






提示:相信你应该成功安装了CUDA,正式开启深度学习环境配置的部分
前言
理论上来说,安装完CUDA后已经可以进行深度学习框架的部署了,如pytorch
、tensorflow等,但是针对于深度学习的加速运算,nvidia公司开发了一套专门用于GPU训练加速的算法库——CUDNN。这大大加快了我们的处理速度,所以我们也要继续安装一下
一、CUDNN是什么?
官方介绍:
NVIDIA® CUDA® 深度神经网络库(cuDNN)是一款 GPU 加速的深度神经网络基础算子库。cuDNN 为标准操作(如前向和反向卷积、注意力、矩阵乘法(matmul)、池化和归一化)提供高度优化的实现。
目前,我们绝大部分的深度学习模型绕不开的就是卷积、注意力机制、矩阵计算等,可见CUDNN库的重要性。
更多介绍大家可以去官网进行查看https://developer.nvidia.cn/cudnn
我们还是着重去讲述如何安装
二、安装步骤
前期准备
请注册一个nvidia开发者账号,当你下载cudnn时,需要经过账号验证方可下载
 注册步骤就不多讲了,接着往下
注册步骤就不多讲了,接着往下
选择一个合适的cuDNN版本
欸嘿~,这个步骤是不是看着非常熟悉?
没错,cuDNN也有对应的CUDA版本,但是,cuDNN的版本并不与CUDA强相关,在后面下载cuDNN库的时候,大家就会明白了。
这里我并不先进行推荐,在之前的教程中,我安装了cuda11.6和cuda12.2,这次也会将其补全对应的cudnn版本
安装方法
方法一(最为常用)
这个方法属于一力降十会的做法,让我们一起来见识一下。
当你满心欢喜地点开下载cuDNN库时,你会发现,你只能看到中国服务器的最新版本
是的你没有看错cudnn9.2.0
 那么还是一样,让我给出com版本的链接https://developer.nvidia.com/cudnn
