




 本文介绍了Transformer模型,它最初用于自然语言处理的机器翻译,后广泛应用于GPT领域。使用Pytorch 1.11.0简单实现该模型,详细阐述了总体结构、编码端、解码端的步骤,还说明了训练、预测方法,并展示了结果,代码有详细注释且可在Github下载。
本文介绍了Transformer模型,它最初用于自然语言处理的机器翻译,后广泛应用于GPT领域。使用Pytorch 1.11.0简单实现该模型,详细阐述了总体结构、编码端、解码端的步骤,还说明了训练、预测方法,并展示了结果,代码有详细注释且可在Github下载。
引言
Transformer中文名注意力机制,最开始应用于自然语言处理的机器翻译任务中,后来被发现此模型也可以应用于其他领域中如视觉领域,且效果也非常不错,目前广泛应用于GPT领域,是主流的深度学习模型结构之一。
本文使用简单地实现了Transformer,使用的是Pytorch版本为1.11.0,在代码中有详细的注释更能方便理解代码,本文只给出了部分代码,所有代码可以在Github中下载。
总体结构
我们由简入繁,由浅入深地对注意力机制模型进行分析,首先我们看一下他的大概框架。

以上为Transformer的结构图,其可以划分为两个部分,编码段(Encoder)(左端) 和解码端(Decoder)(右端),编码端和解码端各有一个输入,编码端的输出会和解码端的中间部分会有一个交互,中间部分我们先不管之后再介绍,最后解码端会有一个输出,这个输出会和数据集中的标签计算损失。
那么编码端,解码端的输入以及标签又是什么呢?本文以机器翻译任务为例(中译英),在机器翻译任务的数据集中会有原文以及译文,编码端的输入就是原文,其格式为 [ "原" , "文" , "P" ],解码端的输入就是译文其格式为 [ "S" , "origin" , "text" ],那标签(target)又是什么呢???其实它也是译文,但是其格式与前者有些区别,格式如下 [ "origin" , "test" , "E" ],当然我们不能直接将单词输入到神经网络,需要先将他们编码成数字矩阵再输入。
那么我们是如何将中英文编码成数字的呢?这里需要建立字库,需要遍历所有的样本将其出现的中文一对一映射到唯一的一个数字,英文也一样。Python中的字典是一个很好的实现方法。注意:需要两个字库,中文英文各一个,以及上面提到的P,S,E也需要放入字库中将其映射为一个数字(P放入中英字库,S和E放入英文字库)。实现方式如下:
# # 为了方便理解,这里手动定义训练集1
sentences = [
["你 今 晚 回 家 吃 饭 吗 P", "S Are you going home for dinner tonight", "Are you going home for dinner tonight E"],
["我 今 晚 回 家 吃 饭 P", "S I'm going home for dinner tonight", "I'm going home for dinner tonight E"],
["我 今 晚 不 回 家 吃 饭 P", "S I'm not going home for dinner tonight", "I'm not going home for dinner tonight E"]
]
# 建立中英词库
CN_glossary = {'P':0,'你':1,'今':2,'饭':3,'家':4,'回':5,'吃':6,'晚':7,'吗':8,'我':9,'不':10}
EN_glossary = {'P':0,'S':1,'E':2,"I'm":3,'Are':4,'going':5,'you':6,'home':7,
'dinner':8,'for':9,'tonight':10, 'not':11}那么“P”,“S”,“E”又代表什么呢??
