










有人相爱,有人夜里看海,有人还在coding
1.WEB网页版本
1. 环境准备
ubuntu 22.04 python 3.12 cuda 12.1 pytorch 2.3.0
pip依赖包
升级 pip
python -m pip install --upgrade pip
更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install transformers==4.48.2 pip install accelerate==1.3.0 pip install modelscope==1.22.3 pip install streamlit==1.41.1
2.模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
新建 model_download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。并运行 python model_download.py 执行下载。
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir='/root/autodl-tmp', revision='master')3.代码准备
新建 chatBot.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。下面的代码有很详细的注释,大家如有不理解的地方,欢迎留言
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
import re
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown("## DeepSeek-R1-Distill-Qwen-7B LLM")
"[开源大模型食用指南 self-llm](https://github.com/datawhalechina/self-llm.git)"
# 创建一个滑块,用于选择最大长度,范围在 0 到 8192 之间,默认值为 8192(DeepSeek-R1-Distill-Qwen-7B 支持 128K 上下文,并能生成最多 8K tokens,我们推荐设为 8192,因为思考需要输出更多的Token数)
max_length = st.slider("max_length", 0, 8192, 8192, step=1)
# 创建一个标题和一个副标题
st.title("💬 DeepSeek R1 Distill Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")
# 定义模型路径
mode_name_or_path = '/root/autodl-tmp/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B'
# 文本分割函数
def split_text(text):
pattern = re.compile(r'<think>(.*?)</think>(.*)', re.DOTALL) # 定义正则表达式模式
match = pattern.search(text) # 匹配 <think>思考过程</think>回答
if match: # 如果匹配到思考过程
think_content = match.group(1).strip() # 获取思考过程
answer_content = match.group(2).strip() # 获取回答
else:
think_content = "" # 如果没有匹配到思考过程,则设置为空字符串
answer_content = text.strip() # 直接返回回答
return think_content, answer_content
# 定义一个函数,用于获取模型和 tokenizer
@st.cache_resource
def get_model():
# 从预训练的模型中获取 tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 从预训练的模型中获取模型,并设置模型参数
model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16, device_map="auto")
