







链接:https://www.sciencedirect.com/science/article/abs/pii/S1574013724000194?via%3Dihub
摘要
本文对复杂智能系统的行为建模进行了广泛而深入的综述,特别聚焦于生成对抗网络(GANs)的创新性应用。该综述不仅深入探讨了 GANs 的基本原理,还阐明了其在精确建模复杂智能系统行为方面的关键作用。通过将行为建模分为预测和学习两类,本文细致研究了每个领域的当前研究状况,揭示了由 GANs 驱动的最新进展和方法。此外,本文还深入探讨了 GANs 在复杂智能系统行为建模中的理论基础和实际意义,并提出了潜在的未来研究方向,以推动该领域的发展。总体而言,这篇全面的综述为研究人员、从业者和学者提供了宝贵的资源,有助于他们加深对使用 GANs 进行行为建模的理解,并为这一充满活力的领域未来的探索和创新指明方向。
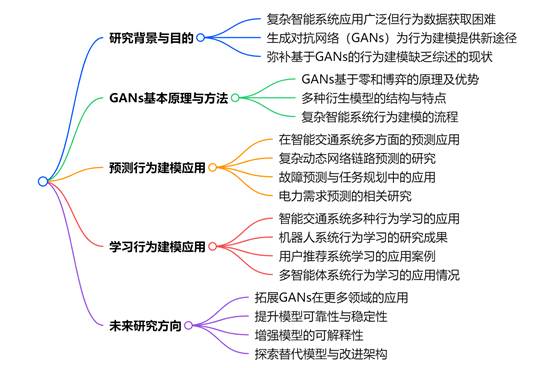
图表
展示了生成对抗网络(GANs)的基本模型:
组件
- 生成器(Generator, G):接收随机噪声(Random noise, z)作为输入。其作用是通过对随机噪声进行处理,生成伪造样本(Generated sample, G (z) )。
- 判别器(Discriminator, D):接收两部分输入,一部分是生成器生成的伪造样本(G (z)),另一部分是真实样本集(Real sample set)中的真实样本(Real sample) 。它的任务是判断输入样本是真实样本还是伪造样本。
损失函数
- 生成器损失函数(Generator loss function, L):用于衡量生成器生成的样本与真实样本之间的差异。通过不断调整生成器的参数,使生成器损失函数的值最小化,从而优化生成器,让它生成更接近真实样本的伪造样本。
- 判别器损失函数(Discriminator loss function, L):用于衡量判别器对真实样本和伪造样本的判别能力。通过调整判别器的参数,使判别器损失函数的值最小化,提升判别器区分真实样本和伪造样本的性能。
工作流程
- 随机噪声(z)输入到生成器(G),生成器输出伪造样本(G (z))。
- 伪造样本(G (z))和真实样本(Real sample)同时输入到判别器(D)。
- 判别器对输入样本进行判断,输出判断结果(Result)。在这个过程中,生成器和判别器进行对抗博弈:生成器努力生成更逼真的样本,使判别器难以区分;判别器则努力提高辨别真假样本的能力。通过不断迭代优化各自的损失函数,最终使生成器能够生成高质量的伪造样本,判别器具备良好的判别能力。
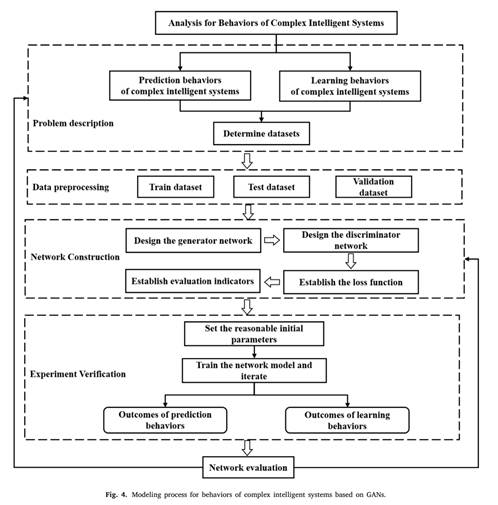 Table Intelligent transportation systems behaviors prediction
Table Intelligent transportation systems behaviors prediction
| 分类 | 参考文献 | 方法 | 优势 | 适用性 |
| 动态网络中的链路预测 | [81] | WL-GAN | 预测性能出色且模型稳定性良好 | 复杂网络 |
| [82] | Network-GAN | 出色的预测性能 | 动态网络中的时间链路 | |
| [83] | MGLGAN | 预测准确率高,对基准模型适应性强 | 动态时变网络 | |
| [84] | GAHNRL | 计算成本低,稳健性好 | 大规模动态网络 | |
| [85] | SigGAN | 解决正边和负边数量不平衡问题 | 带符号网络 | |
| 故障预测 | [86] | LSTM-GAN | 解决模型不平衡问题,提高故障预测准确率和计算效率 | 机器维护 |
| [87] | GAN | 有效提高预测准确率 | 机器寿命预测 | |
