









当我们使用正则化的线性回归方法预测房价时,发现得到的模型应用于新的数据上时有很大误差,这时,我们可以选择一些解决方案,例如:
上图中的这六种解决方案都有相应的条件,如图中蓝色字体所示。

【一、回归模型选择】
我们引入一类数据集,叫做cross validation set,即交叉验证数据集。将所有数据按6:2:2
分为training set , cross validation set , testing set三类,如下图所示:
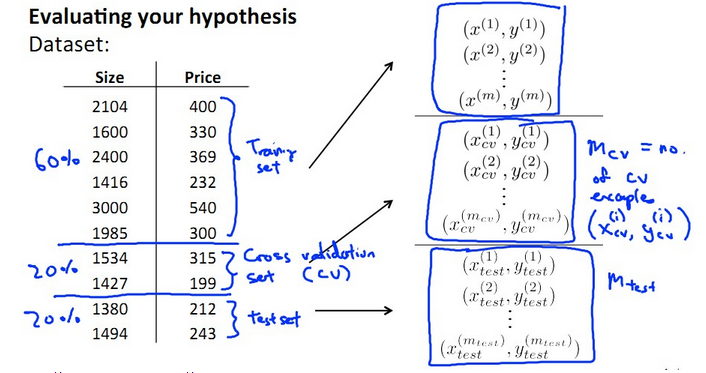

【模型选择的步骤】
- 建立d个假设模型,如下图所示(d=10),分别在training set 上求使其training error最小的θ向量,那么得到d个θ。
- 对这d个假设模型,在cross validation set上计算J(cv),选择cv set error最小的一个模型 ,例如:如果J(cv)在第2组中最小,则取d=2的假设。

【二、bias and variance的定义】
对于不同的模型,有不同的拟合情况,如下图所示:
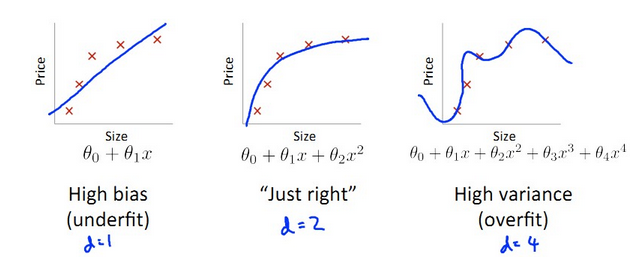
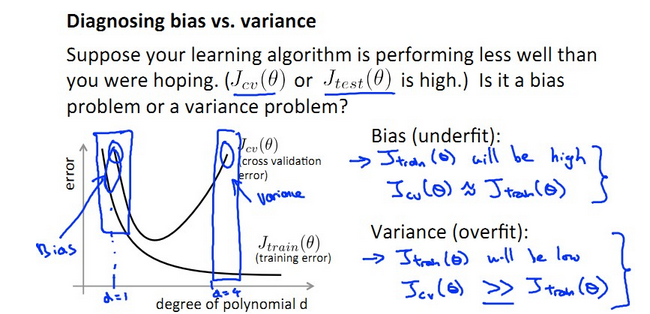
由上图可定义:
- bias:J(train)大,J(cv)大,J(train)≈J(cv),bias产生于d小,underfit阶段
- variance:J(train)小,J(cv)大,J(train)远远小于J(cv),variance产生于d大,overfit阶段
【三、正则化参数λ的选择】
为了解决过拟合的问题,使用正则化,但是正则化参数λ的正确选择是一个难题。
- λ太小导致overfit,产生variance,J(train)远远小于J(cv)
-
λ太大导致underfit,产生bias,J(train) ≈ J(cv)
如下图所示:
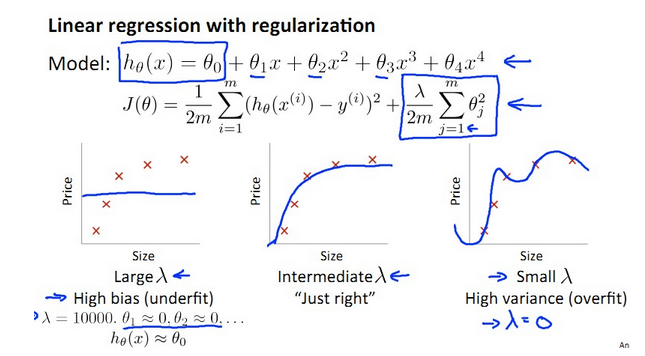
关于λ的曲线如下:
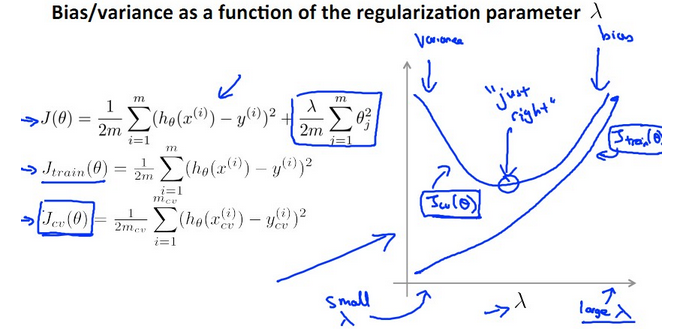
【参数λ的选择】
- 将λ从0,0.01,一直往上每次乘以2,那么到10.24总共可以试12次λ。这12个λ会得到12个模型,如下图所示。每个对应有J(θ)和 Jcv(θ),分别在training set 上求使其training error最小的θ向量,那么得到12个θ。
2.在cross validation set上计算J(cv),选择cv set error最小的一个模型 ,然后取出令Jcv(θ)最小的一组定为最终的λ。例如假设J(cv)在第5组中最小,则取λ=0.08的假设,如下图所示。

