







最早看到朴素贝叶斯,一直琢磨『朴素』是个啥意思,大学只学过贝叶斯公式,这两者之间到底有什么关系呢?然后在看一些跟踪算法的时候,发现好多论文用这个『朴素贝叶斯』来进行二分类,我的天,这么好用的东西,我竟然不知道,一边感慨自己的无知,一边也开始看一些实例来进行理解。下面就简单地结合『机器学习实战』这本书,来好好看看『朴素贝叶斯』。
Github: 朴素贝叶斯
简单的数学部分
——————————————————————————————————————————————————————
朴素贝叶斯的核心还是贝叶斯公式,只不过加上了一些假设,假设部分我们待会再说,先来看看贝叶斯公式。
以二分类问题为背景:
要判断物体属于哪一类,我们可以通过比较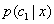
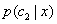
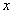
Ⅰ、根据贝叶斯公式:
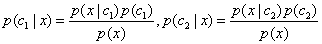
注:其实贝叶斯公式可以看做
Ⅱ、问题转换为比较:

Ⅲ、对于
利用训练样本,我们可以通过已知分类,或者手动分类来获得一个大的样本中,有多少属于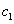
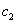
注:对于二分类问题
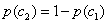
Ⅳ、对于
对于一件物品,我们可以通过特征来对它进行描述,比如:为什么我们知道一个物体是手机呢(这是一个正经的问题^^),我们通过它的特征来
判断(一般是矩形的、能打电话、能发短信等)人脑通过抽出物体的特征,来判断物体的类别。那么计算机也是一样的,只不过特征需要我们自己
选取。
那么对于物品

好了,朴素贝叶斯的真正朴素的地方来了,『朴素』的含义:假设每个特征都是相互独立的,就是说特征与特征之间没半毛钱关系。于是:

利用训练样本,我们只需要计算每个类别下每个特征的条件概率就可以了!(瞬间问题简单了一万倍^^)
一个简单的垃圾邮件过滤器
———————————————————————————————————————————————————————
Ⅰ、收集数据:这里数据直接提供,一般情况下需要自己手动采集及预分类
Ⅱ、数据整理:拿到手的数据并不能直接使用,我们需要对数据进行预处理,变成向量的形式(这里采用词袋模型)
Ⅲ、训练数据:利用已有数据建立朴素贝叶斯分类器
Ⅳ、测试分类:对分类器的可靠性进行测试,并获得分类的误差率
# 这里采用交叉验证,即从已有数据中,抽取一部分作为测试用,剩下部分用作训练用
import numpy as np
def textParse(bigString):
import re
wordsOfText = re.split('\W+', bigString)
return [w.lower() for w in wordsOfText if len(w) > 2]
def createVocabList(docList):
vocab = set()
for doc in docList:
vocab |= set(doc)
return list(vocab)
def words2vec(vocab, doc):
docVec = [0] * len(vocab)
for word in doc:
if word in vocab:
docVec[vocab.index(word)] += 1
return docVec
def trainNB(trainSet, trainClass):
docNum = len(trainClass)
wordNum = len(trainSet[0])
pSpam = sum(trainClass) / float(docNum)
wiOfC1 = np.ones(wordNum); wiOfC2 = np.ones(wordNum)
wnOfC1 = 2.0; wnOfC2 = 2.0
for i in xrange(docNum):
if trainClass[i] == 1:
wiOfC1 += trainSet[i]
wnOfC1 += sum(trainSet[i])
else:
wiOfC2 += trainSet[i]
wnOfC2 += sum(trainSet[i])
p1 = wiOfC1 / wnOfC1; p2 = wiOfC2 / wnOfC2
return p1, p2, pSpam
def classfyNB(inputVec, p1, p2, pSpam):
pC1 = sum(np.log(p1) * inputVec) + np.log(pSpam)
pC2 = sum(np.log(p2) * inputVec) + np.log(1 - pSpam)
return pC1 > pC2 and 1 or 0
def main():
import random
# file2vocab
docList = []; classList = []
for i in xrange(1, 26):
wordList = textParse(open('bayes/spam/%d.txt' % i, 'r').read())
docList.append(wordList)
classList.append(1)
wordList = textParse(open('bayes/ham/%d.txt' % i, 'r').read())
docList.append(wordList)
classList.append(0)
vocab = createVocabList(docList)
totalCount = 0
for k in xrange(100):
docMat = range(50); testMat = []; randList = []
for i in xrange(10):
randIndex = int(random.uniform(0, len(docMat)))
randList.append(randIndex)
testMat.append(words2vec(vocab, docList[randIndex]))
del(docMat[randIndex])
trainMat = []; trainClass = []
for i in docMat:
trainMat.append(words2vec(vocab, docList[i]))
trainClass.append(classList[i])
# go for classify
# cal the error rate
p1, p2, pSpam = trainNB(trainMat, trainClass)
errorCount = 0
for i, test in enumerate(testMat):
out = classfyNB(test, p1, p2, pSpam)
if out != classList[randList[i]]:
errorCount += 1
totalCount += errorCount
print "average err: %.2f" % (float(totalCount) / (100 * 10))
if __name__ == '__main__':
main()















 7099
7099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









