









第33次认证第二题——相似度计算
时间限制: 1.0 秒
空间限制: 512 MiB
题目背景
两个集合的 Jaccard 相似度定义为:𝑆𝑖𝑚(𝐴,𝐵)=∣𝐴∩𝐵∣∣𝐴∪𝐵∣Sim(A,B)=∣A∪B∣∣A∩B∣即交集的大小除以并集的大小。当集合 𝐴A 和 𝐵B 完全相同时,𝑆𝑖𝑚(𝐴,𝐵)=1Sim(A,B)=1 取得最大值;当二者交集为空时,𝑆𝑖𝑚(𝐴,𝐵)=0Sim(A,B)=0 取得最小值。
题目描述
除了进行简单的词频统计,小 P 还希望使用 Jaccard 相似度来评估两篇文章的相似性。 具体来说,每篇文章均由若干个英文单词组成,且英文单词仅包含“大小写英文字母”。 对于给定的两篇文章,小 P 首先需要提取出两者的单词集合 𝐴A 和 𝐵B,即去掉各自重复的单词。 然后计算出:
- ∣𝐴∩𝐵∣∣A∩B∣,即有多少个不同的单词同时出现在两篇文章中;
- ∣𝐴∪𝐵∣∣A∪B∣,即两篇文章一共包含了多少个不同的单词。
最后再将两者相除即可算出相似度。 需要注意,在整个计算过程中应当忽略英文字母大小写的区别,比如 the、The 和 THE 三者都应被视作同一个单词。
试编写程序帮助小 P 完成前两步,计算出 ∣𝐴∩𝐵∣∣A∩B∣ 和 ∣𝐴∪𝐵∣∣A∪B∣;小 P 将亲自完成最后一步的除法运算。
输入格式
从标准输入读入数据。
输入共三行。
输入的第一行包含两个正整数 𝑛n 和 𝑚m,分别表示两篇文章的单词个数。
第二行包含空格分隔的 𝑛n 个单词,表示第一篇文章;
第三行包含空格分隔的 𝑚m 个单词,表示第二篇文章。
输出格式
输出到标准输出。
输出共两行。
第一行输出一个整数 ∣𝐴∩𝐵∣∣A∩B∣,即有多少个不同的单词同时出现在两篇文章中;
