






一、算法思想
威斯康辛乳腺癌数据集:威斯康星州乳腺癌数据集包含699个细针抽吸活检的样本单元,其中 458个为良性样本单元,241个为恶性样本单元。对于每一个样本来说,另外九个变量是与判别恶性肿瘤相关的细胞特征。这些细胞特征得分为1(最接近良性)至10(最接近病变)之间的整数。
这十个变量分别是:肿块厚度(Clump Thickness)、细胞大小的均匀性(Uniformity of Cell Size)、细胞形状的均匀性(Uniformity of Cell Shape)、边际附着力(Marginal Adhesion)、单个上皮细胞的大小(Single Epithelial Cell Size)、裸核(Bare Nuclei)、乏味染色体(Bland Chromatin)、正常核(Normal Nucleoli)、有丝分裂(Mitoses)、Class代表类别(类型变量:2 for benign, 4 for malignant)。
任一变量都不能单独作为判别良性或恶性的标准,建模的目的是找到九个细胞特征的某种组合,从而实现对恶性肿瘤的准确预测。
随机森林算法:从原始数据集中随机有放回采样取出m个样本生成m个训练集;对m个训练集,分别训练m个决策树模型;对于单个决策树模型,假设训练样本特征的个数为n,每次分裂时根据信息增益/信息增益比/基尼系数,选择最好的特征进行分裂;将生成的多棵决策树组成随机森林,对于分类问题,按照多棵树分类器投票决定最终分类的结果;对于回归问题,由多棵树预测值的均值决定最终预测结果。
二、流程图
三、实验结果
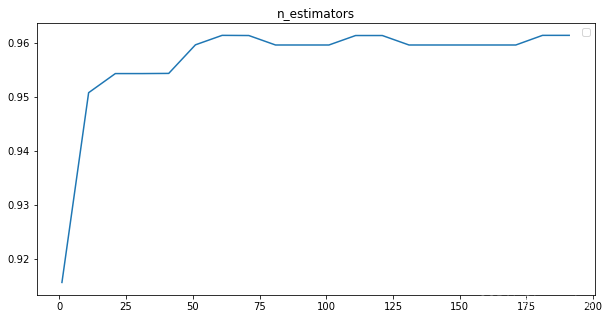
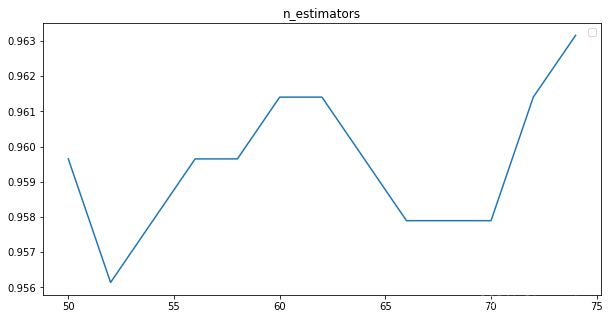
结果预测数值:
1、
 2、
2、
 3、
3、

四、源代码
from sklearn.datasets import load_breast_cancer #乳腺癌数据
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV,cross_val_score # 网格搜索和交叉验证指标
# # 加载乳腺癌数据
dataset = load_breast_cancer()
data = dataset.data
target = dataset.target
# print(data)
# print(target)
# 测试实例化
rfc=RandomForestClassifier(n_estimators=100,random_state=100)
score_pre=cross_val_score(rfc,data,target,cv=10).mean()
# print(score_pre)
#%%
import matplotlib.pyplot as plt
# 测试学习曲线,观看范围
scores = []
for i in range(1,201,10):
rfc = RandomForestClassifier(n_estimators=i,random_state=100,n_jobs=-1)
score = cross_val_score(rfc,data,target,cv=10).mean()
scores.append(score)
max_scores = max(scores)
in_scores = (scores.index(max(scores))*10)+1
# print(max_scores)
# print(in_scores)
plt.figure(figsize=[10,5])
plt.plot(range(1, 201, 10), scores)
plt.title("n_estimators")
plt.legend()
plt.show()
# 经过学习曲线能够观察到细节,接下来调整参数,缩小范围定位搜索
scores = []
for i in range(50,75,2):
rfc = RandomForestClassifier(n_estimators=i,random_state=100,n_jobs=-1)
score = cross_val_score(rfc,data,target,cv=10).mean()
scores.append(score)
max_scores = max(scores)
in_scores = ([*range(50, 75, 2)][scores.index(max(scores))])
# print(max_scores)
# print(in_scores)
plt.figure(figsize=[10,5])
plt.plot(range(50,75,2), scores)
plt.title("n_estimators")
plt.legend()
plt.show()
import numpy as np
# 网格搜索
# 有一些参数,范围比较广,适合先用学习曲线。有一些参数,可以知道范围的,范围也小,数量少,直接使用网格搜索.
rfc = RandomForestClassifier(n_estimators=70, random_state=90, n_jobs=-1)
param_grid = [
{
'max_features': np.arange(10,30,1),
},
]
gs = GridSearchCV(rfc, param_grid, cv=10)
gs = gs.fit(data,target)
print(gs.best_params_) # 最佳参数
print(gs.best_score_) # 最佳参数对应的准确率
rfc = RandomForestClassifier(n_estimators=70, random_state=90, n_jobs=-1)
param_grid = [
{
'max_depth':np.arange(1, 10, 1),
},
]
gs = GridSearchCV(rfc, param_grid, cv=10)
gs = gs.fit(data,target)
print(gs.best_params_) # 最佳参数
print(gs.best_score_) # 最佳参数对应的准确率
rfc = RandomForestClassifier(n_estimators=70, random_state=90, n_jobs=-1)
param_grid = [
{
'min_samples_leaf': np.arange(1, 1+10, 1),
},
]
gs = GridSearchCV(rfc, param_grid, cv=10)
gs = gs.fit(data,target)
print(gs.best_params_) # 最佳参数
print(gs.best_score_) # 最佳参数对应的准确率















 2574
2574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