| [88] | GAN-SFP | 预测性能出色 | 软件故障预测 | |
| [89] | WGAN-GP | 解决数据不平衡问题 | 通信网络故障预测 | |
| [90] | Transformer-WGAN | 解决数据不足和可解释性问题 | 空气处理单元的故障检测与诊断 | |
| 任务规划 | [91] | GAN | 安全性和可靠性出色 | 智能移动应用 |
| [92] | CGANs | 抓取速度和精度提高 | 机器人任务规划 | |
| [93] | GAN | 规划的有效性和准确性提高 | 多智能体交互任务规划 | |
| [94] | GDTP-RRT | 跟踪误差降低 | 车辆轨迹规划 | |
| 电力系统预测 | [95] | E-GAN | 保证预测准确率,提高计算速度 | 大规模建筑电力需求预测 |
| [96] | Multiple GAN | 为后续研究提供充分理论基础 | 大规模建筑电力需求预测 | |
| [97] | CGAN | 提高模型预测的准确性和稳定性 | 风力发电预测 | |
| [98] | PG-GAN | 可生成不同数量的场景 |
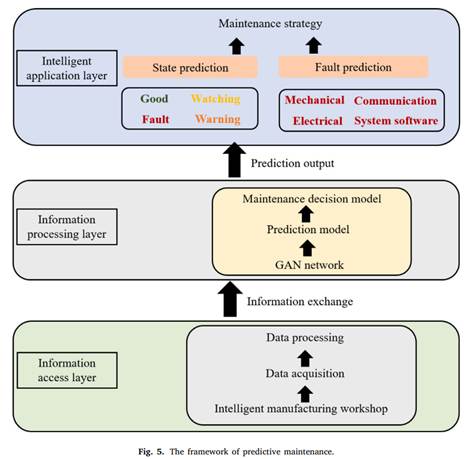
展示了预测性维护的框架,由三个层级构成:
信息接入层(Information access layer)
- 来源:智能制造车间(Intelligent manufacturing workshop) 。
- 功能:进行数据采集(Data acquisition),收集设备运行等相关数据,再经数据处理(Data processing)后,为上层提供基础数据支持,是整个框架的数据源头 。
信息处理层(Information processing layer)
- 模型:采用生成对抗网络(GAN network)构建预测模型(Prediction model) ,进而形成维护决策模型(Maintenance decision model)。
- 功能:对信息接入层传来的数据进行分析处理,通过 GAN 网络挖掘数据中的潜在规律和特征,预测设备状态和故障情况,为维护策略制定提供依据 ,并与其他层级进行信息交互(Information exchange) 。
智能应用层(Intelligent application layer)
- 预测类别:包括状态预测(State prediction ,如正常 Good、故障 Fault、预警 Warning )和故障预测(Fault prediction ,涉及机械 Mechanical、电气 Electrical、通信 Communication、系统软件 System software 等方面 ) 。
- 输出与应用:根据预测结果(Prediction output)制定维护策略(Maintenance strategy) ,将预测性维护的分析结果应用到实际设备维护管理中,实现智能化维护决策 。
Why:研究动机
在人工智能与机器学习广泛应用的当下,许多任务依赖大量高质量数据训练模型 。然而,实际场景中常面临数据获取困难、样本量小、数据不平衡等问题。比如在医疗影像诊断领域,罕见病病例数据稀缺;工业故障诊断中,故障样本难以收集。传统深度学习模型在小样本条件下易出现过拟合,泛化能力差,无法达到理想性能。虚拟样本生成技术能够通过算法模拟、生成新的样本数据,扩充训练数据集,缓解数据匮乏问题,为提升模型性能提供了新途径。但目前该领域存在技术分散、缺乏系统性评估、部分方法适用性有限等问题,因此,对虚拟样本生成技术进行全面深入研究,探究其核心机制,优化技术方法,对突破数据瓶颈、推动人工智能应用发展具有重要意义。
What:研究发现与结论
- 新认识:虚拟样本生成技术涵盖统计方法与深度学习方法两大类别,各有独特的适用场景与局限性。统计方法如 Bootstrap、SMOTE 等,原理简单、计算成本低,但在处理复杂数据分布时效果欠佳;深度学习方法,像生成对抗网络(GANs)、变分自编码器(VAEs),能更好地捕捉数据复杂特征,生成高质量样本,但存在训练不稳定、模式崩溃等问题。此外,不同技术在面对图像、文本、时间序列等不同类型数据时,表现差异显著。