第二行输出一个整数 ∣𝐴∪𝐵∣∣A∪B∣,即两篇文章一共包含了多少个不同的单词。
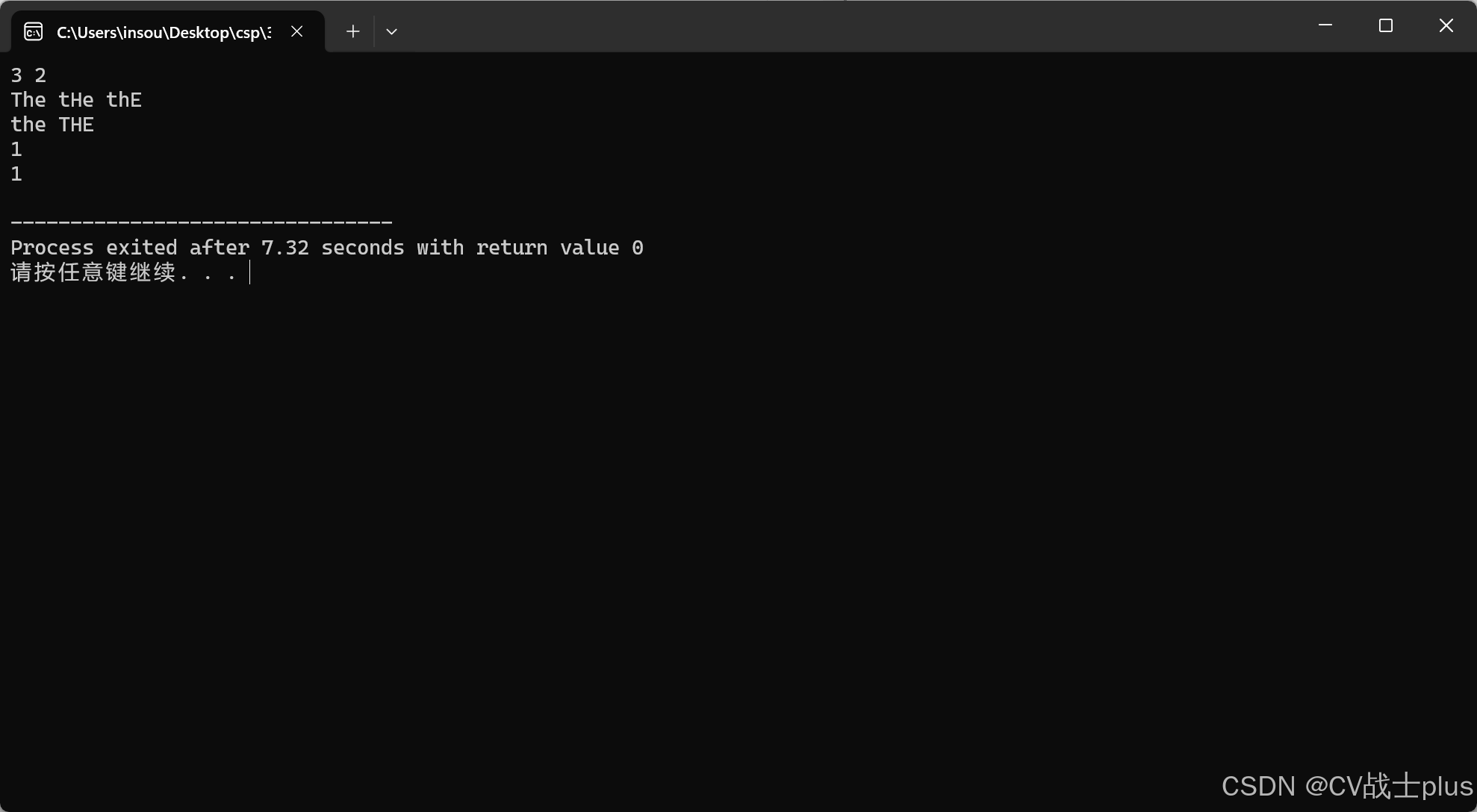
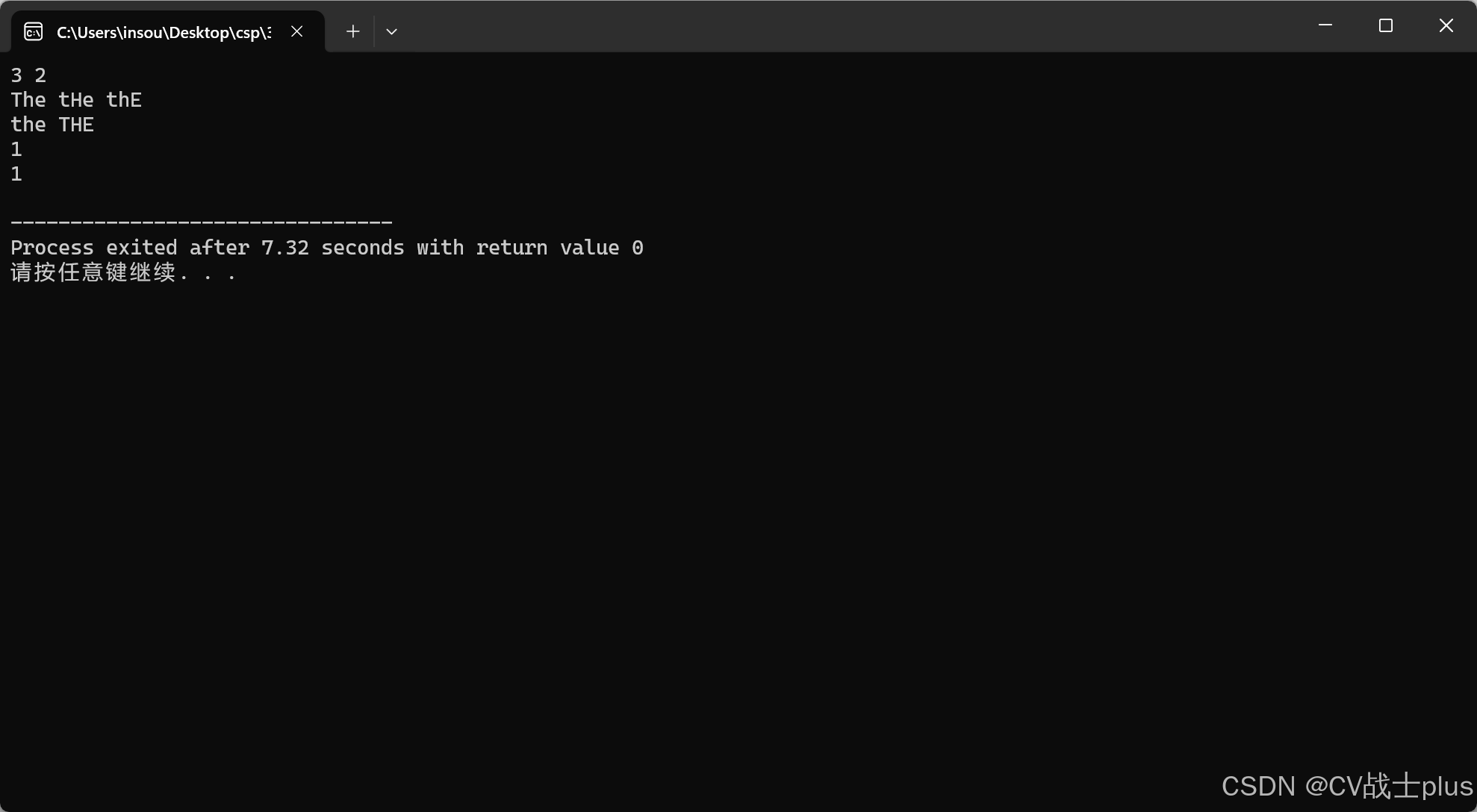
样例1输入
3 2
The tHe thE
the THE
样例1输出
1
1
样例1解释
𝐴=𝐵=𝐴∩𝐵=𝐴∪𝐵=A=B=A∩B=A∪B= {the}
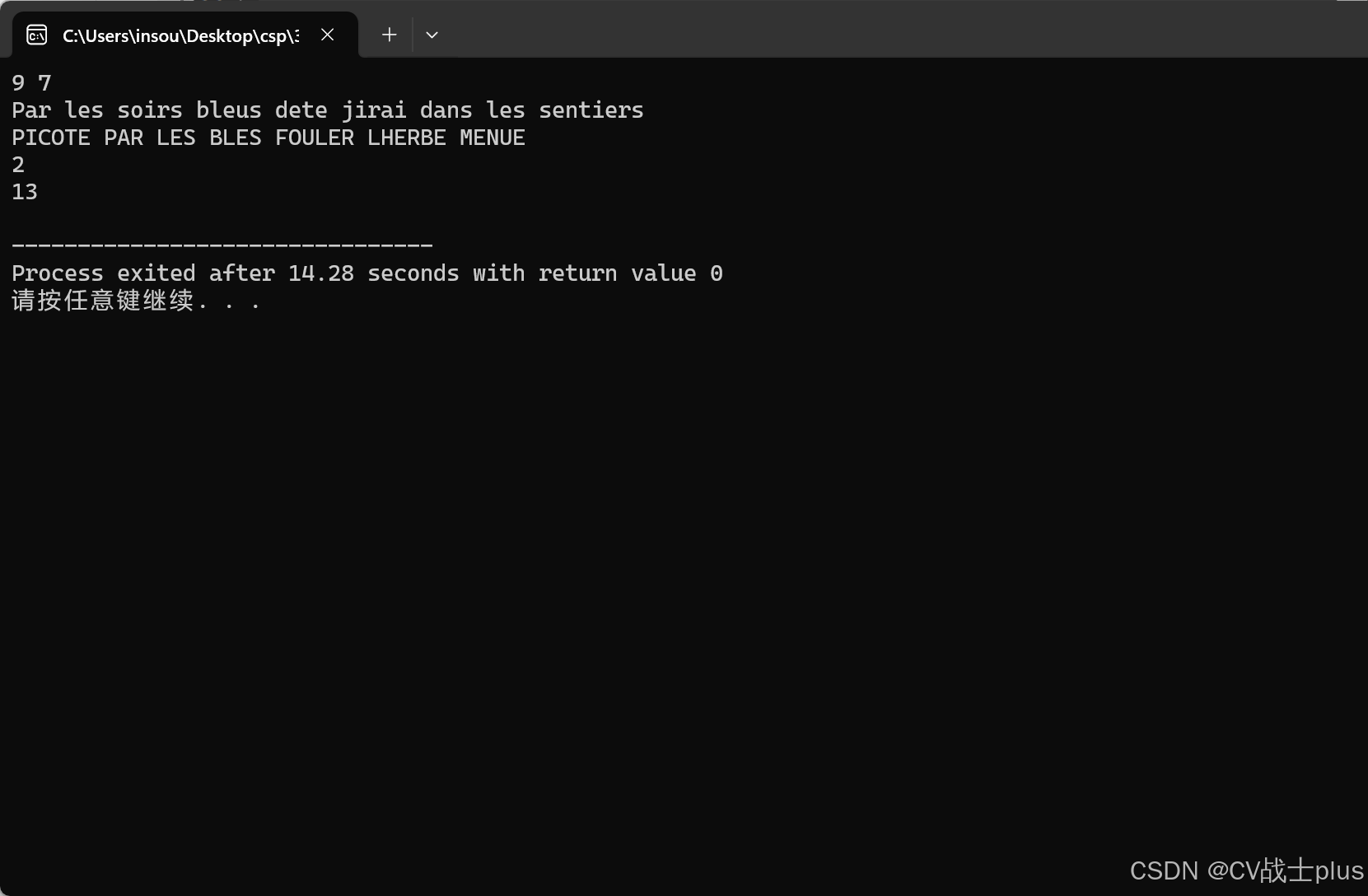
样例2输入
9 7
Par les soirs bleus dete jirai dans les sentiers
PICOTE PAR LES BLES FOULER LHERBE MENUE
样例2输出
2
13
样例2解释
𝐴=A= {bleus, dans, dete, jirai, les, par, sentiers, soirs} ∣𝐴∣=8∣A∣=8
𝐵=B= {bles, fouler, les, lherbe, menue, par, picote} ∣𝐵∣=7∣B∣=7
𝐴∩𝐵=A∩B= {les, par} ∣𝐴∩𝐵∣=2∣A∩B∣=2
样例3输入
15 15
Thou that art now the worlds fresh ornament And only herald to the gaudy spring
Shall I compare thee to a summers day Thou art more lovely and more temperate
样例3输出
4
24
子任务