return tokenizer, model
# 加载 Qwen2.5 的 model 和 tokenizer
tokenizer, model = get_model()
# 如果 session_state 中没有 "messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "有什么可以帮您的?"}]
# 遍历 session_state 中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 将用户输入添加到 session_state 中的 messages 列表中
st.session_state.messages.append({"role": "user", "content": prompt})
# 将对话输入模型,获得返回
input_ids = tokenizer.apply_chat_template(st.session_state.messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=max_length)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
think_content, answer_content = split_text(response) # 调用split_text函数,分割思考过程和回答
# 将模型的输出添加到 session_state 中的 messages 列表中
st.session_state.messages.append({"role": "assistant", "content": response})
# 在聊天界面上显示模型的输出
with st.expander("模型思考过程"):
st.write(think_content) # 展示模型思考过程
st.chat_message("assistant").write(answer_content) # 输出模型回答
# print(st.session_state) # 打印 session_state 调试 3.运行DEMO
在终端中运行以下命令,启动 streamlit 服务,server.port 可以更换端口
streamlit run chatBot.py --server.address 127.0.0.1 --server.port 6006在本地浏览器中打开链接 http://127.0.0.1:6006/ ,即可查看部署的 WebDemo 聊天界面。运行效果如下:
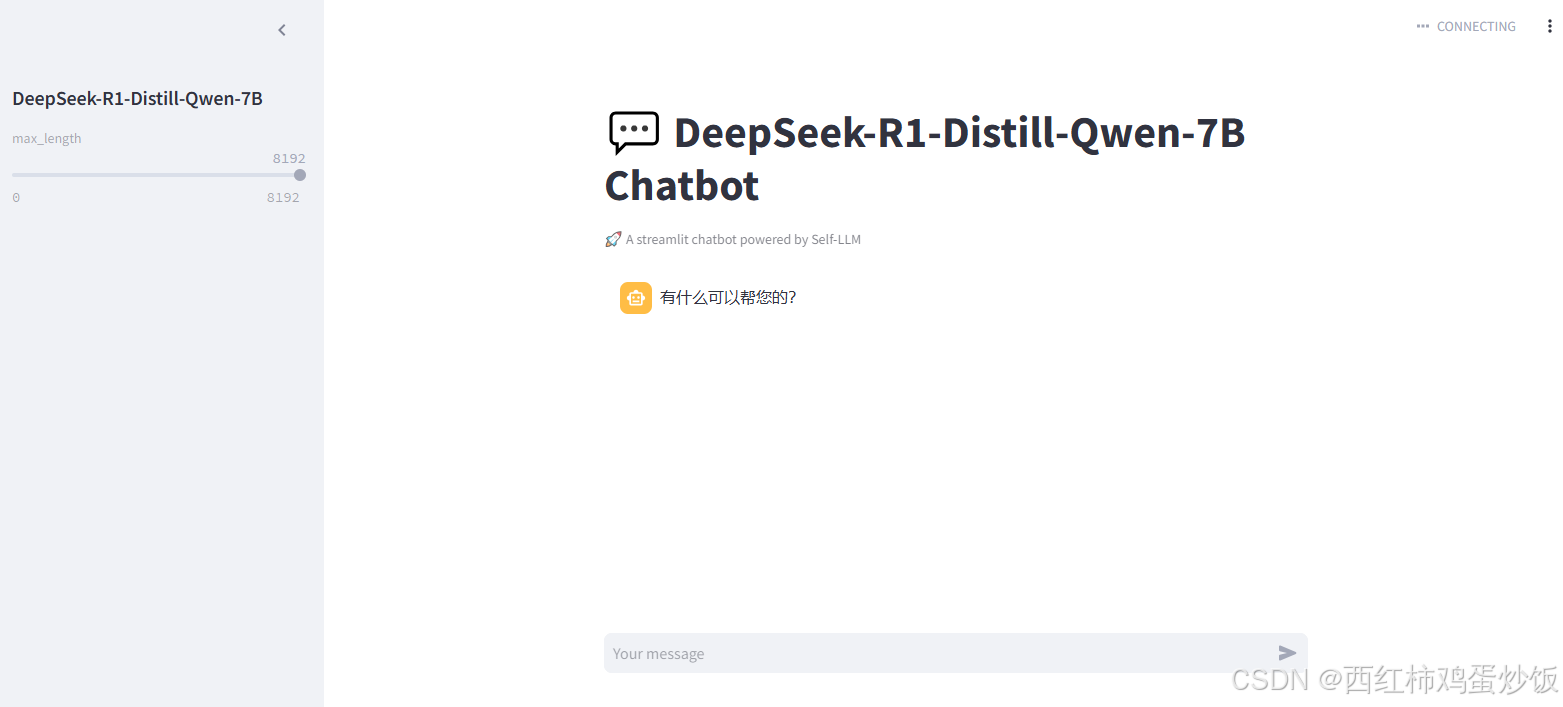
注意:出现下面展示表示运行成功。

2. API接口版本
1.环境准备
ubuntu 22.04 python 3.12 cuda 12.1 pytorch 2.3.0
首先 pip 换源加速下载并安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install requests==2.32.3
pip install fastapi==0.115.8
pip install uvicorn==0.34.0
pip install transformers==4.48.2
pip install huggingface-hub==0.28.1
pip install accelerate==1.3.0
pip install modelscope==1.22.32.模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
新建 model_download.py 文件并在其中输入以下内容,粘贴代码后请及时保存文件,如下图所示。并运行 python model_download.py 执行下载。
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir='/root/autodl-tmp', revision='master')3.代码准备
新建 api.py 文件并在其中输入以下内容,粘贴代码后请及时保存文件.