那么还是一样,让我给出com版本的链接https://developer.nvidia.com/cudnn
同样点击download后,进入下载界面
 当当当~,9.14.0版本
当当当~,9.14.0版本
我们仍然可以不安装最新版本,而是点击历史版本
 与CUDA下载一样熟悉的界面,聪明的你一定知道如何去找CUDA的下载界面了
与CUDA下载一样熟悉的界面,聪明的你一定知道如何去找CUDA的下载界面了
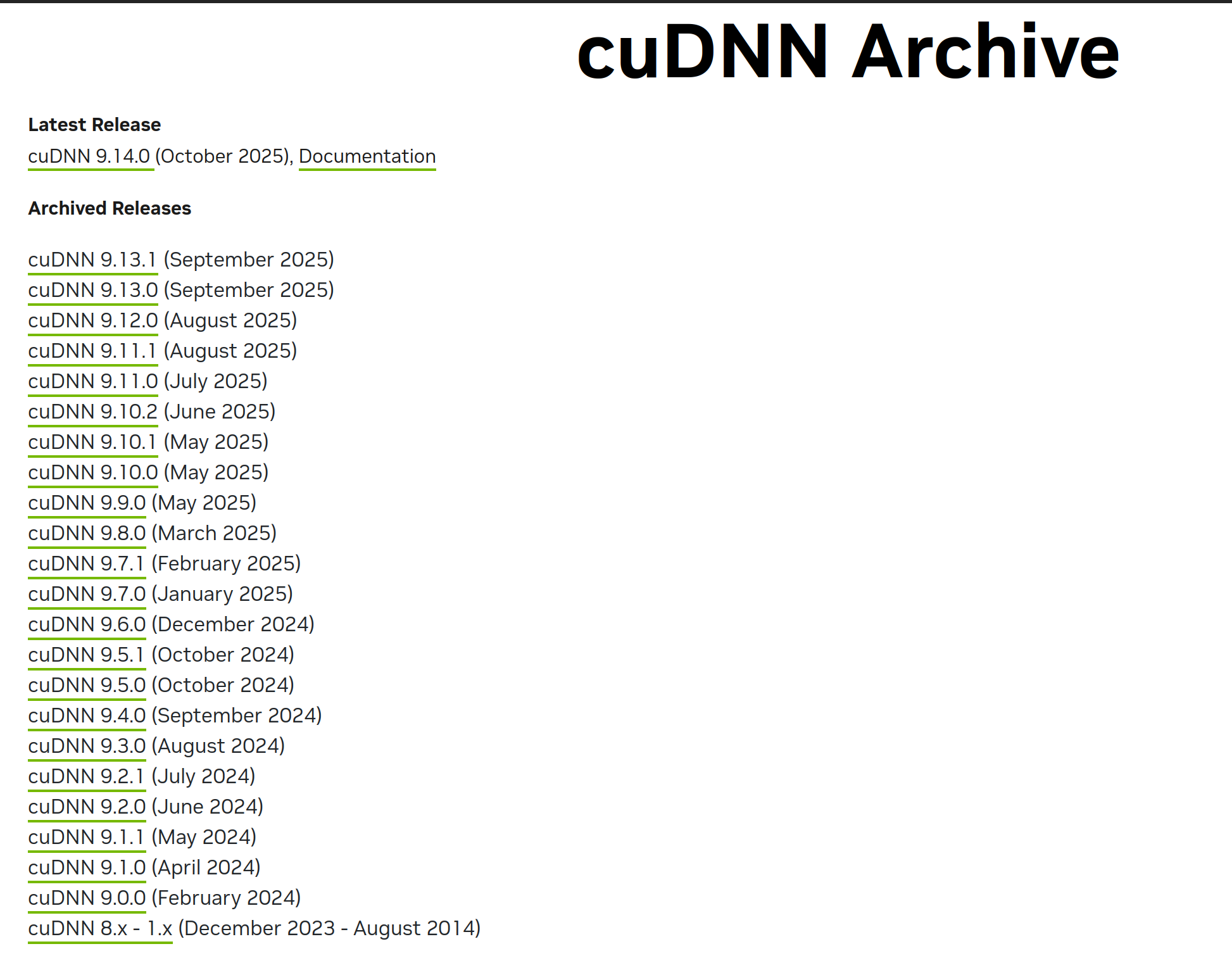 进入到页面之后,我们仍然不知道如何确定cuDNN版本。
进入到页面之后,我们仍然不知道如何确定cuDNN版本。
没关系,让我们先看看cuDNN9.13.1版本的界面
 点开页面发现,cuDNN9.13.1压根就没有ubuntu20.04的选项。这时候你就应该明白了,我们只需要去找到适配ubuntu20.04的版本即可
点开页面发现,cuDNN9.13.1压根就没有ubuntu20.04的选项。这时候你就应该明白了,我们只需要去找到适配ubuntu20.04的版本即可
不信邪的我点到了最后的cuDNN8.x-1.x
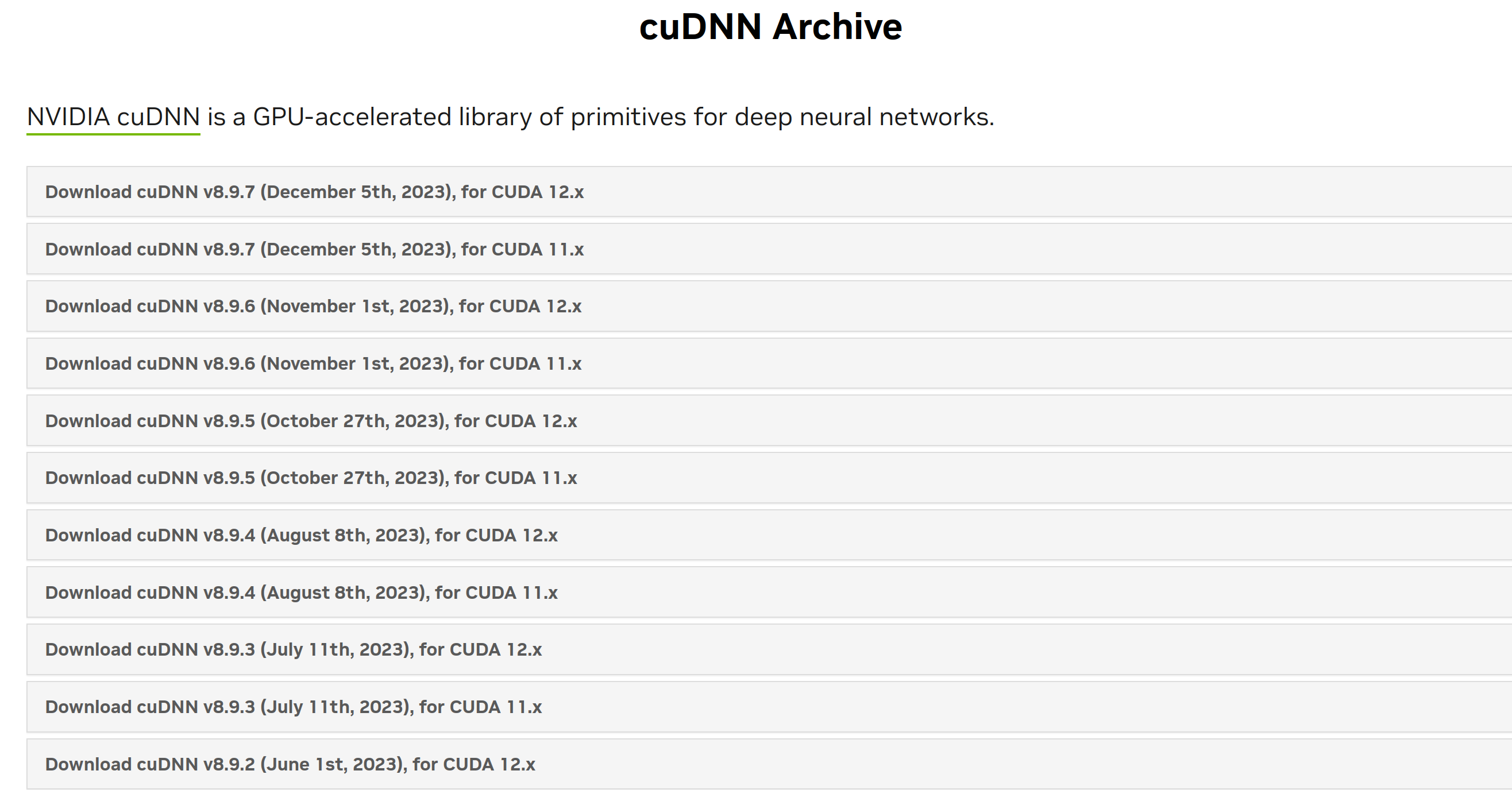 发现突然又跳出来一个下载选项,这是为什么呢?
发现突然又跳出来一个下载选项,这是为什么呢?
让我们点开任意一个包查看(注意CUDA12.X和CUDA11.X的区分哦,这是唯一对应CUDA版本的区别)
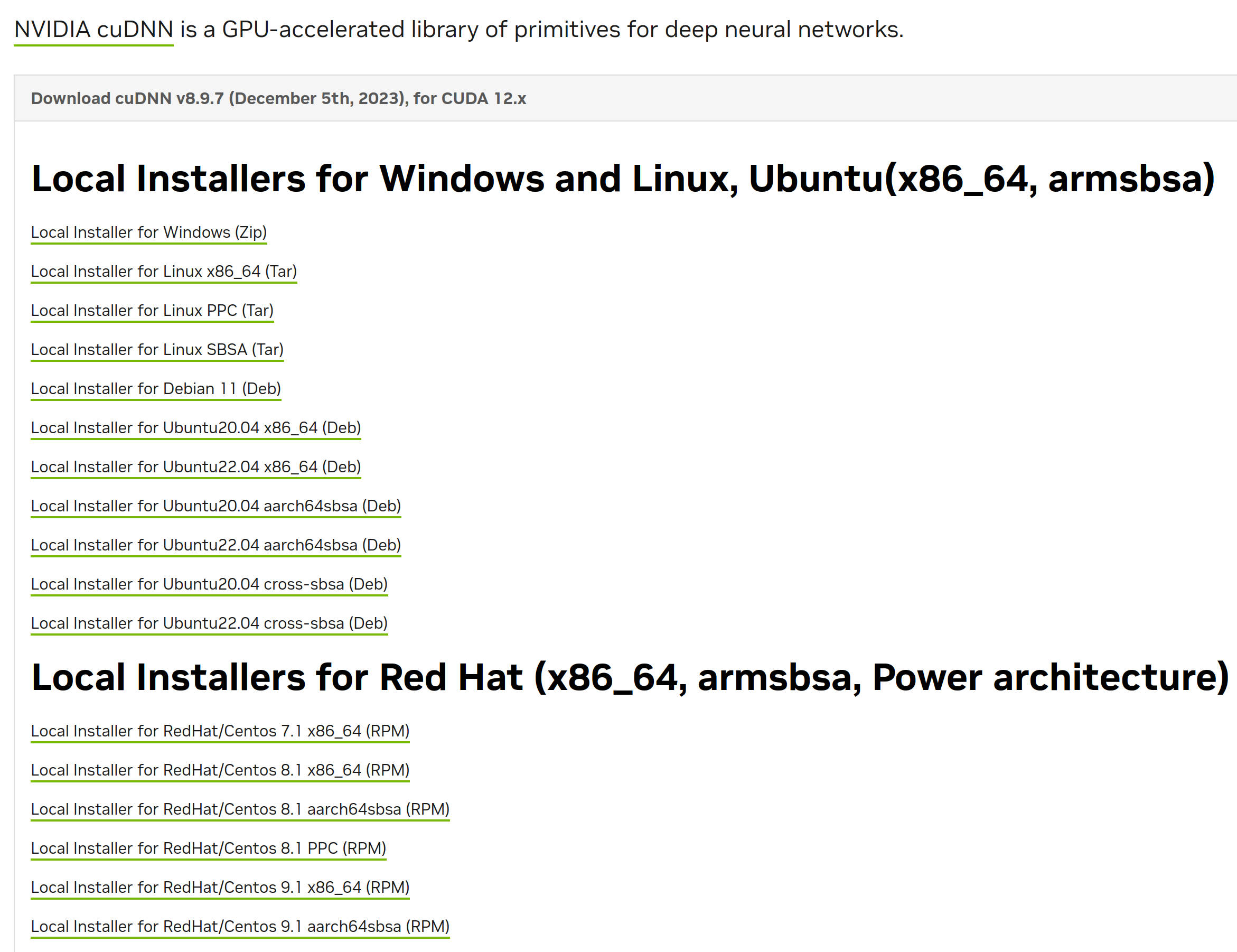 这时候就很容易发现,其实之前看到较新的版本的安装按钮变成了这种选择。
这时候就很容易发现,其实之前看到较新的版本的安装按钮变成了这种选择。
那么其实,由于我之前一直玩的是B01,它的cudnn版本一直没有超过9,因此我一直使用cudnn8.6或者cudnn8.9。