先从P开始,P代表PAD填充,因为我们需要将原文和译文以矩阵的形式输入网络,而每个样本的原文和译文长度都有可能不同,若每一行代表一个样本那么可能会发生这样一种情况:若设置的batch_size为2且第一行有5个数字而第二行有7个数字,这样无法使他们构成一个矩阵,这时我们就需要使用PAD对第一个句子进行填充,使输入变为一个2*7的矩阵。所有的句子或者是同一个Batch的句子长度相同,这样他们才能构成一个矩阵输入到网络。
接下来是解码端输入部分的S,S其实就是Start的缩写代表译文的开始部分。这里先剧透一下,在翻译时我们需要根据原文和前面已经翻译的内容一步一步生成后面的部分,而最开始我们只有原文啊,没有译文啊,难道解码端就不用输入了吗,那肯定不行,所以就都从S符号代表的数字开始输入,根据原文一个字一个字地生成译文,生成的译文的一个数字代号会添加到S的后面作为新的输入,再输入到解码端,一直循环,直到模型输出E代表的数字为止,否则会一直生成。那么也很好猜了,E就代表结束,是End的缩写。
了解了P,S,E之后就可以将数据集编码成Transformer所需要的输入形式了,同样以上面的三句话为例,假设batch_size为3,可以看到这三句中文中最长的那句话长度为9(包括P),那么就需要对短一点的句子往后填P,则最终输入到网络编码端的Tensor的shape为[3, 9],同样的输入到解码端的Tensor的shape为[3, 8],target也是[3, 8]。
Transformer总体框架代码如下:
class Transformer(nn.Module):
def __init__(self, device, len_CNvocabulary, len_ENvocabulary, d_model, dff, n_head):
super(Transformer, self).__init__()
self.len_vocabulary = len_ENvocabulary # 字库大小
self.device = device
self.encoder = Encoder(device, len_CNvocabulary, d_model, dff, n_head) # 编码端
self.decoder = Decoder(device, len_ENvocabulary, d_model, dff, n_head) # 解码端
self.Projection = nn.Linear(d_model, len_ENvocabulary) # 对网络输出进行映射
def forward(self, encoder_input, decoder_input):
"""
encoder_input.shape -> [batch_size, len_sen1]
decoder_input.shape -> [batch_size, len_sen2]
final_output.shape -> [batch_size*len_sen2, len_vocabulary]
"""
output1 = self.encoder(encoder_input)
output2 = self.decoder(decoder_input, encoder_input, output1, output1)
final_output = self.Projection(output2).view(-1, self.len_vocabulary)
return final_output编码端
知道了输入后,就开始分析编码端了(上图左侧),大致流程为:
1、进行word Embedding 后加入位置编码
2、进行不带序列mask(含有PADmask)的多头自注意力机制后再进行归一化和残差连接
3、输入前馈神经网络后再归一化和残差连接
4、二,三步重复N次,在论文中为6次
第一步
word Embedding就是使用一个向量来表示一个单词或token,根据论文,向量维度为512维,我们使用 torch.nn.Embedding(len_vocabulary, d_model) 来实现此功能,其中len_vocabulary为词库的大小,以上面的句子为例,在编码端就是中文词库的长度=11,d_model就是512,经过词编码层后数据的维度变为[3, 9, 512]。
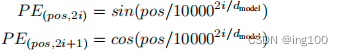
然后就是位置编码,其公式如上图所示。pos代表这是数据集的第几个字,i代表这是512维中的第几个维度,我们可以作一下小小的数学变换,变成如下形式
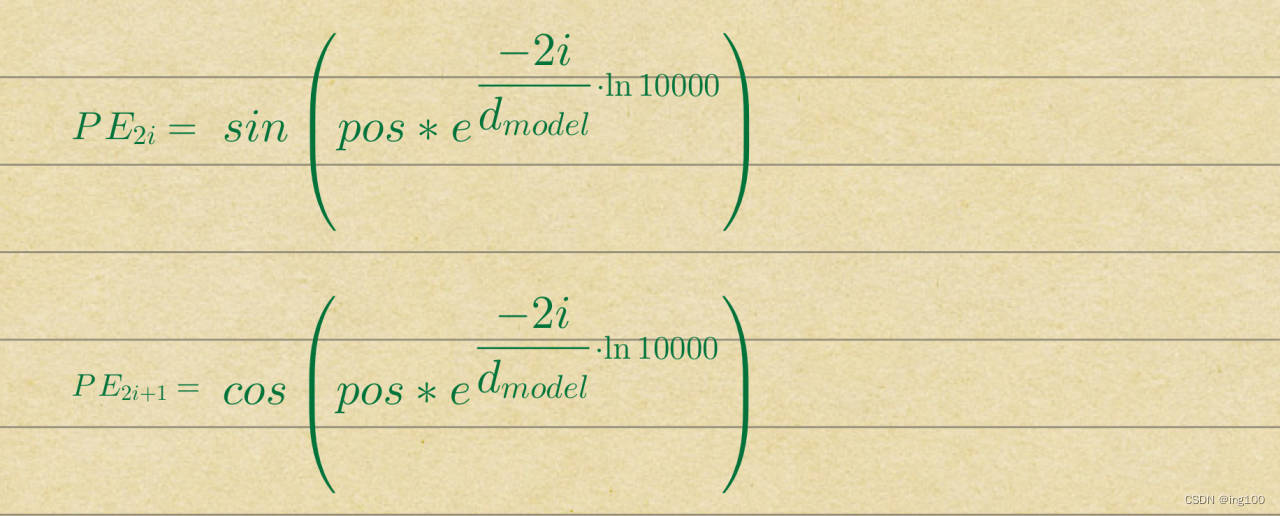
加入位置编码后数据shape不变为[3, 9, 512],部分代码如下所示
class PositionalEncoding(nn.Module):
def __init__(self, d_modle=512, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(0.1)
PE = torch.zeros(max_len, d_modle)
pos = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_modle, 2).float() / d_modle * (-math.log(10000.0))).unsqueeze(0)
PE[:, 0::2] = torch.sin(pos * div_term)
PE[:, 1::2] = torch.cos(pos * div_term)
PE = PE.unsqueeze(0)
self.register_buffer("PE", PE) # 相当于结构的常量,不参与梯度运算
