






作者简介:刘汪根,星环科技研发总监。目前负责星环科技大数据平台软件Transwarp Data Hub的研发工作,主导开发星环大数据平台的大量创新功能,包括国内领先的完整兼容SQL标准的Hadoop SQL编译器,首个完整支持ACID属性的分布式事务,稳定高效的分布式执行引擎,帮助星环快速的提高Hadoop平台的性能/可用性以及稳定性,帮助TDH在金融公安等重要领域的大规模落地。在此之前曾在NVIDIA和Intel工作8年,参与和负责CPU和GPU多核计算平台的架构设计,验证以及编译器优化工作,有丰富的并行计算和系统优化经验。
责编:郭芮,关注大数据领域,纠错、寻求报道或者投稿请致邮guorui@csdn.net。
Databricks近期推出了Spark 2.0的预览版,开源社区对这个版本有非常高的期待,即使是预览版也有很多的下载试用。Spark版本号从1.x演进到2.0,可以看出社区对这个版本寄予厚望。在对外发布的官方blog中,Easier/Faster/Smarter是其宣传的几个主要创新领域。笔者把它通俗的翻译为:SQL支持更全,更强大的性能,适配流式计算和批处理的统一编程模型。
从实用性的角度,这几个功能确实是企业用户特别看重的内容,说明Databricks以及社区开始重视商业需求,并期望Spark向商业产品化的方向转变。那么实际情况到底是怎样呢?和一些商业大数据产品,如星环TDH的比较又如何呢?我们来做一些深度的测评来对比下。

首先看下我们的测试环境情况,考虑到Spark的内存管理机制不够完善,我们使用了128GB的内存配置,尽量减少因为Spark SQL的稳定性问题给整个测试带来的负面影响。测试集群包含4台同构的x86服务器,每台配置如下:
CPU:2X6 core, E5 2620 v2, 2.10GHz
内存:128G
网络:千兆网卡
磁盘:3X3T
然而实际测试中,我们发现Spark SQL的稳定性依然是个很大的问题。为了测试出很好的对比数据,我们花费了比预期多5倍的时间。系统仍然有很多不稳定运行的问题,尤其是在连续运行批量的业务方面,我们几乎没有在一次连续测试中跑完所有的SQL,最后不得不从多次运行benchmark的结果中选出每个查询最好的数据作为Spark SQL的最终性能报告数据源。虽然这个测试方法因为Spark 2.0 预览版本质量问题而显的不正规,但是还是能够帮助我们去理解这个版本的一些现实状况。
同时为了对比,我们选用TDH 4.5版本来做功能以及性能验证的样板。基本测试程序也选用Databricks Blog上提到的TPC-DS。

首先值得肯定的是,Spark 2.0对TPC-DS的支持度确实比Spark 1.6更好。Spark SQL 1.6版本只能运行大约70个查询,而2.0预览版可以运行99个SQL。在SPARK-12540这个JIRA中,可以看到一些相关的TPC-DS需要的SQL功能点都在陆续的完成中。
从相应的JIRA记录中,我们可以看到Spark 2.0在SQL兼容实现上的主要思路。在Catalyst中为不同的SQL功能增加相应的变换器,将其变成有相同语义的已经实现的SQL执行计划。这个实现方式总体上不错,但同时也有很多的局限性,譬如比较难以处理各种corner case,对子查询的支持比较差,只能运行简单场景下的子查询,此外一些SQL可能会触发多种变换器,从而带来一些不是期望中的结果。正如Databricks的开发人员在各自JIRA上对这些限制的一些描述:
Restricions:
1.EXISTS/ NOT EXISTS/INT IN can only be used as top level conditions of WHERE/HAVING, can’t be used in OR or others.
2. a NOT IN subquery is not supported, if subquery is nullable, which requires a null-aware semi join.
3. Correlated subquery can only be used inside WHERE/HAVING, uncorrelated scalar subquery could be used anywhere.
在我们的测试中也发现,对于非TPC-DS中的SQL业务,譬如涉及到非等值的关联/子查询等,Spark SQL仍然不支持。因此,对于复杂的生产环境,尤其是基于复杂的主题模型设计出来的企业业务,Spark SQL依然有比较长的路要走。
另外,增删改相关的业务SQL仍然不在Spark社区的路线图上。
与之对比,TDH在2015年1月份就完整支持SQL’99标准,包含完整的增删改查支持,并且通过了TPC-DS的完整测试。此外由于是完整的SQL编译器,TDH对各种复杂的SQL业务,包括非等值的关联/子查询等也有很好的支持。更值得一提的是,TDH有完整的分布式事务的支持,可以保证数据加工过程中的数据最终一致性;而TDH PL/SQL可以让开发人员更方便的实现复杂逻辑业务。
结论:Spark 2.0 SQL支持度有所提升,离生产要求还有一定的距离。