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM
import uvicorn
import json
import datetime
import torch
import re
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 文本分割函数
def split_text(text):
pattern = re.compile(r'<think>(.*?)</think>(.*)', re.DOTALL) # 定义正则表达式模式
match = pattern.search(text) # 匹配 <think>思考过程</think>回答
if match: # 如果匹配到思考过程
think_content = match.group(1).strip() # 获取思考过程
answer_content = match.group(2).strip() # 获取回答
else:
think_content = "" # 如果没有匹配到思考过程,则设置为空字符串
answer_content = text.strip() # 直接返回回答
return think_content, answer_content
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
prompt = json_post_list.get('prompt') # 获取请求中的提示
messages = [
{"role": "user", "content": prompt}
]
# 调用模型进行对话生成
input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to(model.device)
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=8192) # 思考需要输出更多的Token数,设为8K
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
think_content, answer_content = split_text(response) # 调用split_text函数,分割思考过程和回答
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"think": think_content,
"answer": answer_content,
"status": 200,
"time": time
}
# 构建日志信息
log = f"[{time}], prompt:\"{prompt}\", response:\"{repr(response)}\", think:\"{think_content}\", answer:\"{answer_content}\""
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map=CUDA_DEVICE, torch_dtype=torch.bfloat16)
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用4.Api 部署
python api.py结果线上成功

5.本地调用服务
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
if __name__ == '__main__':
print(get_completion('请写一份出行计划北京'))1.返回结果(思考内容结果)
D:\python\python312\.venv\Scripts\python.exe D:\workspace\pythonwork\spiderflow\deepseek_demo.py
<think>
嗯,用户让我写一份出行计划北京,我得先想想用户可能是谁。可能是一个游客,计划去北京旅游,或者是一个商务人士,要去北京出差。无论是哪种情况,用户都需要一个详细的计划,包括行程安排、交通、住宿、饮食等等。
首先,我应该确定用户的出发时间,是早上还是晚上出发。如果是旅游的话,可能早上出发比较合理,这样有更多时间安排景点。接着,列出主要的景点,比如故宫、天坛、长城这些必去的地方,还有现代景点比如鸟巢、水立方这些。
然后,考虑交通方式。北京的公共交通很发达,地铁和公交是主要的,但考虑到景点分散,可能需要打车或者包车,尤其是像故宫这样的景点,距离比较远,打车可能更快捷。另外,交通卡比较方便,可以提前买好一日票或者月票。
住宿方面,用户可能需要一个方便的位置,比如靠近故宫的住处,这样行程安排起来更方便。推荐一些不错的酒店,比如故宫附近的如家或者汉庭,这些酒店不仅方便,价格也适中。
饮食方面,北京有很多特色小吃,比如炸酱面、烤鸭、涮羊肉等等,可以推荐一些必吃的小吃地点,这样用户在游览的同时也能品尝当地的美食。
接下来,行程安排要合理,不要太赶,每个景点之间留有足够的时间,避免太疲劳。比如上午去故宫,中午吃饭,下午去天坛,下午去四合院区,晚上逛夜市或者看演出,这样安排比较合理。