并且大家可以看到,这里的安装选项有一个linux_x86_64和Ubuntu20.04x86,我们应该选择哪一个。
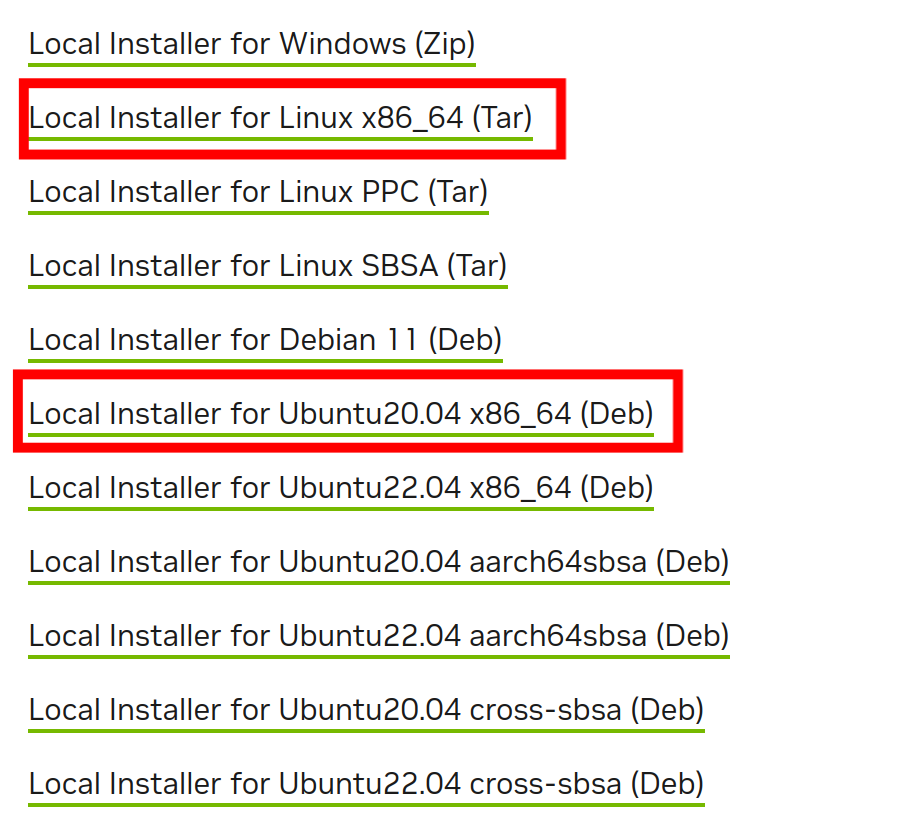 这里我其实更加推荐使用linux_x86_64的选项。原因是为什么,大家可以继续看下去
这里我其实更加推荐使用linux_x86_64的选项。原因是为什么,大家可以继续看下去
*点击下载后,会跳转一个登录界面,此时我们前期准备就有用了
登陆之后会向注册邮箱发送邮件,大家打开邮件点击验证即可

 验证后会自动下载压缩包,大小差不多快一个G
验证后会自动下载压缩包,大小差不多快一个G
 这就算下载完毕了。
这就算下载完毕了。
这时候就有人要问了,那我安装CUDA10.x版本该怎么办呢?
往下滑
在早期,的确出现了针对唯一版本CUDA的cudnn,但是随着时间的推移,除了B01等特制的镜像,已经很少有人使用CUDA10.X了,大家不要无脑因为B01的CUDA10.2从而给自己电脑也安装CUDA10.2版本,美其名曰还原实验真实性,这个是完全没有必要的,训练和部署是两个概念
现在我们下载好了cudnn,那么如何安装cudnn呢?
首先我们需要对压缩包进行解压

tar压缩包是linux系统独有的压缩方式,它相比通用的ZIP压缩方式可以借助linux独特的文件存储系统做到进一步压缩。
首先让我们仍然打开终端
这里就要说一下了,如果你使用快捷键打开终端,那么默认所处的位置是主目录的位置,cudnn的位置在下载目录,因此我们仍然有两种方法,一种是剪切到主目录,另一种是让我们进入到下载目录。
- 进入下载目录的方式又分两种,你可以在终端中使用cd命令进入
- 或者在下载文件夹的空白处右键使用终端打开
这时候就有人要问了,我不能像windows系统一样使用右键然后解压文件么?
当然可以,但是你都用linux了,不多学一学linux命令?
用鼠标?Low!!!