我们选择1TB的TPC-DS数据集作为本次性能测试的数据源,从而比较好的贴近实际的大数据生产项目。在测试中,我们将Tungsten engine以及‘whole-stage code generation’等优化都打开,力争测试出Spark SQL 2.0的最佳性能。
同样,我们选择Inceptor 4.5作为测试的对比平台,同时打开Inceptor的标准优化参数 inceptor.optimizer.mode=true.
总体上的性能测试结果如下,Inceptor相对于Spark 2.0仍然有3倍的性能领先优势。Spark SQL在一些比较简单的SQL的执行上有亮点,但是在综合的业务分析SQL上就表现的比较糟糕,但是相对于Spark 1.6还是有~10%左右的提升。
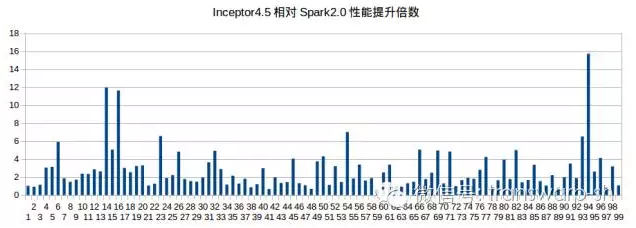

从Tungsten Engine开始,Spark在系统稳定性方面有一些提升,但是仍然处于一个比较混沌的状态,有些问题社区也并没有思路如何去解决。常见的几个问题就是内存溢出问题,Block Manager死锁问题以及使用超额内存被Yarn Kill的问题。其中,内存溢出问题在Spark 2.0中仍然很严重,spill机制不能有效的释放内存,主要原因在于部分堆外内存处于无监管的状态。因此,在Spark SQL运行一段时间后,GC的表现就很差。
这个问题给我们的测试带来很大的麻烦。按照TPC-DS的SPEC,我们的测试需要连续的运行所有SQL多遍,然后用算术加权的方式来计算每个查询的性能数据。而实际情况是,Spark SQL 2.0预览版本还无法完整的运行1TB级别的性能测试,我们需要频繁的从多个失败点来重试这个测试,因此人力的干预比较多。
总体上看来,Spark SQL 2.0预览版离7x24小时的生产要求还有很长的距离。而TDH已经在多个金融行业的业务中稳定运行很久,在系统稳定性方面处于遥遥领先的地位。