另外,考虑到北京的季节,用户可能需要一些保暖衣物,比如羽绒服或者厚外套,还有防晒用品,尤其是出去玩的时候,紫外线很强。
预算方面,用户可能想知道大概的花费,包括交通、住宿、餐饮、门票和纪念品。我应该给出一个大概的预算范围,让用户心里有数。
最后,提醒用户注意一些细节,比如北京的天气、穿着要求、 tipping(小费)以及尊重当地的风俗习惯,这样可以避免不必要的麻烦。
总结一下,这份出行计划应该包括出发时间、行程安排、交通住宿、饮食、预算和注意事项,这样用户能全面了解北京旅行的各个方面,顺利安排行程。
</think>
以下是一份关于北京的出行计划模板,供您参考:
---
### **北京出行计划**
#### **出发时间:**
- **上午9:00** 出发前往北京,预计下午1:00到达北京。
---
### **行程安排:**
#### **上午:**
- **9:00 - 10:30** 抵达北京,入住酒店。
- **10:30 - 11:30** 抵达酒店,办理入住手续,休息。
#### **中午:**
- **12:00 - 14:00** 午餐:推荐在酒店附近的小吃店或餐厅品尝北京特色美食,如炸酱面、烤鸭、涮羊肉等。
#### **下午:**
- **14:00 - 17:30** 参观**故宫博物院**(建议乘坐地铁1号线或8号线到达故宫站,游览时间约3小时)。
- **14:00 - 16:00** 上午场次,参观主要景点如乾清宫、午门、太和殿等。
- **16:30 - 17:30** 下午场次,参观景仁宫、东华门、紫禁城等。
- **17:30 - 18:00** 午餐:在故宫附近的餐厅享用午餐。
- **18:00 - 19:30** 自由活动:可以在故宫附近的四合院里逛逛,或者去附近的商业区购物。
#### **傍晚:**
- **19:30 - 21:00** 参观**天坛公园**(建议乘坐公交或出租车前往,游览时间约2小时)。
- **19:30 - 20:30** 上午场次,参观圜丘、香山、中坛等景点。
- **20:30 - 21:00** 下午场次,参观后山景区。
- **21:00 - 21:30** 午餐:在天坛附近的餐厅享用午餐。
- **21:30 - 22:30** 自由活动:可以在天坛公园附近的小摊区购买纪念品,或者散散步。
#### **晚上:**
- **22:30 - 23:30** 参观**香格里拉四合院**(位于海淀区,是一个以藏族文化为主题的四合院,适合喜欢文化体验的游客)。
- **22:30 - 23:00** 入院参观,了解藏族文化。
- **23:00 - 23:30** 午餐:在四合院内的餐厅享用午餐。
- **23:30 - 晚上** 自由活动:可以在四合院附近的小摊区购买一些伴手礼,或者夜游北京,如乘坐夜游船或夜景巴士。
---
### **交通方式:**
1. **市内交通:**
- **地铁**:北京地铁覆盖范围广,方便快捷,推荐使用北京地铁卡。
- **公交**:北京公交网络发达,支持扫码或刷卡乘车。
- **出租车/网约车**:北京的出租车和网约车服务也非常方便。
2. **到达北京的交通方式:**
- **飞机**:北京首都国际机场(北京大兴国际机场)距离市区约30公里,乘坐机场快车约20分钟即可到达市中心。
- **火车**:北京西站、北京站是主要的火车站,乘坐地铁或公交可以快速到达城市中心。
---
### **住宿推荐:**
1. **故宫附近**:推荐选择靠近故宫的酒店,方便游览故宫和四合院区。
- **推荐酒店**:如**北京如家酒店**、**北京汉庭酒店**等。
2. **四合院住宿**:如果计划参观香格里拉四合院,可以选择附近提供藏族文化体验的民宿或酒店。
---
### **饮食推荐:**
1. **北京特色小吃**:
- **炸酱面**:推荐**三里屯炸酱面**或**79餐饮街**。
- **烤鸭**:推荐**德胜门烤鸭**或**圆明园烤鸭**。
- **涮羊肉**:推荐**后海涮羊肉**或**东直门涮羊肉**。
2. **夜市**:
- **三里屯商圈**:晚上逛三里屯的夜市,品尝地道的北京小吃和夜市美食。
- **三元里夜市**:位于三里屯,是一个以美食为主题的夜市。
---
### **预算参考:**
- **交通**:单日地铁或公交费用约50元,打车约100元。
- **住宿**:经济型酒店约200-300元/晚,四合院住宿约300-500元/晚。
- **餐饮**:每日约100元,总计约300元。
- **门票**:故宫门票约120元/人,天坛公园门票约60元/人。
- **纪念品**:约100-200元。
---
### **注意事项:**
1. **北京的天气**:北京四季分明,冬季寒冷,夏季炎热。根据季节准备相应的衣物。
2. **穿着要求**:建议穿轻便保暖衣物(冬季)或防晒衣(夏季),注意保暖。
3. ** tipping**:在餐厅和旅游景点,给服务员和导游 tipping(通常为10%-15%)。
4. **尊重当地风俗**:注意北京的传统文化和习俗,避免冒犯当地居民。
---
希望这份计划对您有所帮助,祝您在北京旅途愉快!
