






作者:小小默,开源爱好者,关注Hadoop/Spark、机器学习、人工智能等相关技术。更多精彩欢迎关注作者个人博客。
Spark Streaming应用与实战系列包括以下六部分内容:
- 背景与架构改造
- 通过代码实现具体细节,并运行项目
- 对Streaming监控的介绍以及解决实际问题
- 对项目做压测与相关的优化
- Streaming持续优化之HBase
- 管理Streaming任务
点此阅读第一部分内容,本篇为第二部分,包括Streaming持续优化之HBase以及管理Streaming任务。
五、Streaming持续优化之HBase
5.1 设置WALog
put.setDurability(Durability.SKIP_WAL)/* 跳过写WALog /关闭WALog后写入能到20万,但是发现还是不是特别稳定,有时耗时还是比较长的,发现此阶段正在做Compaction!!!
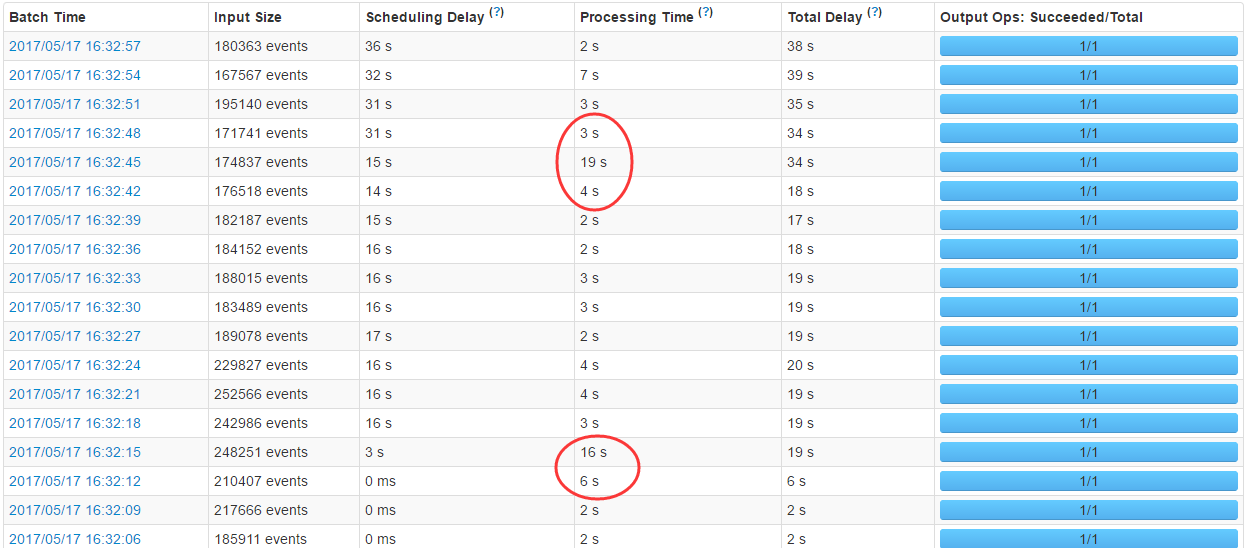
查看streaming统计,发现耗时不稳定
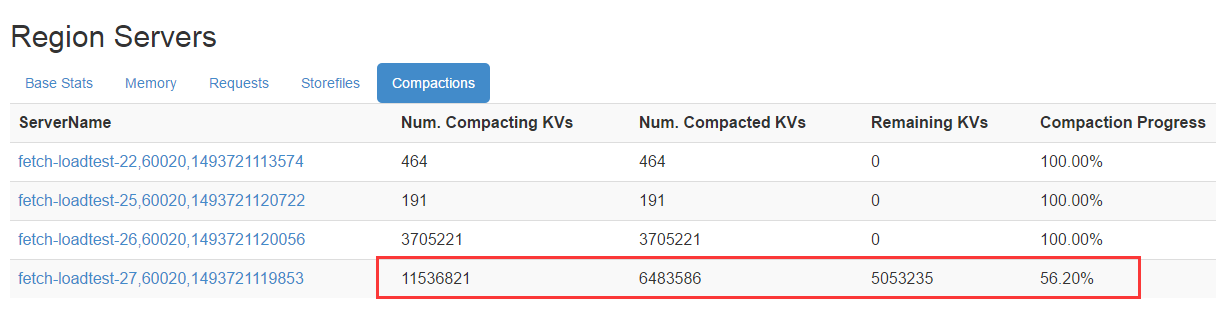
HBase界面统计信息
HBase是一种Log-Structured Merge Tree架构模式,用户数据写入先写WAL,再写缓存,满足一定条件后缓存数据会执行flush操作真正落盘,形成一个数据文件HFile。随着数据写入不断增多,flush次数也会不断增多,进而HFile数据文件就会越来越多。然而,太多数据文件会导致数据查询IO次数增多,因此HBase尝试着不断对这些文件进行合并,这个合并过程称为Compaction。
Compaction会从一个region的一个store中选择一些hfile文件进行合并。合并说来原理很简单,先从这些待合并的数据文件中读出KeyValues,再按照由小到大排列后写入一个新的文件中。之后,这个新生成的文件就会取代之前待合并的所有文件对外提供服务。
HBase根据合并规模将Compaction分为了两类:MinorCompaction和MajorCompaction。
- Minor Compaction是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile。