解压命令
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
不清楚-xvf是什么意思的话,可以自己下去搜索tar命令的用法,我不可能都给你讲到对吧
这里讲一个小技巧,当你已经非常熟练这个命令的时候,在cudnn文件名的时候,在cu后之间按一下Tab键,可以补全整个文件名,至于为什么,自己下去研究
注意,我文章中说到下去搜索或者下去研究的时候,都是默认大家确实去学习掌握了,后面别说看不懂命令了,说明没研究明白
经过一大堆输出后就可以看到已经解压出来的文件夹里面只有include文件夹和lib(或者lib64意思一样)文件夹
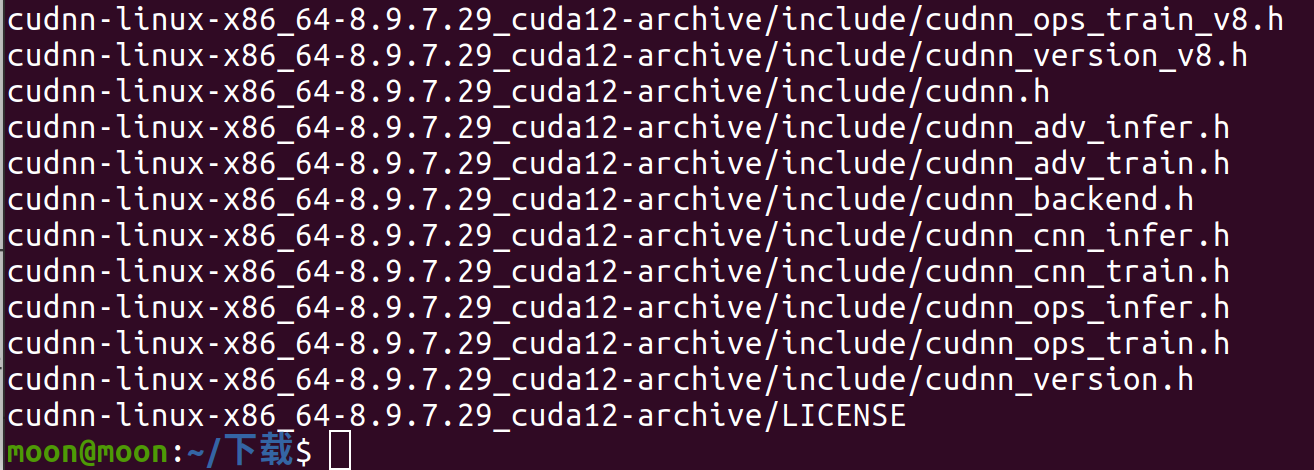


这就安装完了?
很显然不是,这里就要给大家说明一下,cudnn只是一个算法库,说白了就是cudnn本质其实是一个NVIDIA面向深度神经网络的加速库(类似组件化SDK),只提供深度学习算子的高性能实现与头文件接口,并不包含独立的运行程序或驱动。按“头文件+库文件”分发即可被灵活集成与复用
这个时候让我们打开之前安装的CUDA12.2文件夹
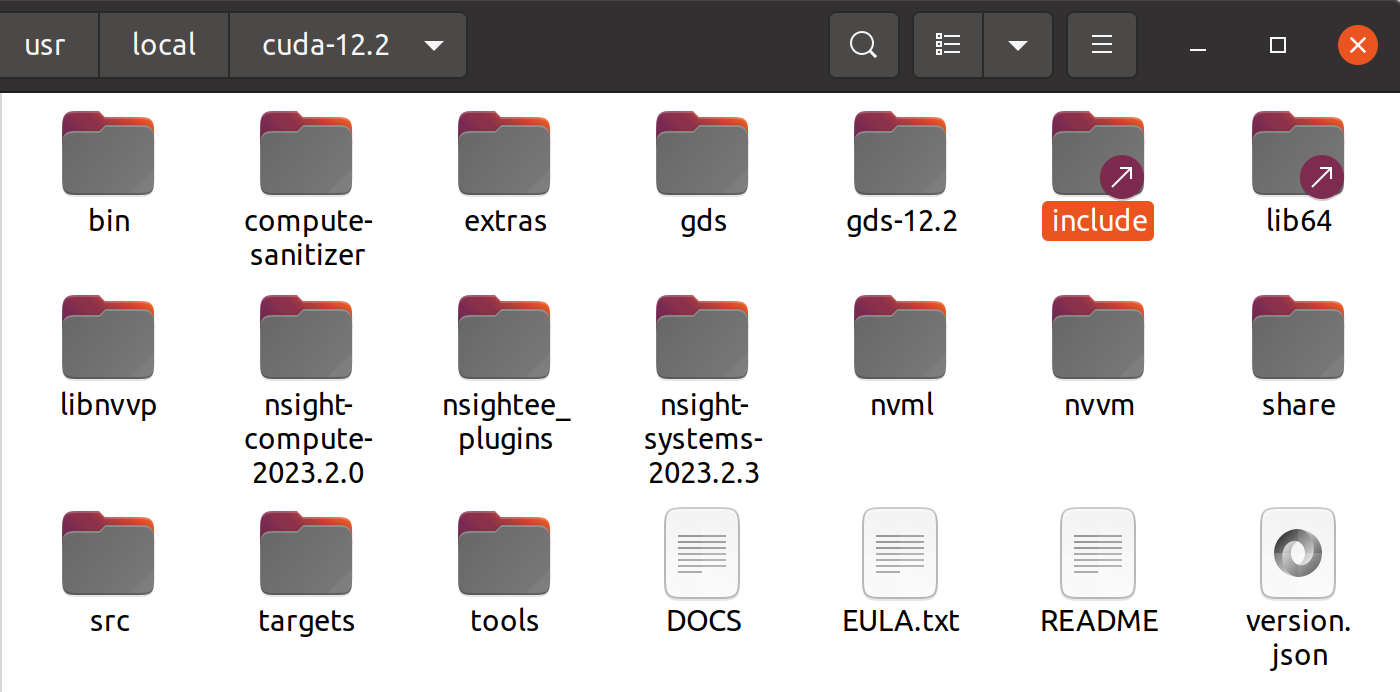 这里可以发现,有同样的inclde文件夹和lib64文件夹。
这里可以发现,有同样的inclde文件夹和lib64文件夹。
那我们要做的就是,将cuidnn文件夹中的lib和include复制粘贴到cuda12.2文件夹中,即可完成对cuda12.2的对应cudnn安装!!!
胜利的方程式已经建成,都鲁!
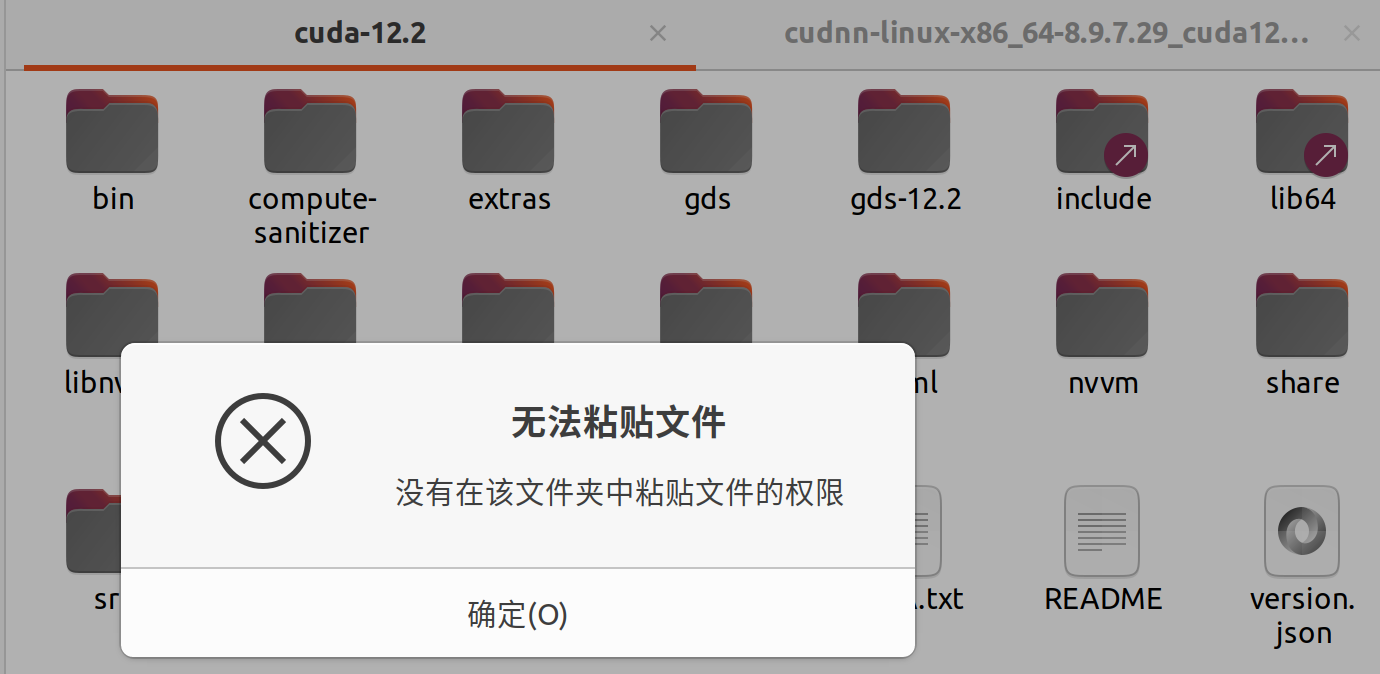 那尼?
