 修饰的函数为核函数(kernel function),主机调用、设备执行。
__device__ 修饰的函数为设备函数(device function),设备调用、设备执行。
__host__ 修饰的函数是主机端的普通C++函数,主机调用、主机执行,可省略该修饰符。
举个栗子
__device__ double add_device(const double x, const double y) {
return (x + y);
}
__global__ void add(const double *x, const double *y, double *z) {
const int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
z[tid] = add_device(x[tid], y[tid]);
}
}
add_device是个设备函数,add是个核函数,add调用了add_device。
5. 内存组织
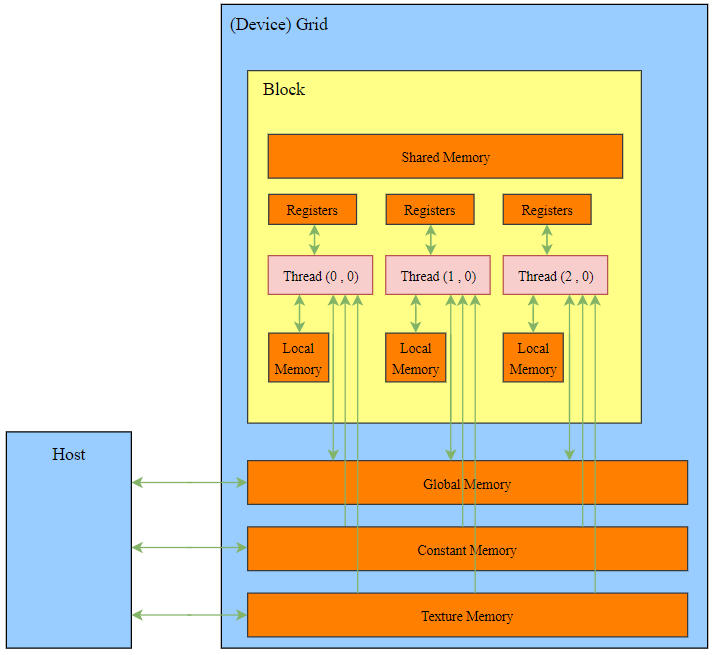
5.1 全局内存(global memory)
全局内存不在片上,是GPU中容量最大、延迟最高的内存空间。
核函数中的所有线程都能访问全局内存,全局内存的主要角色是为核函数提供数据,并在主机与设备、设备与设备之间传递数据。
一个全局内存变量可以在主机端使用cudaMalloc动态声明,也可以使用***__device__***静态声明,比如下面这样:
__device__ double data; // 静态全局内存变量
需要注意,不能通过&来获取data的地址,但是可以通过cudaGetSymbolAddress来获取其地址,函数原型如下:
cudaError_t cudaGetSymbolAddress(void **devPtr, const void *symbol); // devPtr是symbol的地址
这个函数可以获取device端的全局地址,然后就可以通过cudaMemcpy与主机内存进行数据传输了,比如下面这样:
__device__ double dev_data;
int main() {
xxxxxxxxxxxx
double *dev_ptr = NULL;
cudaGetSymbolAddress((void**)&dev_ptr, dev_data);
xxxxxxxxxxxx
}
此外,还有一种方法可以实现静态全局内存与主机内存之间的数据传输,需要用到两个函数:cudaMemcpyToSymbol和cudaMemcpyFromSymbol,其函数原型如下:
cudaError_t cudaMemcpyToSymbol(
const void *symbol, // 静态全局内存变量的名称
const void *src, // 主机内存缓冲区指针
size_t count, // 复制的字节数
size_t offset = 0, //从symbol对应设备地址开始偏移的字节数
cudaMemcpyKind kind = cudaMemcpyHostToDevice // 可选参数
) // 主机->设备(给symbol赋值)
cudaError_t cudaMemcpyFromSymbol(
void *dst, // 主机内存缓冲区指针
const void *symbol, // 静态全局内存变量的名称
size_t count, // 复制的字节数
size_t offset = 0, //从symbol对应设备地址开始偏移的字节数
cudaMemcpyKind kind = cudaMemcpyDeviceToHost // 可选参数
) // 设备到主机(给dst赋值)
具体用法如下:
#include<stdio.h>
__device__ int d_x = 1;
__device__ int d_y[2];
__global__ void my_kernel() {
d_y[0] += d_x;
d_y[1] += d_x;
}
int main() {
int h_y[2] = {10, 20};
cudaMemcpyToSymbol(d_y, h_y, sizeof(int)*2);
my_kernel<<<1, 1>>>();
cudaMemcpyFromSymbol(h_y, d_y, sizeof(int)*2);
return 0;
}
其实,下面要介绍的常量内存,也可以使用上面这两个函数进行数据传输,也就是说symbol也可以是常量内存变量的名称。
5.2 常量内存 (const memory)
常量内存是具有常量缓存的全局内存,访问速度比全局内存高。