def forward(self, x):
x = x + self.PE[:, :x.size(1), :]
return self.dropout(x)第二步
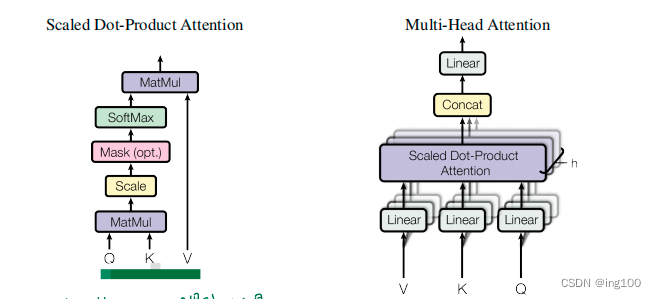
现在得到了第一步的输出,因为是自注意力机制,所以这里将输出的Tensor数据复制为三份作为第二步的输入,我们这三份一样的数据称为K,Q,V,输入到多头注意力机制中(上图右),注意力机制就是找出原始文本中对输入向量影响最大的部分,其中Q代表查询序列Query,即:我与你们的相似度是多少?,K代表键Key,即待查序列,与query要比较的值,V代表值Value,即待查序列的自身含义编码序列。
多头注意力机制的计算步骤如下:
1、KQV各自经过一个线性层后被切分为了许多份子Tensor
2、对每个子Tensor输入到Dot-Product Attention层(上图左)
3、将输出的多个子Tensor合并为一个Tensor后再经过一个线性映射得到输出
多头注意力机制代码如下:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, d_q=64, d_v=64, n_head=8):
super(MultiHeadAttention, self).__init__()
self.n_head, self.d_q, self.d_v = n_head, d_q, d_v
self.W_Q = nn.Linear(d_model, n_head*d_q)
self.W_k = nn.Linear(d_model, n_head*d_q)
self.W_V = nn.Linear(d_model, n_head*d_v)
self.DotProduct = ScaledDotProductAttention()
def forward(self, Q, K, V, mask):
"""
Q.shape -> [batch_size, len_sen, d_model]
Q,K 维度要保持一致
output.shape -> [batch_size, len_sen1, n_head, d_v]
"""
batch_size, len_sen = Q.shape[0], Q.shape[1]
Q = self.W_Q(Q).view(batch_size, -1, self.n_head, self.d_q) # 这里是先切分了8个子Tensor后输入到线性层
K = self.W_k(K).view(batch_size, -1, self.n_head, self.d_q)
V = self.W_V(V).view(batch_size, -1, self.n_head, self.d_v) # [batch_size, len_sen, n_head, d_v]
output = self.DotProduct(Q, K, V, mask) # shape -> [batch_size, len_sen1, n_head, d_v]
return output.reshape(batch_size, len_sen, -1) # reshape将多个子Tensor合并为了最后的输出接下来我们细说以下多头注意力机制中的Scaled Dot-Product Attention层,大致计算方法如下所示
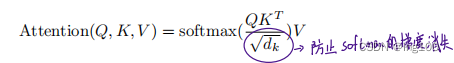
其中QK乘积是为了计算相似度,之后与V进行乘积则代表加权求和,若相似度较高则与V的权重和也较高。
上公式并没有提及MASK,这里讲解一下,在编码端中的Mask只包括Pad mask,上面提到过,在数据输入到网络之前为了保证其维度一致及可以组成一个矩阵,我们会在句子的末尾加上PAD,由于PAD本身并无意义,所以我们需要建立一个mask矩阵来消除PAD对注意力计算的影响,方法就是让PAD部分的QK乘积变为无穷小即相似度很低,在经过Softmax后其值就会变为0。那么所谓的MASK矩阵就是一个bool矩阵,其为True的部分会在后续计算时发挥作用,根据上图是在Q,K乘积之后做的MASK所以其矩阵的长宽应该与QK乘积以后的长宽一致。
部分代码如下所示:
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
self.softmax = torch.nn.Softmax(dim=-2)
def forward(self, Q, K, V, mask):
"""
Q.shape -> [batch_size, len_sen, n_head, d_q]
mask.shape -> [batch_size, len_sen, len_sen, n_head]
output.shape -> [batch_size, len_sen1, n_head, d_v]
"""
scale = torch.einsum('abcd,aecd->abec', Q, K) # shape -> [batch_size, len_sen1, len_sen2, n_head]
scale.masked_fill_(mask, 1e-9) # 进行mask
Q_K = self.softmax(scale)
output = torch.einsum('abcd,acde->abde', Q_K, V)
return output PAD MASK定义的代码如下:
# 定义 PAD mask
def makePadMask(input1, input2):
"""
input1.shape -> [batch_size, len_sen1]
input2.shape -> [batch_size, len_sen2]