那尼?
额,之前就说过,linux非常注重权限,因此对除主目录以外的其他根目录文件都需要管理员权重,而快捷键或者鼠标操作其实都是属于用户操作,因此我们只能使用cp或者mv命令进行操作
进入cudnn目录(这里指用终端进入),输入命令(第一个命令运行时间较长)
sudo cp lib/* /usr/local/cuda-12.2/lib64
sudo cp include/* /usr/local/cuda-12.2/include
此时,CUDA12.2中的接口已经更新完毕了,这就结束了么?
还记得我说过,环境变量更新之后需要更新么?没错,这里也要进行更新,更新命令
sudo ldconfig
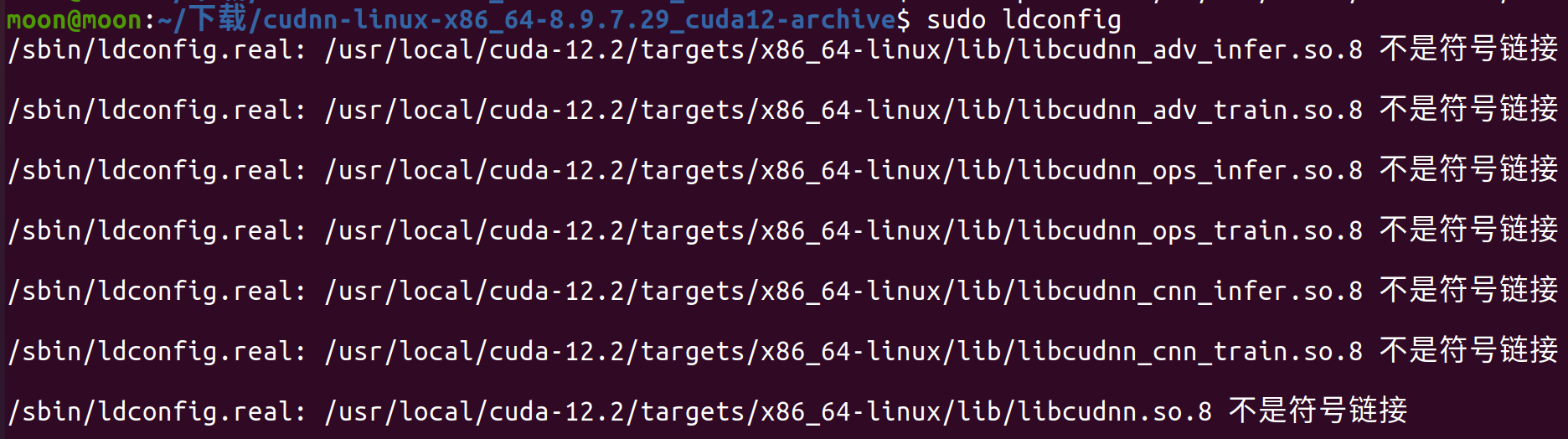
如果你一直是看着我的教程的话,那你就会出现这个软链接错误。
问题出现的原因这里可以展开来说一下
- ldconfig是 Linux 系统用来管理动态链接库(.so 文件)搜索路径与符号链接的工具。它会扫描 /etc/ld.so.conf中指定的目录(比如 /usr/local/cuda-12.2/lib64或类似路径),并为其中的 共享库(.so 文件) 建立缓存,以加快程序运行时查找库的速度。这里表明 .so.8文件是一个实实在在的、独立的动态库文件,而不是一个指向其他版本库的“符号链接(symbolic link)。
嘶~/etc/ld.so.conf好熟悉的东西。
没错,当你安装CUDA时,就曾提示过要将CUDA路径放到这里去。所以你是否可以针对性的进行优化呢?这个交给大家
- 这时候我们查看一下cuda12.2里面关于cudnn的所有的.so文件的详细信息
ls -l /usr/local/cuda-12.2/lib64/libcudnn*.so.8*
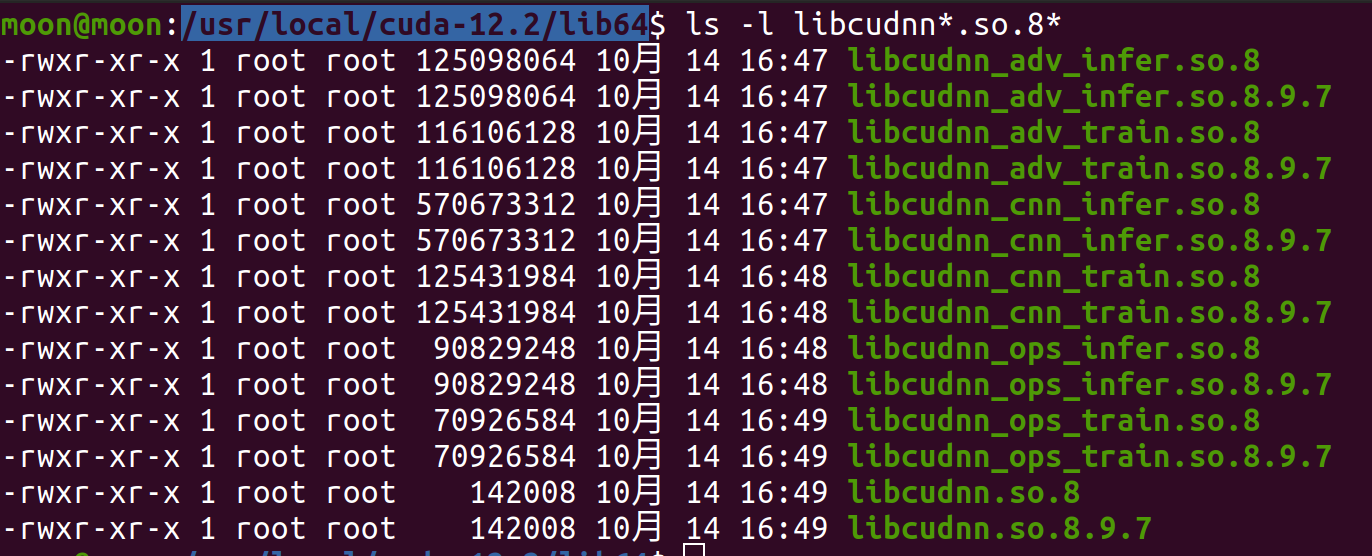
- 输出提示的符号链接是什么?