- 新方法:提出一种结合统计特征增强与深度学习生成的混合虚拟样本生成方法。先利用统计方法对原始数据进行特征变换与增强,再通过改进的条件生成对抗网络,依据数据内在特征分布生成多样化虚拟样本。同时,设计了新的质量评估指标,从样本多样性、与真实数据分布的匹配度等多维度衡量生成样本质量。
- 新结论:混合虚拟样本生成方法在多个基准数据集及实际应用场景中,有效提升了模型的泛化能力与分类准确率。相较于单一的统计方法或深度学习方法,该方法生成的样本能让模型在小样本、不平衡数据条件下表现更优。但虚拟样本生成技术仍面临可解释性不足、生成样本可能引入偏差等挑战,未来需在跨领域应用、与其他前沿技术融合等方向进一步探索。
How:研究实施过程与方法技术
- 数据预处理:对原始数据进行清洗,去除噪声与无效数据;针对不同数据类型,采用标准化、归一化等操作进行特征处理,为后续样本生成奠定基础。
- 统计方法应用:运用 SMOTE 算法对少数类样本进行过采样,基于数据特征空间的距离度量,生成新的少数类样本,改善数据不平衡问题;利用 Bootstrap 重采样技术,从原始数据中有放回地抽取多个子样本集,扩充数据规模。
- 深度学习模型构建:构建基于注意力机制的条件生成对抗网络,在生成器与判别器中引入注意力模块,使模型更聚焦于关键数据特征。精心设计网络结构与参数,采用合适的激活函数、优化器,通过对抗训练过程,学习数据的概率分布,生成逼真的虚拟样本。
- 质量评估与优化:使用设计的质量评估指标,对生成的虚拟样本进行量化评估,分析样本质量问题。根据评估结果,调整模型参数、优化生成策略,迭代改进虚拟样本生成过程。
读文献实操
- 目的决定方法:若研究目的是了解虚拟样本生成技术的基础原理,可重点精读论文中关于统计方法、深度学习方法原理的章节,采用逐句分析、推导公式的精读方式;若目的是探索该技术在某一具体领域(如医疗)的应用,可快速浏览方法原理部分,重点阅读案例研究、实验结果章节,采用抓关键结论的泛读方式。
- 看文献,找方向:先阅读中文核心期刊文献,如《计算机学报》《自动化学报》中有关虚拟样本生成的文章,快速熟悉基础概念、常用技术和国内研究现状,掌握 “数据增强”“样本过采样” 等专业术语。再阅读英文顶刊论文,像发表在IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI)、Neural Information Processing Systems(NeurIPS)上的相关研究,追踪国际前沿动态,了解领域内最新的研究方向与热点问题。
- 初定方向,找创新点:以虚拟样本生成技术领域为例,通过阅读发现当前研究在跨模态数据(如图像与文本结合)的虚拟样本生成方面存在不足,且部分方法生成样本的多样性不够。可从这些方向入手,探索新的跨模态生成模型,或者改进现有算法,增强样本多样性。同时,关注领域热点,如结合当下热门的扩散模型、自监督学习技术,创新虚拟样本生成方法。
- 遇难题,找解决方法:若在阅读论文时,对生成对抗网络的训练过程理解困难,可查找 GANs 的原始论文《Generative Adversarial Nets》,深入研读其理论推导与实验设置;也可参考其他学者撰写的解读文章、博客,从不同角度理解。还能加入学术交流群,与同行讨论,分享见解,共同攻克难题 。
期刊信息
| 信息类别 | 详情 |
| 名称 | Computer Science Review |
| 影响因子 | 13.3 |
| 年文章数 | 48 |
| 中科院分区 | 计算机科学 1 区 |
| JCR 分区 | Q1 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