padmask.shape -> [batch_size, len_sen1, len_sen2]
默认0代表PAD
"""
len_sen1 = input1.shape[1]
padmask = input2.eq(0).unsqueeze(1) # input2确定mask位置
padmask = padmask.repeat(1, len_sen1, 1) # input1确定维度大小,以对其输入
return padmask第三步
将多头注意力机制的输出,输入到前馈神经网络后再进行归一化和残差连接。最终的输出将复制两份作为新的K,V,传入到解码端中层。下面是编码层部分代码。
class Encoder(nn.Module):
def __init__(self, device, len_vocabulary, d_model=512, dff=2048, n_head=8, n_layer=6):
super(Encoder, self).__init__()
self.MultiHeadAttention = MultiHeadAttention() # 多头注意力
self.posembedding = PositionalEncoding() # 位置编码
self.input_Embedding = torch.nn.Embedding(len_vocabulary, d_model) # 词嵌入
self.d_model = d_model
self.n_head = n_head
self.n_layer = n_layer
self.device = device
self.FeedForward = torch.nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(True),
nn.Linear(dff, d_model)
)
def forward(self, encoder_input):
"""
x.shape -> [batch_size * len_sen * d_model]
output2.shape -> [batch_size, len_sen, d_model]
"""
encoder_mask = makePadMask(encoder_input, encoder_input).unsqueeze(-1).repeat(1,1,1,self.n_head)
x = self.input_Embedding(encoder_input)
x = self.posembedding(x)
# 因为是自注意力机制,所以输入MultiHead的QKV都是x,需要循环6次
for i in range(self.n_layer):
output1 = self.MultiHeadAttention(x, x, x, encoder_mask) # shape -> [batch_size, len_sen, n_head, d_v]
output1 += x
output1 = nn.LayerNorm(self.d_model).to(self.device)(output1)
# FeedForward Layer 后归一化
output2 = self.FeedForward(output1)
output2 = nn.LayerNorm(self.d_model).to(self.device)(output1+output2) # 进行归一化和残差连接
x = output2
return x解码端
解码端的搭建其实和编码段极其类似,步骤如下。
1、进行word Embedding 后加入位置编码
2、进行mask(含有PADmask以及序列Mask)的多头自注意力机制后再进行归一化和残差连接
3、第二步的输出作为Q矩阵,编码段的输出复制两份作为K和V矩阵,输入到多头自注意力机制中(含有PAD Mask不含序列Mask),再进行归一化和残差连接
4、输入前馈神经网络后再归一化和残差连接
5、二,三,四步重复N次,在论文中为6次
先介绍一下第二步的Mask,在Transformer中,我们会根据原文一个字一个字得生成译文。但是这样的话训练的效率就会大打折扣,所以我们只在预测时这么做,而在训练时我们则会加入一个序列Mask来解决此问题,与Pad Mask不让网络看到PAD部分的作用类似,其目的就是不让解码端看到当前位置之后的译文,这样我们就可以把整个译文输入的网络中,大大提高了并行性,训练速度得到了很大的提升。
那么序列Mask长什么样子呢?可以参考上图,其和PAD Mask一样也是一个bool矩阵,但是它是一个上三角为True其余部分为False的方阵。从结构图可知,解码端的多头注意力机制与编码端的不同,它是带mask的,这个mask就是序列mask,但是在多头注意力机制的Scaled Dot-Product Attention层中本身就有一个PAD Mask,所以要同时进行PAD Mask和序列Mask,我们在进行Mask的时候会直接将两个Mask矩阵进行相加(两个矩阵维度一致)然后再统一在Scaled Dot-Product Attention层中进行Mask。
那么第三步的PAD Mask又代表什么含义呢,上面提到过,第三步的输入包含了解码端的输出,而解码端的输入是存在PAD的,而我们不希望解码端输入部分的PAD起作用,所以需要Mask掉。
解码端部分代码如下所示:
class Decoder(nn.Module):
def __init__(self, device, len_vocabulary, d_model=512, dff=2048, n_head=8, n_layer=6):
super(Decoder, self).__init__()