- Major Compaction是指将所有的StoreFile合并成一个StoreFile,这个过程还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
更多Compaction信息参考:http://hbasefly.com/2016/07/13/hbase-compaction-1/
5.2 调整压缩
通常生产环境会关闭自动major_compact(配置文件中hbase.hregion.majorcompaction设 为0),选择一个晚上用户少的时间窗口手工major_compact。
手动:major_compact ‘testtable’
如果hbase更新不是太频繁,可以一个星期对所有表做一次 major_compact,这个可以在做完一次major_compact后,观看所有的storefile数量,如果storefile数量增加到 major_compact后的storefile的近二倍时,可以对所有表做一次major_compact,时间比较长,操作尽量避免高锋期。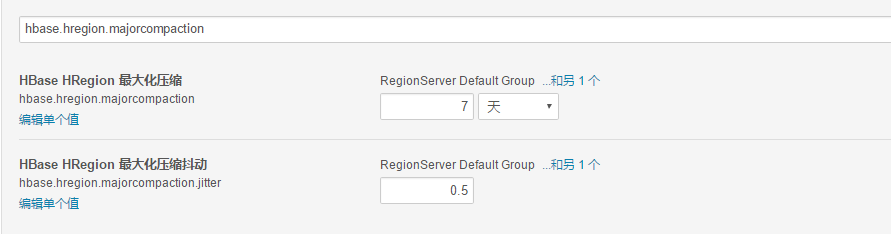
查看统计信息
Compact触发条件:
- memstore flush之后触发
- 客户端通过shell或者API触发
- 后台线程CompactionChecker定期触发
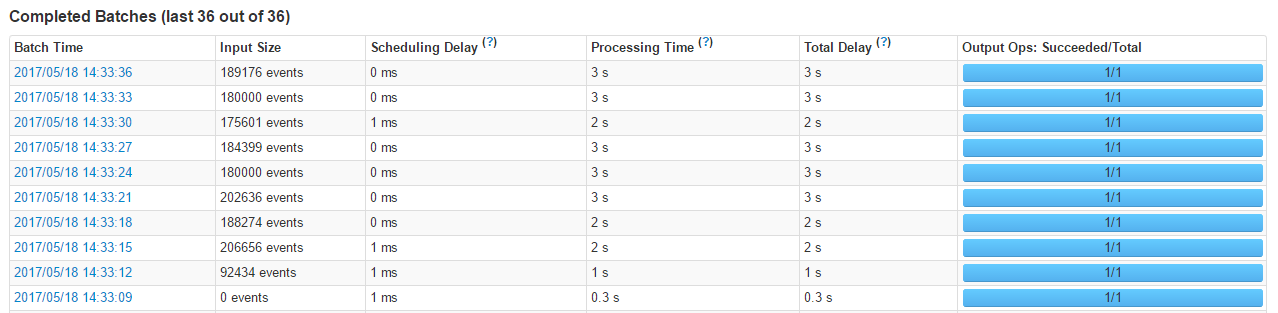
查看统计信息
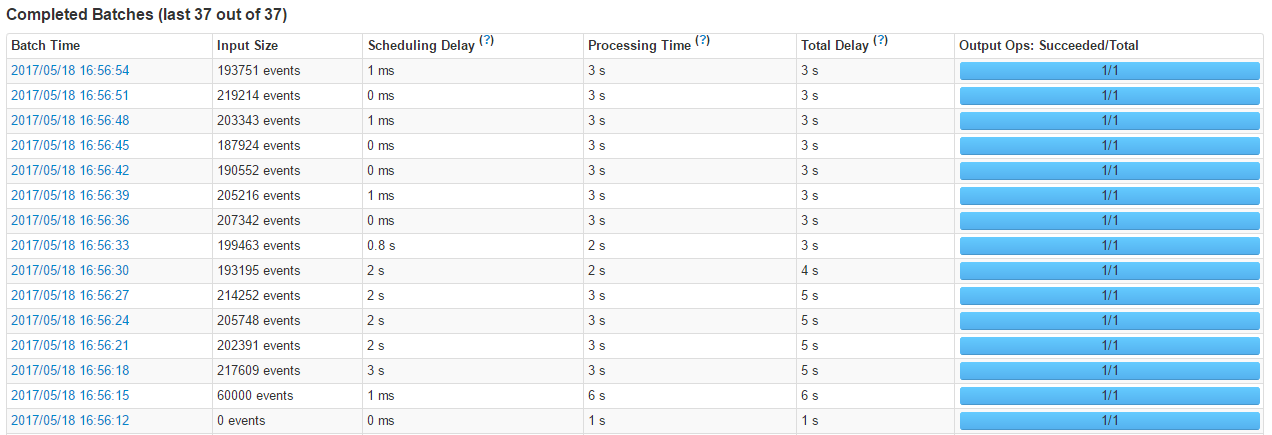
查看统计信息
周期为:Hbase.server.thread.wakefrequencyhbase.server.compactchecker.interval.multiplier触发compaction,后面还有一些其他的条件也可以在源码里面看看
条件的验证逻辑就是在这个时间范围:mcTime= 7-70.5天,7+70.5天=3.5-10.5;
是否有文件修改具体逻辑可见RatioBasedCompactionPolicy#isMajorCompaction方法。
5.3 Split
通过上面的截图我们可以看到,该表只有一个region,写入数据都集中到了一台服务器,这个远远没有发挥出HBase集群的能力呀,手动拆分吧!
