










本文由Markdown语法编辑器编辑完成。
1. 背景:
近期在调研一个问题,就是with…open这个函数,在大量的请求几乎同时到达时,对于几百兆的体数据文件(如nii.gz, mha)等的内存加载方式是怎么样的。
之前模糊地的认为,既然已经用with open将文件打开了,那是不是python就会将这个文件的整体内容,都加载到内存中呢。要不然,怎么实现,读取文件中的内容呢。
但是现实中通过监测容器的性能,又觉得不是这样子的。因为,如果前端突然过来几百个请求,而每个请求,其实只需要读取这个大文件中的一小部分。那么如果每个请求过来,都将这个大文件(比如几百兆)加载到内存中的话,那内存岂不是瞬间就被撑爆了。
而实际上,我的服务,并没有因为这几百,甚至上千的请求,而内存暴涨。
所以,一定是有什么机制,来处理这样的情况。
首先,咨询了一下gpt, 看它对于这种情况,是怎么理解的。
KIMI给出的解答:

GPT-4o给出的解答:
根据以上两款gpt给出的回答,可以确定with…open, 仅仅是获得了相应文件的文件指针,并没有真正的,立刻将文件全部加载到内存中。只有调用f.read(), 里面给予了要读取的文件内容的大小,才会将这部分内容,加载到内存中。
为了更加形象地展示这个过程,我借助于python中常用的监测内存变化的工具——memory_profile来做测试。
关于memory_profile的用法,可以参考它的介绍:
memory_profiler 介绍
2. 基于memory_profile, 展示with…open的内存使用过程
以下演示代码,主要完成,通过with…open, 读取一个几百兆的.mha文件, 并且通过f.read()读取不同大小的内容,查看这个过程中的内存变化过程。
2.1 创建py文件,利用文件指针读取文件
如图,创建一个test_mem.py的文件。
里面定义一个my_func()的函数,主要用来通过with open打开一个本地的.mha文件,并尝试通过文件指针的方式,读取该.mha文件中的一部分数据.
import os
import numpy as np
mha_path = "/path/to/xxx.mha"
@profile
def my_func():
with open(mha_path, "rb") as f:
last = f.seek(0, os.SEEK_END)
print(f"last is: {last}")
sdb = 512 * 512 * 2
f.seek(0)
slice_array = np.frombuffer(f.read(sdb), dtype=np.uint16)
if __name__ == '__main__':
my_func()
2.2 利用pip安装memory_profiler, 监控内存使用
由于函数my_func()加上了@profile的装饰器。因此,可以通过运行py文件的方式,查看该函数每一行的内存占用,截图如下:
python -m memory_profiler test_mem.py
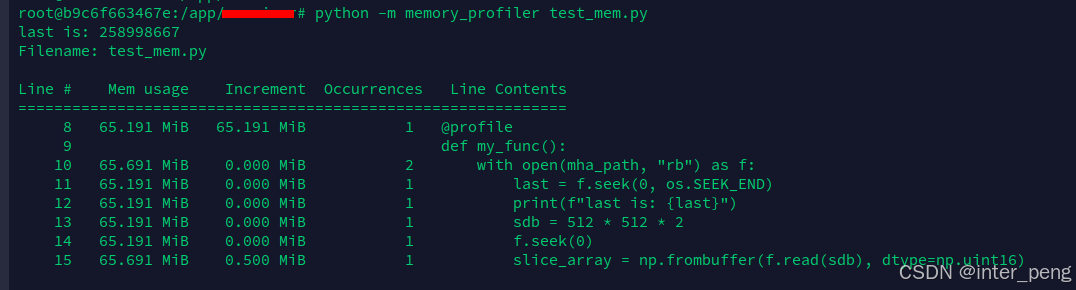
首先可以看到,通过f.seek(0, os.SEEK_END), 可以将文件指针直接移动到该文件的末尾,返回的大小: 258998667, 也就是这个文件在内存中占据的大小。
258998667B == 247.00MB, 基本和在linux上,看到当前的.mha文件248MB, 大小近似。
而该函数中,真正引起内存变化的,是最后一句:
# 从文件头开始,读取长度为: 512*512*2B大小的内存,转化为np.uint16的numpy_array, 返回。
slice_array = np.frombuffer(f.read(sdb), dtype=np.uint16)
而从memory_profiler给出的逐行内存视图中,也可以看到,在执行最后一行后,这个程序占据的内存,增加了0.500MB, 也就是 5125122 == 524288 B = 0.5 MB.
也就是前面的那些代码,都没有多余的内存分配。只有最后一行,真正的使用文件指针 f.read()的时候,才需要额外分配相应的内存。
我们将最后一行, f.read()里面的大小,乘以10倍后,再查看一下内存的分配。
slice_array = np.frombuffer(f.read(sdb * 10), dtype=np.uint16)
再次运行指令:
python -m memory_profiler test_mem.py
可以看到内存的监测变化:

通过以上的简单测试,我们了解了在使用with…open打开一个大文件时,并不会造成内存的额外分配。只有真正地调用f.read()函数时,才会根据用户需要读取的内存块的大小,来分配相应的内存, 而不会造成资源的额外浪费。
完。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