self.n_head = n_head
self.device = device
self.n_layer = n_layer
self.MultiHeadAttention = MultiHeadAttention() # 多头注意力机制
self.posembedding = PositionalEncoding() # 位置编码
self.input_Embedding = torch.nn.Embedding(len_vocabulary, d_model) # 词嵌入
self.d_model, self.dff = d_model, dff
self.FeedForward = torch.nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(True),
nn.Linear(dff, d_model)
)
def forward(self, decoder_input, encoder_input, encoder_out1, encoder_out2):
"""
decoder_input.shape -> [batch_size, len_seq1]
encoder_input.shape -> [batch_size, len_seq2]
encoder_out1.shape = encoder_out2.shape -> [batch_size, len_seq2, d_model]
"""
# 第一层 (包括Seq mask and PAD mask)
pad_mask = makePadMask(decoder_input, decoder_input)
seq_mask = makeSeqMask(decoder_input).to(self.device)
x = self.input_Embedding(decoder_input)
x = self.posembedding(x)
Layer1_mask = (seq_mask+pad_mask).unsqueeze(-1).repeat(1, 1, 1, self.n_head)
for i in range(self.n_layer): # 重复6次
output1 = self.MultiHeadAttention(x, x, x, Layer1_mask)
output1 = nn.LayerNorm(self.d_model).to(self.device)(output1+x)
# 第二层 (没有Seq mask,只有PAD mask)
Layer2_padmask = makePadMask(decoder_input, encoder_input).unsqueeze(-1).repeat(1, 1, 1, self.n_head)
output2 = self.MultiHeadAttention(output1, encoder_out1, encoder_out2, Layer2_padmask)
output2 = nn.LayerNorm(self.d_model).to(self.device)(output2+output1)
# 第三层
output3 = self.FeedForward(output2)
output3 = nn.LayerNorm(self.d_model).to(self.device)(output3+output2)
x = output3
return x
训练
我们将网络结构定义完成之后就正式开始训练,数据集就使用上文的那三句话,训练的步骤也非常简单,
1、定义数据集
2、定义损失函数以及优化器
3、遍历数据集开始训练
上文说过在定义数据集的时候一定需要做预处理,就是将每一个Batch_Size的数据定义成一个矩阵再输入到网络中,以下为数据的定义代码。
# 定义训练集
encoder_input, decoder_input, target = make_data(sentences, CN_glossary, EN_glossary)
# 我们使用DataLoader中的collate_fn对其进行处理将其变为一个矩阵
trainloader = DataLoader(trainset, batch_size=3, shuffle=False, collate_fn=make_Pad)
### 下面是函数的实现方式
# 构造数据
def make_data(sentences, CN_glossary, EN_glossary):
"""
将单词序列转变为数字序列
sentenses:待转变的数据集
"""
encoder_input, decoder_input, target = [], [], []
max_len = 0
for i in range(len(sentences)):
temp = sentences[i][0].split()
encoder_input.append([CN_glossary[j] for j in temp])
decoder_input.append([EN_glossary[j] for j in sentences[i][1].split()])
target.append([EN_glossary[j] for j in sentences[i][2].split()])
return encoder_input, decoder_input, target
# 对同一batch的数据(中英数据)进行PAD填充
def make_Pad(batch):
"""
根据dataset取出前batch_size个数据,然后弄成一个列表(Tensor矩阵)
中英文数据都要进行PAD(填充0)
"""
batch_size = len(batch)