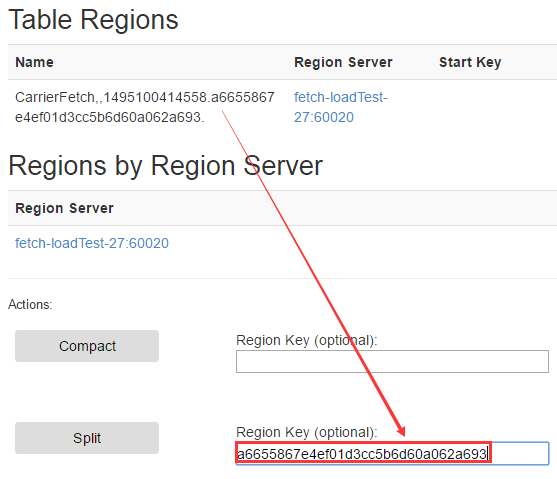
通过hbase ui界面拆分Region
拆分后:
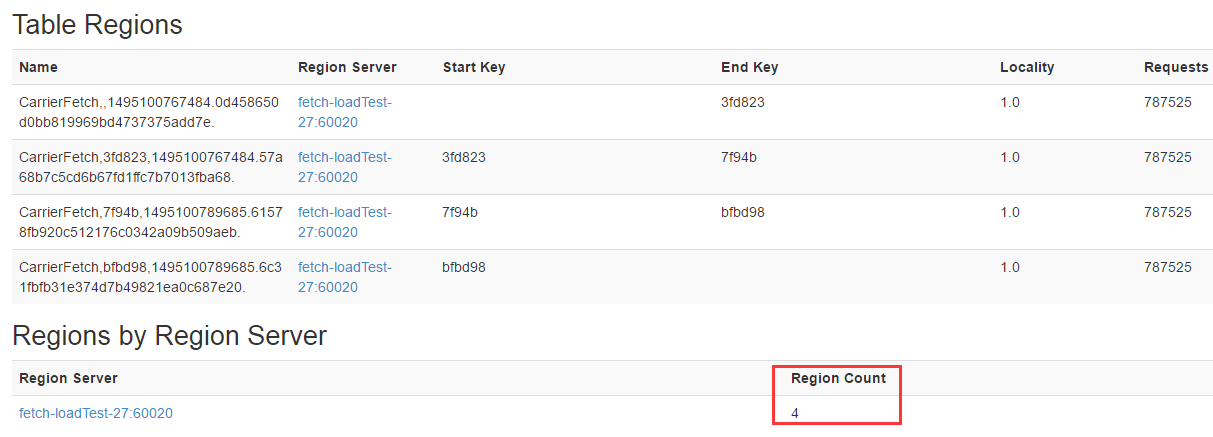
Region拆分后
六、管理Streaming任务
这是Spark Streaming系列博客的最后一部分,主要讲一下我自己对Spark Streaming任务的一些划分,还有一个Spark Streaming任务的邮件监控。
6.1 Streaming 任务的划分
当Spark Streaming开发完成,测试完成之后,就发布上线了,Spark Streaming任务的划分,以及时间窗口调试多少这些都是更具业务划分的。
- kafka 一个topic对应HBase里面的一张表
- Kafka topic 里面的partition(3-5个不等)
- Streaming job即Kafka消费者,消费一个或多个Kafka topic
那一个Streaming消费者到底去对应哪些topic呢?还有为什么这么划分,以及这样划分有什么好处呢?