【四、什么时候增加训练数据training set才是有效的?】
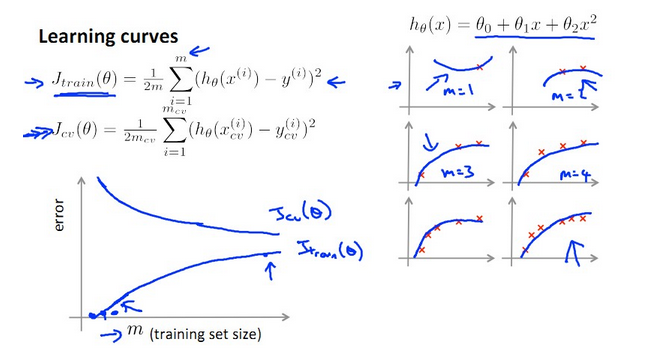
从上图可知:训练数据越少,J(train)越小,J(cv)越大;m越大,J(train)越大(因为越难完全拟合),J(cv)越小(因为越精确)。
那么怎么判断增加训练数据training set的数目m能够对算法有较大改进呢??
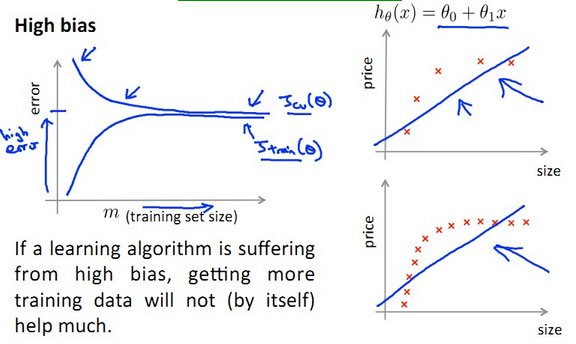
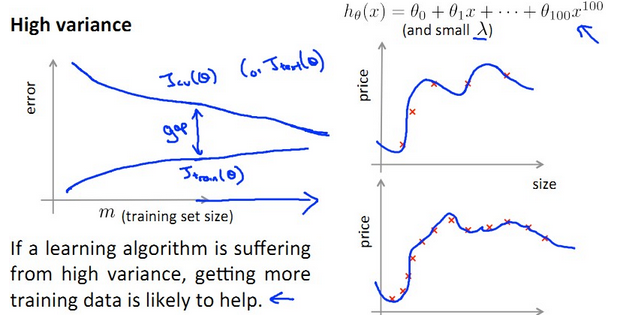
【总结】
- Underfit 的 High bias: J(train)≈J(cv)增加m没什么帮助!
- Overfit的 High Variance: 增加m使得J(train)和J(cv)之间gap减小,有助于performance提高!














 2316
2316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









