






初步了解了一下bert模型,并在电脑运行,我电脑计算资源不行好几年前的i5(网上搜到的说要10G显存),原本数据集有7000多组数据,我只用了100多组,运行了大约20min左右,在验证集上的准确率是0.68(之后又试了一次,没这么高了).已经挺不错的了,毕竟我用的训练数据太少了,等我多训练一点数据,再来更新一下图。
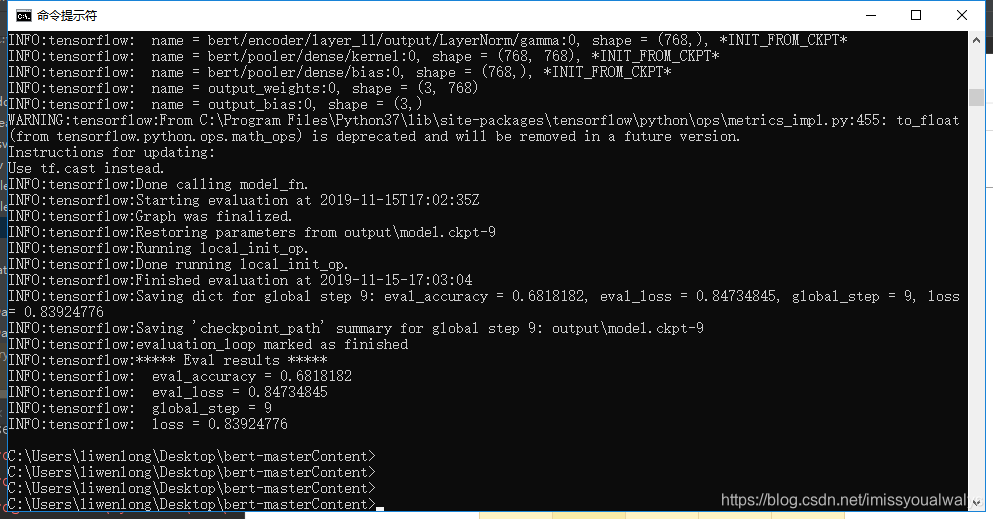
运行bert模型做情感分类主要步骤:
- 下载bert源码(https://github.com/google-research/bert)
- 下载google的预训练模型(chinese_L-12_H-768_A-12.zip),放到bert项目文件中(此链接是中文模型)
- 修改run_classier.py文件,添加我们自己数据的处理类
- 将数据放到bert项目文件中
- 运行(需要用数据先训练自己的模型,才能进行分类任务)
我的环境:tensorflow 1.x (需要>=1.11.0),python3,开发工具 :Pycharm
项目目录结构
以CCF大数据竞赛题目,互联网情感分析为例子,题目中只给了训练集和测试集,首先先对训练集两个文件做关于id的映射,再去除训练集和测试集合的多余符号,将title字段和content字段合并,划分训练集和验证集,预处理代码和数据如下:
链接:https://pan.baidu.com/s/1TF0i6hq-5ndXb3WBPb4wEg 提取码:04le
数据预处理非常重要,处理的好,可以使结果提升好多,开始一点不会,对pandas的函数了解太少,照着大佬的github敲的,挨个函数语句debug的,预处理最好能写个模板,之后可以直接套。我咋能这么菜,哈哈,参考链接放在了文章最后。
1. 修改代码
对于情感分类任务而言,只需要修改run_classier.py文件,在run_classier.py文件中,有几种processor类,用来处理某几种数据的输入,例如MnliProcessor类,这都是适用于某些特殊数据集的,我们可以根据其结构,写我们数据自己的processor类,参考MnliProcessor类,我们需要实现以下方法:
def get_train_examples(self, data_dir): 读取训练集
def get_dev_examples(self, data_dir): 读取验证集
def get_test_examples(self, data_dir): 读取测试集
def get_labels(self, labels): 获得类别集合
def _create_examples(self, lines, set_type): 生成训练和验证样本,做测试时生成测试样本
代码如下:
class MyTaskProcessor(DataProcessor):
"""Processor for my task-news classification """
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, 'train.tsv')), 'train')
def get_dev_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, 'val.tsv')), 'val')
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, 'test.tsv')), 'test')
def get_labels(self):
return ["0", "1", "2"]
def _create_examples(self, lines, set_type):
"""create examples for the training and val sets"""
examples = []
for (i, line) in enumerate(lines):
guid = '%s-%s' %(set_type, i)
print(guid)
#id:line[0] content: line[1] label: line[2]
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[2])
examples.append(InputExample(guid=guid, text_a=text_a, label=label))
return examples
这段代码我也参考过一下其他博客,在参考链接中,对于def_create_examples函数这样写我开始不能理解,训练集和验证集都是有监督的,即有文本,有标签label,而测试集是只有文本,没有label的(是需要我们通过训练的模型,输入文本得到label的,可以看各大竞赛数据集中的test数据集),那在执行测试时(运行分为训练和测试,详见下文),label从何而来,其实是本文中的test数据集已经提前做了处理,提前加了标签(已有的标签0 1 2随便加,我将测试集label全标记为0),我的数据集第一列是id,第二列content,第三列是label,测试集数据样例如下:
00005a3efe934a19adc0b69b05faeae7 九江办好人民满意教育近年来九江市紧紧围绕人本教育公平教育优质教育幸福教育的目标努力办好人民满意教育促进了义务教育均衡发展农村贫困地区办学条件改善目前该市特色教育学校有所青少年校园足球水平领跑全省该市大力推进义务教育均衡发展素质教育成果丰硕公办幼儿园占比为普惠性幼儿园覆盖率达到学前三年毛入园率达入园难入园贵得到有效缓解浔阳区等个县市区顺利通过义务教育发展基本均衡县国家认定去年月九江一中获评全国未成年人思想道德建设工作先进单位同文中学双峰小学和九江小学获评第一届全国文明校园该市切实改善义务教育学校特别是农村学校办学条件努力缩小城乡教育差距近年累计投入资金近亿元新建改建和扩建校舍面积共多万平方米农村办学条件明显改善同时引进教师名培训教师万人次较好解决了城乡师资结构性缺编教师老龄化术科教师缺乏等问题为消除中职学校散小弱办学现象该市率先启动职业教育资源整合改革试点工作采取撤销合并转型共建等措施对不符合达标条件的中职学校进行整合目前全市原有的所中职学校已整合为所达标中职学校有所同时大力开展产教融合校企对接等工作年均为企业输送技能型人才多人记者何深宝 0