80%80% 的测试数据满足:𝑛,𝑚≤100n,m≤100 且所有字母均为小写;
全部的测试数据满足:𝑛,𝑚≤104n,m≤104 且每个单词最多包含 1010 个字母。
参考题解
#include<iostream>
#include<unordered_set>
#include<algorithm>
#include<cstring>
using namespace std;
string toLowerCase(string s) {
string result = "";
for(char c: s) {
result.push_back(tolower(c));
}
return result;
}
int main() {
int len1, len2;
cin >> len1 >> len2;
unordered_set<string> a, b;
string word;
//处理第一篇文章
for(int i = 0; i < len1; i++) {
cin >> word;
word = toLowerCase(word);
// transform(word.begin(), word.end(), word.begin(), ::tolower); 也可以使用标准算法transform,更高效
a.insert(word);
}
//处理第2篇文章
for(int i = 0; i < len2; i++) {
cin >> word;
word = toLowerCase(word);
// transform(word.begin(), word.end(), word.begin(), ::tolower); 也可以使用标准算法transform,更高效
b.insert(word);
}
//计算交集大小
int intersection = 0;
for (const auto& s : a) {
if (b.count(s)) { //count函数:查找容器中值为s的元素个数(由于无序集合没有重复元素故其返回值为1或0
++intersection; //交集+1
}
}
//计算并集大小
int union_size = a.size() + b.size() - intersection;
//输出结果
cout << intersection << endl;
cout << union_size <<endl;
return 0;
}


知识点总结
- C++去重可以考虑std::unordered_set——会自动去除重复元素
- C++ 标准库提供了
std::transform函数,它可以用来简化遍历和转换的过程,并且通常能提供较好的性能。 transform(word.begin(), word.end(), word.begin(), ::tolower); 头文件<algorithm> - 字符处理函数tolower(char),头文件<cctype>
- unordered_set相关方法:
- 插入:
insert() - 删除:
erase() - 查找:
find(),count() - 访问:通过迭代器访问元素
- 获取集合大小:
size(),empty() - 清空集合:
clear()
- 插入:

















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