这里你也可以认为i是一种快捷方式在linux中叫软链接,可以通过访问该链接去访问其真正指向的文件。也就是说其实我们希望的是,8->8.9.7。对比没有安装那个cudnn的cuda11.6的话就会发现,这些文件都来自于我们安装的cudnn。
总上所述,我们需要将.so.8全部指向对于的.so.8.9.7。这就需要用到linux创建软链接的命令,在进入lib64的前提下
sudo ln -sf libcudnn_adv_infer.so.8.9.7 libcudnn_adv_infer.so.8
sudo ln -sf libcudnn_adv_train.so.8.9.7 libcudnn_adv_train.so.8
sudo ln -sf libcudnn_ops_infer.so.8.9.7 libcudnn_ops_infer.so.8
sudo ln -sf libcudnn_ops_train.so.8.9.7 libcudnn_ops_train.so.8
sudo ln -sf libcudnn_cnn_infer.so.8.9.7 libcudnn_cnn_infer.so.8
sudo ln -sf libcudnn_cnn_train.so.8.9.7 libcudnn_cnn_train.so.8
sudo ln -sf libcudnn.so.8.9.7 libcudnn.so.8
sudo ln -sf libcudnn.so.8 libcudnn.so
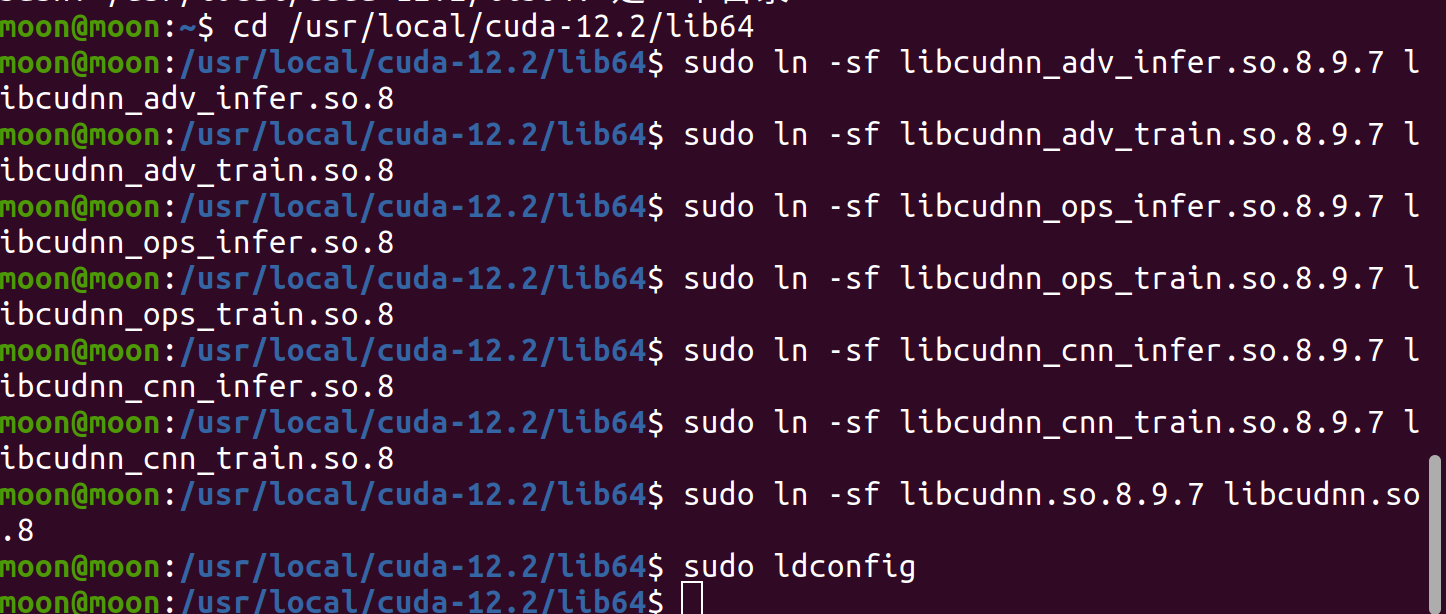 再次更新共享库就不会有输出了。
再次更新共享库就不会有输出了。
欸,这个时候就有人要问了,学长学长,有没有检验cudnn安装成功的方法呢?