Process finished with exit code 02.服务器打印日志

3.租用服务器
本地部署服务器资源紧张,没有显卡,可以考虑租用服务器。
我选择autodl平台,
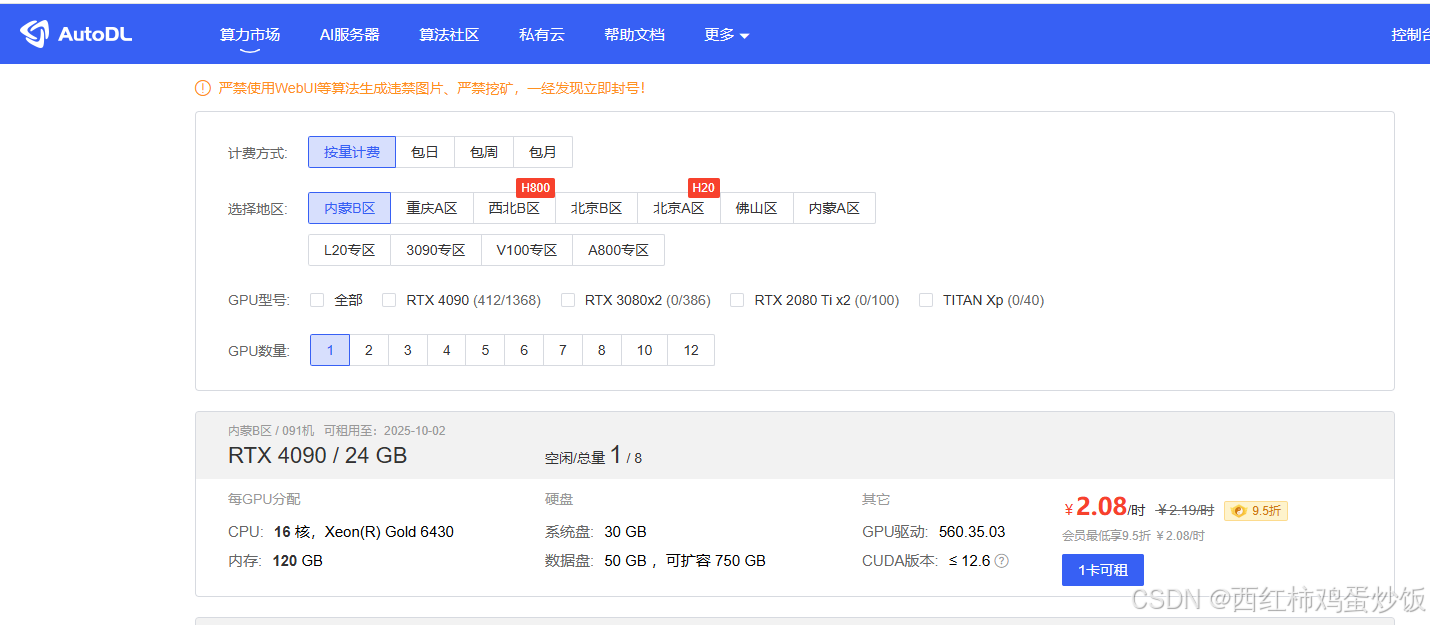

建议计费选着按日收费,主要是下载模型需要时间,耗时太长。看个人预算。

















 3178
3178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