- 因为kafka topic对应了业务中的具体HBase表,然后就通过监控HBase表插入流量来判断该表插入情况
- 对于HBase表数据的插入量划分了5种,插入量特别大、插入条数多每条数据量不大、每次插入数据量少数据大、比较均匀、插入少不频繁
- 对于插入量特别大,比如该表都占了插入总量的10%、20%的这种就独立出来一张表对应一个streaming消费者
- 插入条数多每条数据量不大,就是把插入比较频繁的可以放在一起,这时候可以调小timeWindow
- 每次插入数据量少数据大,就是可以看见插入每次都是1000条,2000条,有些时间间隔,就可以调大timeWindow时间间隔,maxRatePerPartition设置大一点
- 比较均匀就好办了,很好设置参数
- 插入少不频繁,可以调大timeWindow到几秒,甚至太少,太不频繁可以继续调大
- 好处大家应该也看出来了吧,资源的合理利用,对streaming的优化,timeWindow、maxRatePerPartition对应不同表,增加和控制了并发量
6.2 Streaming任务的监控
对于Spark Streaming job的监控,自带的Streaming UI能看到具体的一些流量,时间等信息,但是缺少了一个通知,于是简单的开发了一个。在监控这一块也想了不少方案,比如监控pid,通过shell去监控,或者直接调用源码里面的方法,都尝试过,有的要么没达到预期的效果,要么有的不是很好维护开发成本高。
最终选了一个比较简单的,但是又能达到一定效果的,通过py爬虫,到原始的streaming UI界面去获取到具体的信息,来监控,到达阈值就发送邮件,总体步骤如下:
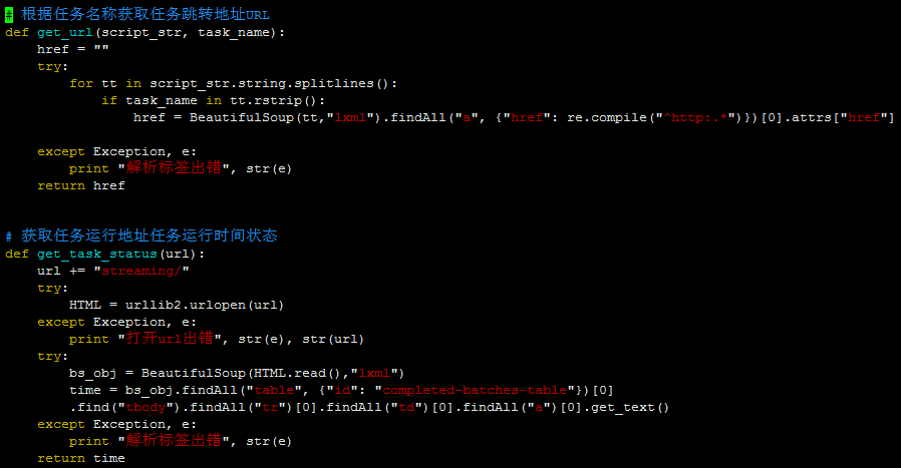
- 通过job name在yarn 8088界面/cluster/apps/RUNNING找到ApplicationMasterURL地址
- 然后通过该地址到streaming界面监控具体Streaming job的Scheduling Delay、Processing Time值
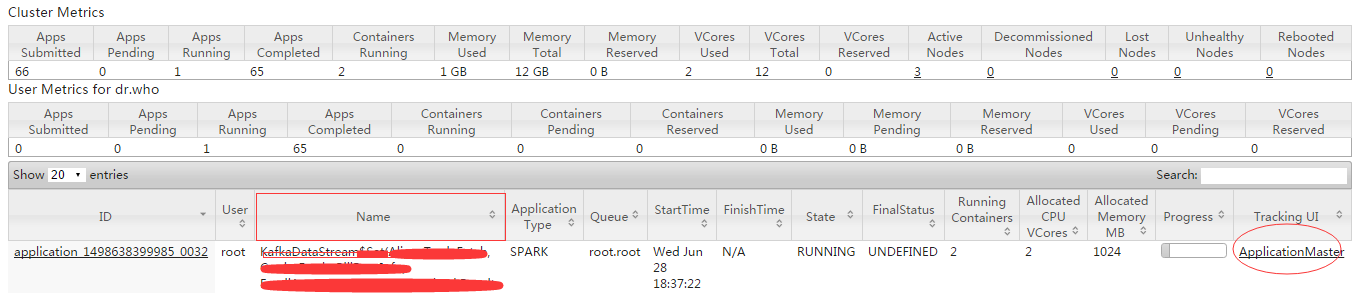
yarn 8088界面/cluster/apps/RUNNING
具体代码:
Python 监控爬虫 邮件通知
更多精彩,欢迎关注CSDN大数据公众号!
















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