这个嘛,一般来说,在你每次开启训练pytorch模型的时候都会输出你的cudnn版本,可以通过这种方式去验证。如果时间很长忘记了cudnn版本号的话,这里给出一个查看版本号的命令,大家根据自己实际情况进行修改
cat /usr/local/cuda-12.2/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

想要卸载cudnn,只需要对应删除复制的文件即可,别忘了更新共享库哦~
到此这种安装cudnn的方法就结束了,完结撒花~
方法二
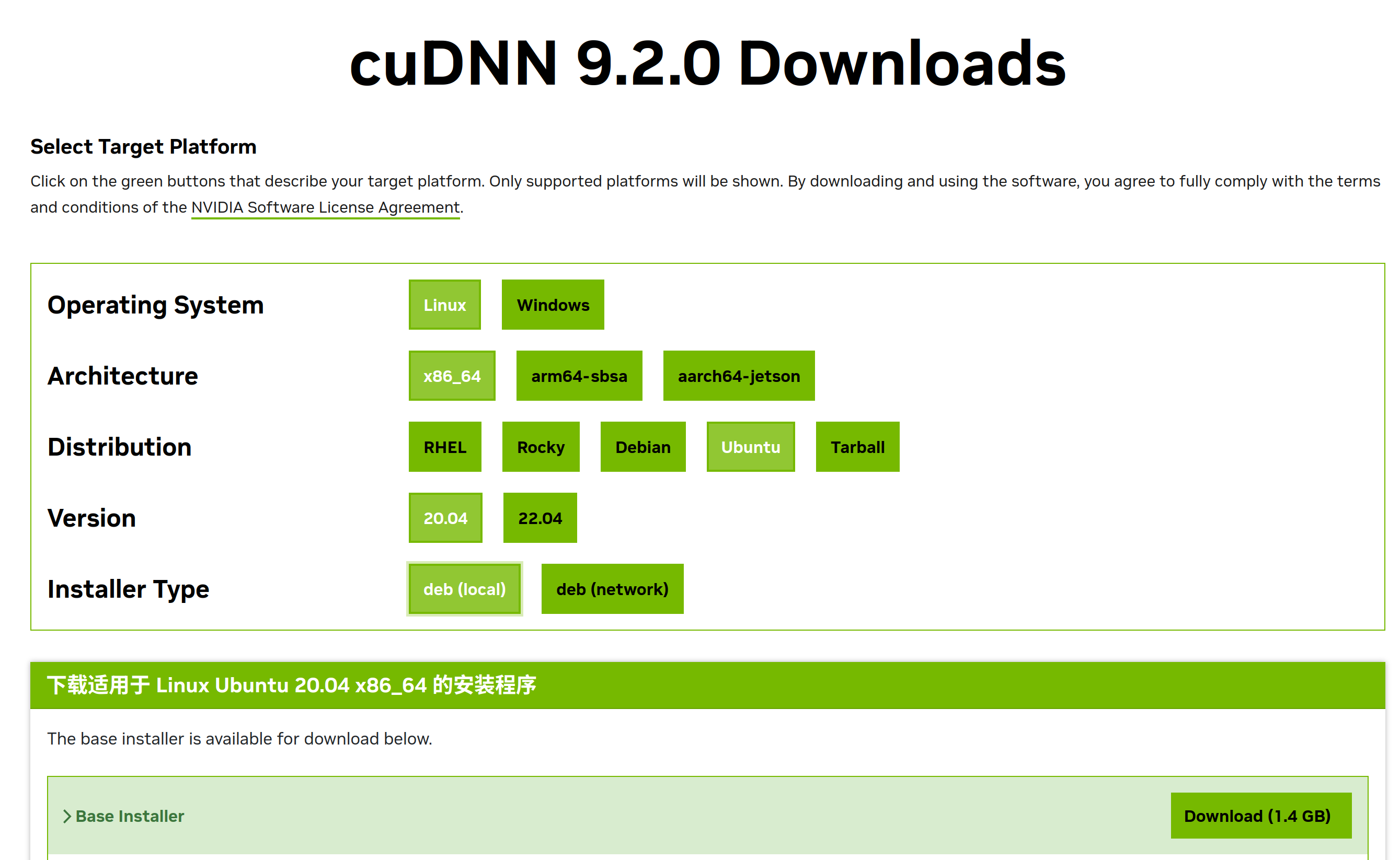
大家还记得这张图么,它展现了两种安装方法,这里讲述第二种,针对于ubuntu20.04高度适配的方法,同时也是我们开头看到的方法
这个方法是图中deb(local)的方法,顾名思义就是先下载本体,再安装依赖再安装,这里我们就以次对我们的cuda11.6进行安装我选用9.9.0
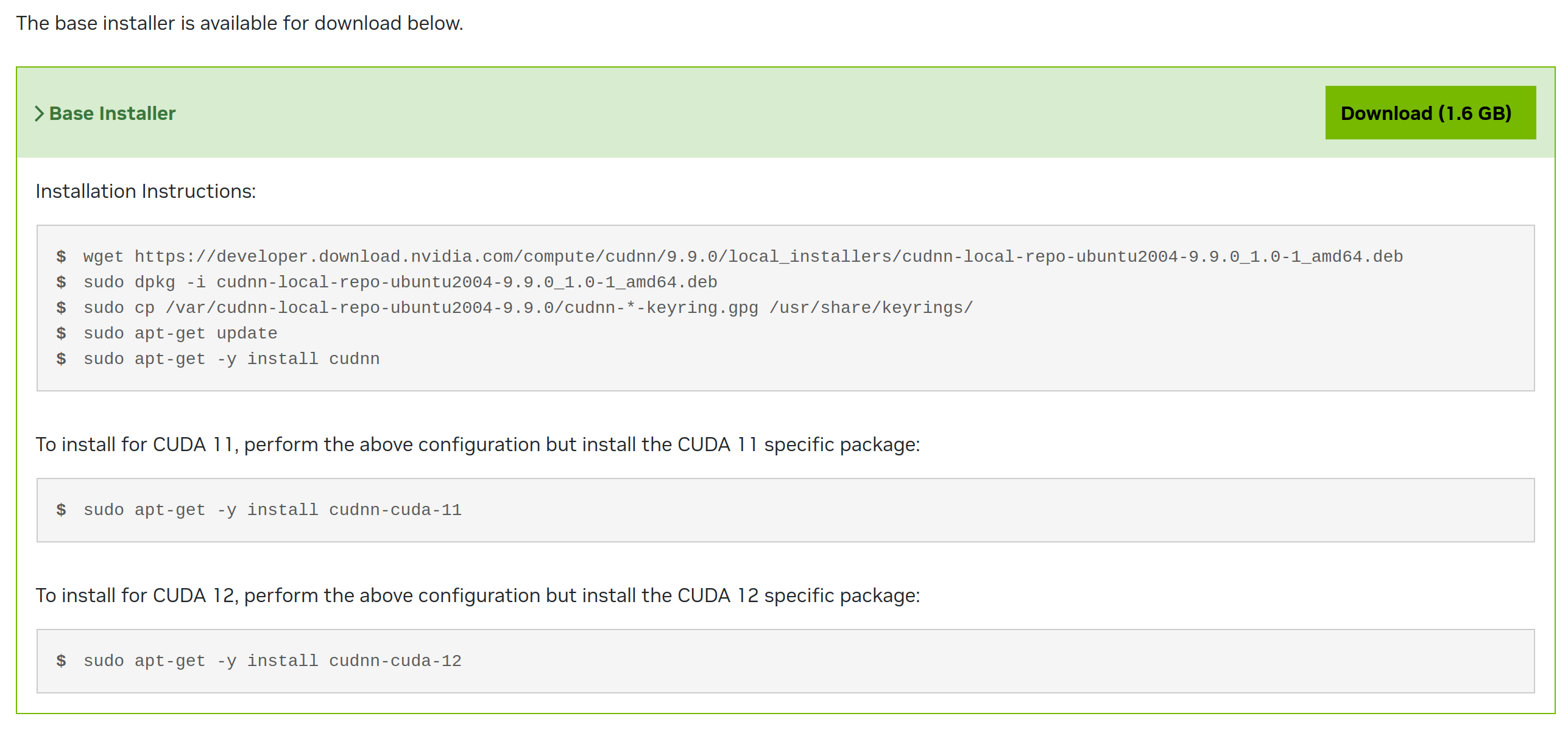
这里给出了非常详细的安装方法,包括针对于cuda11和cuda12的安装,我们跟着走就行,不过安装包的大小1.6G,解压出来应该有两个多G,比较吓人
wget https://developer.download.nvidia.com/compute/cudnn/9.9.0/local_installers/cudnn-local-repo-ubuntu2004-9.9.0_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2004-9.9.0_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2004-9.9.0/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn-cuda-11
这种以.deb包安装软件的方法其实在ubuntu系统中非常常用,并且如果你不想更改你的cudnn版本,这种deb安装的方法反而更加推荐。因为其:
-
安装简单
-
能够自动匹配 CUDA 版本
-
库文件会被安装到标准路径(如 /usr/lib/x86_64-linux-gnu/或 /usr/lib/),并被系统包管理器管理
-
可以用 apt upgrade升级 cuDNN,用 apt remove卸载,不会留下垃圾文件
-
不像 tar 包那样需要手动建软链,.deb 安装后库文件结构规范,ldconfig 不会报错
检验deb安装的命令就很简单了
dpkg -l | grep cudnn