maxLen = 3 * [0]
batch = list(zip(*batch))
# batch[0]为同一batch下所有的encoder_input
# batch[1]为-------------的decoder_input
# batch[2]为-------------的target
# 现将其PAD,并转成Tensor矩阵
# 确定同一batch_size下encoder_input,decoder_input,target的最大长度
for i in range(3):
for j in range(batch_size):
maxLen[i] = max(maxLen[i], len(batch[i][j]))
# 根据最大长度往后补0
for i in range(3):
for j in range(batch_size):
for k in range(len(batch[i][j]), maxLen[i]):
batch[i][j].append(0)
return torch.LongTensor(batch[0]), torch.LongTensor(batch[1]), torch.LongTensor(batch[2])
训练部分的代码如下:
def train(args, dataloader, len_CNvocabulary, len_ENvocabulary):
# 定义网络,损失函数以及优化器
net = Transformer(args.device, len_CNvocabulary, len_ENvocabulary, args.d_model, args.dff, args.n_head, args.n_layer)
net = net.to(args.device)
criterion = torch.nn.CrossEntropyLoss(ignore_index=0) # 去除PAD的影响
criterion = criterion.to(args.device)
optimizer = torch.optim.AdamW(net.parameters(), lr=1e-5)
# 开始训练
net.train()
for epoch in range(args.epochs):
for encoder_input, decoder_input, target in dataloader:
encoder_input,decoder_input,target = encoder_input.to(args.device),decoder_input.to(args.device),target.to(args.device)
output = net(encoder_input, decoder_input)
loss = criterion(output, target.view(-1))
print("epoch:{}, loss:{}".format(epoch,loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.save(net.state_dict(), 'transformer1.pth')
预测
上文提到过,在训练的时候我们会加入序列Mask用来提高训练速度,但是在预测时我们则会根据原文来一个字一个字地生成译文。实现方式如下:
def pred(args, encoder_input, start_symbol, end_symbol):
"""
start_symbol 代表 S
end_symbol 代表 E
"""
# 定义网络 并导入模型参数
net = Transformer(args.device, len_CNvocabulary, len_ENvocabulary, args.d_model, args.dff, args.n_head, args.n_layer)
net = net.to(args.device)
net.load_state_dict(torch.load("transformer1.pth"))
# 要从S开始一个字一个字地预测直到E结束
decoder_input = torch.ones(1, 1).int().to(args.device) * start_symbol # 最开始decoder_input就是 “S”
while True: # 无限循环,直到网络输出END字符为止
encoder_output = net.encoder(encoder_input)
decoder_output = net.decoder(decoder_input, encoder_input, encoder_output, encoder_output)
output = net.Projection(decoder_output).view(-1, len_ENvocabulary)
_, index = output.max(1) # 概率最大的为下一个字
next_symbol = torch.ones(1, 1).int().to(args.device) * index[-1]
if next_symbol == end_symbol:
break
else:
# 要将预测的字放入,再输入到网络
decoder_input = torch.cat([decoder_input, next_symbol], dim=1)
return decoder_input结果展示
因为我们提供的数据比较小,我们就以训练集的其中一句话来进行预测,可以看到翻译正确。
![]()



















 7万+
7万+




 到【灌水乐园】发言
到【灌水乐园】发言