Spark 2.0版本有几个主推的性能优化,因此我们此次重点的去研究了下这些优化的实际效果,是否跟宣传的情况类似。我们挑选了Blog里面描述有数量级性能提升的‘Whole-stage code generation’以及‘Vectorized Parquet Reader’这两个优化来做比较。
‘Whole-stage code generation’是为了解决scala代码调用栈过长和虚函数调用过多而引入的性能问题,通过将多个类的指定的代码inline为一个新的类函数来降低开销。从官方blog的描述来看,它可以带来十倍的性能提升。从实际测评来看,这个性能数据过于理想化。
首先,在非常严苛的场景下,这个性能数据是可以达到的。只有在系统当前只运行一个类型的简单SQL,同时运行大约10遍后,我们确实看到了性能的提升很明显,接近blog中宣传的大约10倍左右。
然而,只要系统当前还运行其他SQL,或者测试标的SQL更复杂,抑或不能重复运行该SQL很多遍,我们看到的性能提升就不够明显。
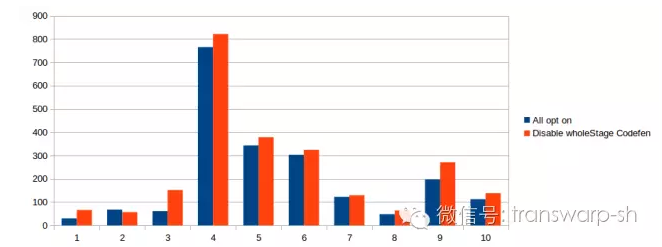
我们以TPC-DS前十个查询来看‘Whole-stage code generation’的总体表现,并且采用SPEC规定的测试方法,结果是这个优化平均只带来10%左右的性能提升。
对于‘Vectorized Parquet Reader’,我们同样选取了TPC-DS前十个查询来做优化对比分析,实际情况如下,平均的性能提升不到10%。
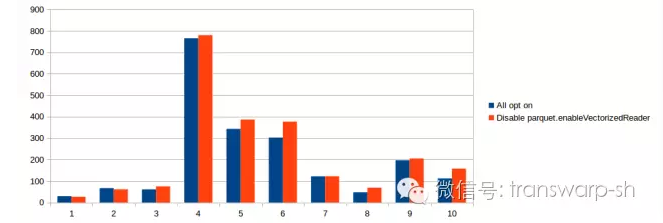
而对于这10个查询,TDH 4.5的性能是Spark 2.0开启了以上所有的性能优化后的2.5倍。

这是Spark 2.0的Smarter特性的主要宣传功能。从API的设计角度来看,在编程中弱化流的概念以及参数设置,统一化实时计算与批处理的接口设计是个非常不错的想法。如果用户基于Spark API开发,批处理的业务和实时处理可以复用一些逻辑,因此降低开发成本。
下面是一个Structured Streaming的一个例子,目的是按照5秒的时间间隔去计算用户在数据中的统计情况。相比较DStream的代码,这个例子要简单很多。
val records = sqlContext.read.format(“json”).stream(“hdfs://input”)
val counts = records.groupBy(window(
timeColumn = processing_time(),
windowSize = “5 min”,
slidingInterval = “1 min”))
.count()
counts.write
.trigger(ProcessingTime(“5 sec”))
.outputMode(UpdateInPlace(“user”))
.format(“jdbc”)
.startStream(“hdfs://output”)然而这个写法依然是基于Scala API来实现,对于存量系统来说,开发工作量依然比较大。此外,在概念的抽象和接口描述上仍然不够灵活,表达能力远远不如SQL语言。此外,各种报表工具也无法对接这些应用。
最好的方法是采用SQL编程接口来统一流计算和批量计算,而TDH就采用这种设计思路。下面的例子是TDH支持的Stream SQL对于类似功能的实现,全部采用SQL的规范。
CREATE STREAM accesslog(user STRING, count INT, time TIMESTAMP) TBLPROPERTIES("topic"="accesslog","file"="hdfs://input");
CREATE TABLE result(user STRING, count INT);
INSERT INTO result SELECT user, count(*) FROM accesslog GROUP BY time STREAMWINDOW
sw AS (LENGTH '600' SLIDE '60' SECOND);除去建表等开销,我们只需要一个INSERT语句就可以表达Spark 2.0的相应的程序。可以看出来,无论是从统一编程接口,开发便利性等,TDH Stream SQL都要远远领先于Structured Streaming。

从本次的评测结果来看,Spark 2.0有一些更贴近商业产品化的想法,尤其是在开发编程接口方面更加贴近更大规模开发人群的需求。但是依赖社区这种松散的组织结构作为开发主体,我们仍然看到Spark无法去真正的解决一些系统性的问题,SQL的支持以及性能的优化方法并没有真正的质的飞跃,而只是为了应付竞争而做的一些功能。系统稳定性问题仍然很严重,目前也没有清晰的架构或者路线图来解决这些问题,Spark 2.0仍然只是一个有所改进的版本。















 3636
3636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