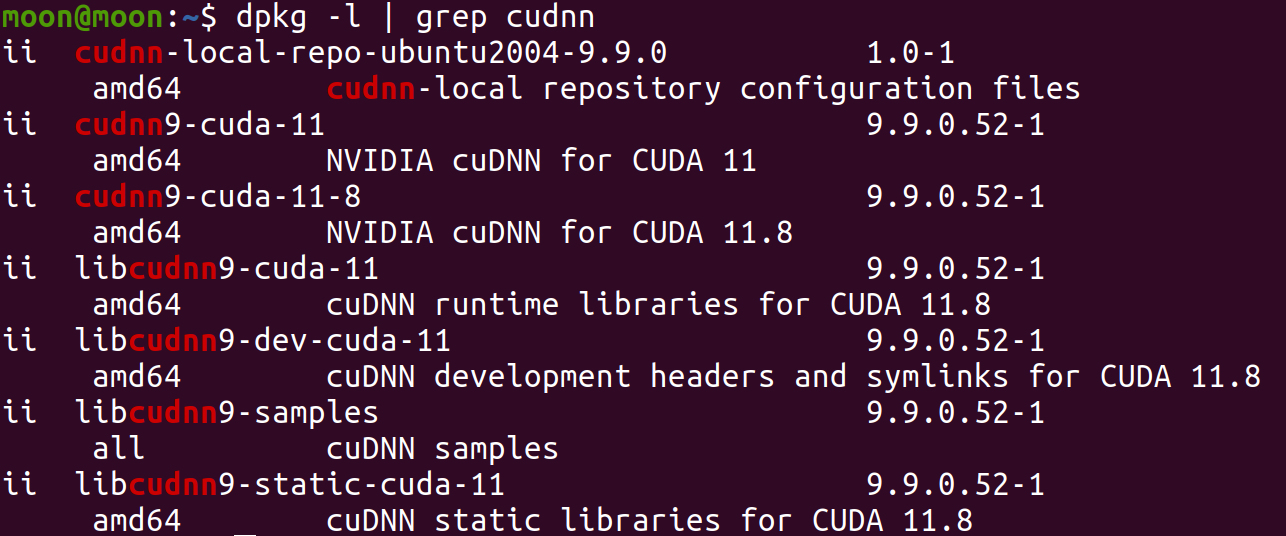
实测是可用的,但是输出显示这玩意是为cuda11.8完美适配的,我猜可能是最高支持,可以向下兼容11.6-11.8应该都行
卸载命令
```bash
sudo apt remove --purge 'cudnn*'
那么如何去测试cudnn是否能用呢,这里有一个测试案例路径在这里:
/usr/src/cudnn_samples_v9/mnistCUDNN(如果没有可以在tensorrt去验证,也是可以的)
编译前你需要先安装依赖否则会报错

sudo apt install libfreeimage-dev
在当前文件夹下输入以下命令
sudo make clean
sudo make
sudo ./mnistCUDNN
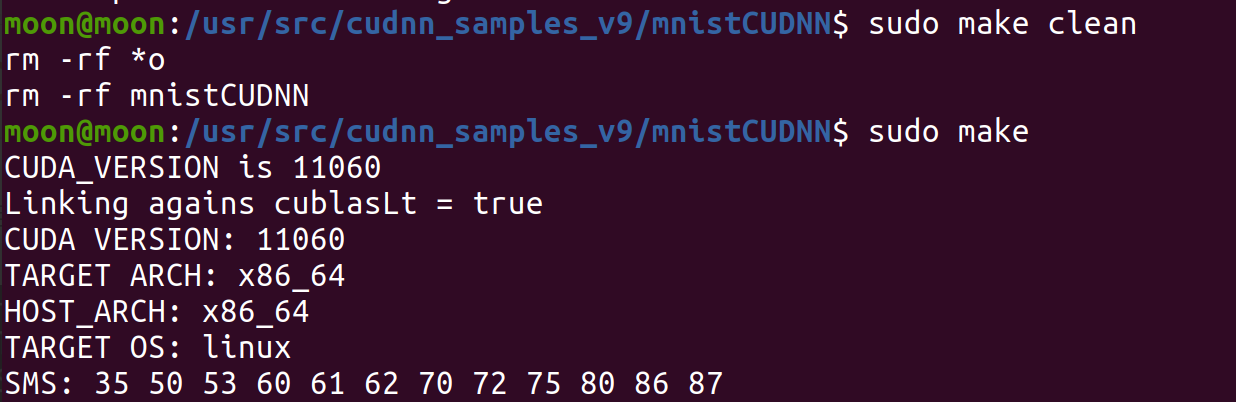
执行后就会显示当前的cudnn版本,最后会出现**Test passed!**字样
 这里涉及到了c/c++在ubuntu编译的相关知识,大家可以自己下去学习一下,程序默认链接的是cuda文件夹,如果你安装了不同版本的cuda,需要修改Makefile里面的内容改成针对性的cuda版本
这里涉及到了c/c++在ubuntu编译的相关知识,大家可以自己下去学习一下,程序默认链接的是cuda文件夹,如果你安装了不同版本的cuda,需要修改Makefile里面的内容改成针对性的cuda版本

在安装CUDA时似乎也有deb安装版本,那你是否也可以使用deb安装CUDA呢?
三、cudnn多版本共存问题
相比较两种方法,我们可以发现第二种deb安装方法显然更加简单并且与ubuntu适配度更好。那么为什么我更喜欢第一种方法
这是因为第二种方法针对单一cuda就较好的适配性,但是如果某一个软件对于cuda和cudnn版本有强依赖性,那么我们就需要卸载cudnn然后去进行适配,这个方法比较耗时。如果采用tar压缩包的安装方法,只需要复制粘贴并且创建新的软链接即可做到cudnn版本的更换。说是版本共存,但是实际上并不存在,只是消耗的前期准备时间的多少。
后来我发现应该可以通过apt去更改deb版本的cudnn不过我没有尝试过就不作评价了
总结
这里主要介绍了cudnn的不同安装方法,卸载和删除方法,以及测试方法,希望对大家有帮助,环境部署我应该还会再写一个TensorRT的,大家还想了解什么欢迎评论区留言,我就下班咯~



















 8314
8314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