常量内存变量使用 __constant__ 进行修饰,需要在全局空间内和所有核函数之外进行声明。
常量内存与主机内存之间的数据传输也是通过cudaMemcpyToSymbol和cudaMemcpyFromSymbol实现的。
5.3 纹理内存 (texture memory) 和表面内存 (surface memory)
纹理内存和表面内存类似于常量内存,也是一种具有缓存的全局内存,但是纹理内存和表内内存的容量比常量内存大。
纹理内存驻留在设备内存中,并在每个SM的只读缓存中缓存。纹理内存是一种通过指定的只读缓存访问的全局内存,是对二维空间局部性的优化,所以使用纹理内存访问二维数据的线程可以达到最优性能。
5.4 寄存器
寄存器位于片上,是所有内存中访问速度最高的。
在核函数中声明且没有其他修饰符修饰的变量通常存放在寄存器中。寄存器通常用于存放核函数中需要频繁访问的线程私有变量,这些变量与内核函数的生命周期相同,核函数执行完毕后,就不能再对它们进行访问了。比如下面代码中的tid就会存放在寄存器中。
__global__ void add(const double *x, const double *y, double *z) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
z[tid] = add_device(x[tid], y[tid]);
}
}
gridDim、blockDim、blockIdx、threadIdx、warpSize等内建变量,也保存在寄存器中。
一个SM中寄存器的数量比较有限,一旦核函数使用了超过硬件限制的寄存器数量,则会使用本地内存来代替多占用的寄存器,这种寄存器溢出的情况会带来性能上的不利影响,实际编程过程中我们应该避免这种情况。使用nvcc的编译选项maxrregcount可以控制内核函数使用的寄存器的最大数量。
5.5 本地内存 (local memory)
本地内存在用法上和寄存器几乎一样,但从硬件上来看,本地内存只是全局内存的一部分。
在核函数中符合存储在寄存器中但不能进入分配的寄存器空间中的变量将被溢出到本地内存中,可能存放到本地内存中的变量有:
- 编译时使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地结构体或者数组
- 任何不满足核函数寄存器限定条件的变量
5.6 共享内存 (shared memory)
共享内存具有仅次于寄存器的读写速度。在核函数中被***__shared__***修饰的变量被存储到共享内存中。
共享内存对整个线程块可见,是一个线程块中的所有线程公用的,但是它们不能访问其他线程块的共享内存。
线程块中的线程通过使用共享内存中的数据可以实现互相之间的协作,不过使用共享内存必须调用如下函数进行同步:
void __sybcthreads()
该函数为线程块中的所有线程设置了一个barrier,使得该线程块中的所有线程必须都执行到该barrier才能继续往下执行,避免潜在的数据冲突。
5.7 L1和L2缓存
从费米架构开始,有了SM层次的L1缓存(一级缓存)和设备(一个设备有多个SM)层次的L2缓存(二级缓存),它们主要用来缓存全局内存和本地内存的访问,减少延迟。
从编程角度来看,共享内存是可编程的缓存(共享内存的使用完全由用户操控),而L1和L2缓存是不可编程的缓存(用户最多只能引导编译器做一些选择)
5.8 主机端的内存——可分页内存、页锁定内存
在进行CPU和GPU协同计算的过程中,会涉及到数据在CPU内存和GPU内存之间的传输。
操作系统在逻辑层面将CPU内存分为两类:可分页内存(Pageable Memory)和页锁定内存(Page Lock Memory, 又称为Pinned Memory),可分页内存没有锁定特性,可能会被交换出去,比如传输到硬盘上,而页锁定内存具有锁定特性,不会被交换出去。
GPU不能在可分页内存上安全地访问数据,因为当主机端操作系统在物理位置上移动该数据时它无法控制。因此,CPU内存和GPU内存之间的数据传输是发生在页锁定内存和全局内存之间的。如果可分页内存上的数据要想传输到GPU内存上,应先传输到页锁定内存上,再从页锁定内存传输到GPU内存;GPU内存上的数据要想传输到CPU内存,只能传输到页锁定内存上。
CUDA提供cudaMallocHost,可以直接分配页锁定内存:
cudaError_t cudaMallocHost(void **devPtr, size_t count);
然后需要通过cudaFreeHost释放:
cudaError_t cudaFreeHost(void *ptr);















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