另一种方案是,事先不对test.csv进行处理,在def _create_examples函数中,判断是否为test集,若为测试集,就添加一列label。
修改main函数中Processor字典
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"mytask": MyTaskProcessor,##将我们自己写的数据处理类,加入字典
}
2 运行
运行代码需要添加参数
1.训练命令,进入项目文件,在命令行运行
python run_classifier.py --task_name=mytask --do_train=true --do_eval=true --data_dir=data --vocab_file=chinese_L-12_H-768_A-12\vocab.txt --bert_config_file=chinese_L-12_H-768_A-12\bert_config.json --init_checkpoint=chinese_L-12_H-768_A-12\bert_model.ckpt --max_seq_length=128 --train_batch_size=32 --learning_rate=1e-5 --num_train_epochs=3.0 --output_dir=output
下面是一些参数的意思:
| 参数 | meanings |
|---|---|
| taskname | main函数字典中MyTaskProcessor的key值,如我们代码中的mytask |
| do_train | 是否做训练 (true or false) |
| do_eval | 是否做验证 |
| do_predict | 是否做测试 |
| data_dir | 存放数据集的文件夹 |
| output_dir | 输出结果文件夹 |
| 可变参数 | meanings |
| max_seq_length | 输入文本序列的最大长度,也就是每个样本的最大处理长度,多余会去掉,不够会补齐。最大值512。 |
| train_batch_size | 训练模型求梯度时,批量处理数据集的大小。即每次训练在训练集中取batchsize个样本训练,值越大,训练速度越快,内存占用越多。 |
| eval_batch_size | 验证时,批量处理数据集的大小。同上 |
| predict_batch_size | 测试时,批量处理数据集的大小。同上。 |
| num_train_epochs | 迭代次数,1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被轮几次。 |
| learning_rate: | 反向传播更新权重时,步长大小。值越大,训练速度越快。值越小,训练速度越慢,收敛速度慢,容易过拟合。迁移学习中,一般设置较小的步长(小于2e-4) |
| save_checkpoints_steps | 检查点的保存频率。 (我没有用到) |
2.测试命令
python run_classifier.py --task_name=mytask --do_predict=true --data_dir=data --vocab_file=chinese_L-12_H-768_A-12\vocab.txt --bert_config_file=chinese_L-12_H-768_A-12\bert_config.json --init_checkpoint=output --max_seq_length=128 --output_dir=output
训练命令运行完后,会在output文件夹中得到模型,训练命令运行完后得到的结果如下,在test_results.tsv文件中:
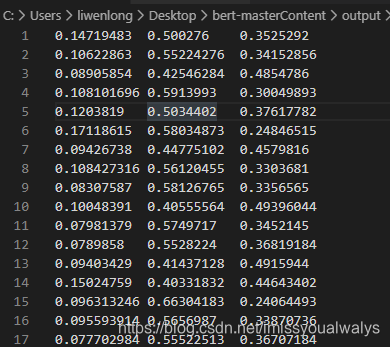
3 结果分析处理
m行n列表示第m个测试数据,对n种分类标签的概率,哪个值大我们就默认分类结果是哪个,(我这个效果明显很不好,非常不好,100组训练数据也就这样了,等我再训练多一点数据,放个效果好一点的图),运行get_results.py在output文件中得到最终对测试集的分类结果。
我的代码:https://github.com/nameluck/bert-
TodoList
- 使用多点训练集
- 调整可变参数
- 对数据集处理,去除停用词,对title和content不再进行简单合并
- 是否可以和Lstm相结合反正改的地方太多了,先提交一版吧
参考博客:
https://github.com/DefuLi/Emotional-Analysis-of-Internet-News/tree/master/CCF_NewsSenAna本篇主要参考了数据预处理代码
https://blog.csdn.net/qq874455953/article/details/90276116
https://blog.csdn.net/renxingkai/article/details/87605693
https://blog.csdn.net/pirage/article/details/85164063
https://blog.csdn.net/qq_43012160/article/details/102767508














 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









