







文章目录
阿里模型基础
阿里大模型服务平台百炼,官方文档:https://help.aliyun.com/zh/model-studio/user-guide/model-calling
模型选型建议
通义千问-Max、通义千问-Plus 和通义千问-Turbo 均适用于智能客服、文本创作(如撰写文稿、文案创作)、文本润色以及总结摘要等多种场景。如果您暂时不确定选择哪个模型,建议优先尝试使用通义千问-Plus,它在效果、速度和成本上相对均衡。
推理能力:通义千问-Max > 通义千问-Plus > 通义千问-Turbo
响应速度:通义千问-Turbo > 通义千问-Plus > 通义千问-Max
三个模型都兼容OpenAI 调用方式,相关细节请参考如何通过OpenAI接口调用通义千问模型。
消息类型
您通过API与大模型进行交互时的输入和输出也被称为消息(Message)。每条消息都属于一个角色(Role),角色包括系统(System)、用户(User)和助手(Assistant)。
系统消息(System Message,也称为System Prompt):用于告知模型要扮演的角色或行为。例如,您可以让模型扮演一个严谨的科学家等。默认值是“You are a helpful assistant”。您也可以将此类指令放在用户消息中,但放在系统消息中会更有效。
用户消息(User Message):您输入给模型的文本。
助手消息(Assistant Message):模型的回复。您也可以预先填写助手消息,作为后续助手消息的示例。
OpenAI 兼容
import os
from openai import OpenAI
try:
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
# api_key=os.getenv("DASHSCOPE_API_KEY"),
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}
]
)
print(completion.choices[0].message.content)
except Exception as e:
print(f"错误信息:{e}")
print("请参考文档:https://help.aliyun.com/zh/model-studio/developer-reference/error-code")
langchian开发前置基础
Chat models 聊天模型
官方文档:https://python.langchain.com/docs/concepts/chat_models/
现代 LLMs 通常通过聊天模型界面进行访问,该界面将消息列表作为输入,并返回消息作为输出。
最新一代的聊天模型(chat models)提供了额外的功能:
- 工具调用:许多流行的聊天模型都提供原生工具调用 API。此 API 允许开发人员构建丰富的应用程序,使 LLMs 能够与外部服务、API 和数据库进行交互。工具调用还可用于从非结构化数据中提取结构化信息并执行各种其他任务。
- 结构化输出:一种使聊天模型以结构化格式(例如与给定架构匹配的 JSON)响应的技术。
- 多模态:能够处理文本以外的数据;例如,图像、音频和视频。
ps: 聊天模型是语言模型的一种变体,虽然它们在底层使用语言模型,但提供的接口不同,主要是以“聊天消息”作为输入和输出,而不是简单的“文本输入-文本输出”。
Integrations 集成
LangChain 有许多聊天模型集成,允许您使用来自不同提供商的各种模型。
这些集成是以下两种类型之一:
- 官方模型:这些是 LangChain 和/或模型提供商官方支持的模型。您可以在 langchain- 软件包中找到这些模型。
- 社区模型:有些模型主要由社区贡献和支持。您可以在 langchain-community 包中找到这些模型。
LangChain 聊天模型的命名约定是在其类名前加上 “Chat” 前缀(例如,ChatOllama、ChatAnthropic、ChatOpenAI 等)。
LangChain 也有较旧的 LLMs,它们不遵循聊天模型接口,而是使用将字符串作为输入并返回字符串作为输出的接口。这些模型通常不带 “Chat” 前缀(例如,Ollama、Anthropic、OpenAI 等)。这些模型实现了 BaseLLM 接口,并且可以用 “LLM” 后缀命名(例如,OllamaLLM、AnthropicLLM、OpenAILLM 等)。通常,用户不应使用这些模型。
Interface 接口
LangChain 聊天模型实现了 BaseChatModel 接口。由于 BaseChatModel 还实现了 Runnable Interface,因此聊天模型支持标准流式处理接口、异步编程、优化批处理等。有关更多详细信息,请参阅 Runnable 接口。
聊天模型的主要方法
聊天模型的主要方法包括:
-
invoke: The primary method for interacting with a chat model. It takes a list of messages as input and returns a list of messages as output.
invoke:与聊天模型交互的主要方法。它采用消息列表作为输入,并返回消息列表作为输出。 -
stream: A method that allows you to stream the output of a chat model as it is generated.
stream:一种方法,允许您在生成聊天模型时流式传输聊天模型的输出。 -
batch: A method that allows you to batch multiple requests to a chat model together for more efficient processing.
batch:一种允许您将对聊天模型的多个请求一起批处理以实现更高效处理的方法。 -
bind_tools: A method that allows you to bind a tool to a chat model for use in the model’s execution context.
bind_tools:一种方法,允许您将工具绑定到聊天模型,以便在模型的执行上下文中使用。 -
with_structured_output: A wrapper around the invoke method for models that natively support structured output.
with_structured_output:本机支持结构化输出的模型的 invoke 方法的包装器。
其他重要方法可以在 BaseChatModel API 参考中找到
输入和输出
现代 LLMs 通常通过聊天模型接口进行访问,该接口将消息作为输入,并将消息作为输出返回。消息通常与一个角色(例如,“系统”、“人类”、“助手”)和一个或多个包含文本或潜在多模式数据(例如,图像、音频、视频)的内容块相关联。
LangChain 支持两种消息格式与聊天模型交互:
- LangChain 消息格式:LangChain 自带的消息格式,默认使用,LangChain 内部使用。
- OpenAI 的消息格式:OpenAI 的消息格式。
Standard parameters 标准参数
许多聊天模型都有可用于配置模型的标准化参数:

- 标准参数仅适用于公开具有预期功能的参数的模型提供程序。例如,某些提供程序不会公开最大输出令牌的配置,因此这些提供程序不支持max_tokens。
- 标准参数目前仅在具有自己的集成包(例如 langchain-openai、langchain-anthropic 等)的集成上强制执行,它们不对 langchain-community 中的模型强制执行。
聊天模型还接受特定于该集成的其他参数。要查找 Chat 模型支持的所有参数,请前往该模型的相应 API 参考。
Tool calling 工具调用
聊天模型可以调用工具来执行任务,例如从数据库获取数据、发出 API 请求或运行自定义代码。有关更多信息,请参阅工具调用指南。
Structured outputs 结构化输出
可以请求聊天模型以特定格式(例如 JSON 或匹配特定架构)进行响应。此功能对于信息提取任务非常有用。请在结构化输出指南中阅读有关该技术的更多信息。
LangChain Python SDK
langchain分成不同的包:langchain-core、langchain-community和langchain
langchain包拆分为三个独立的包以改善开发人员体验
- langchain-core包含已作为标准出现的简单核心抽象,以及作为将这些组件组合在一起的方式的 LangChain 表达式语言。
- langchain-community包含所有第三方集成。独立的软件包。
- langchain包含更高级别和特定于用例的链、代理和检索算法。
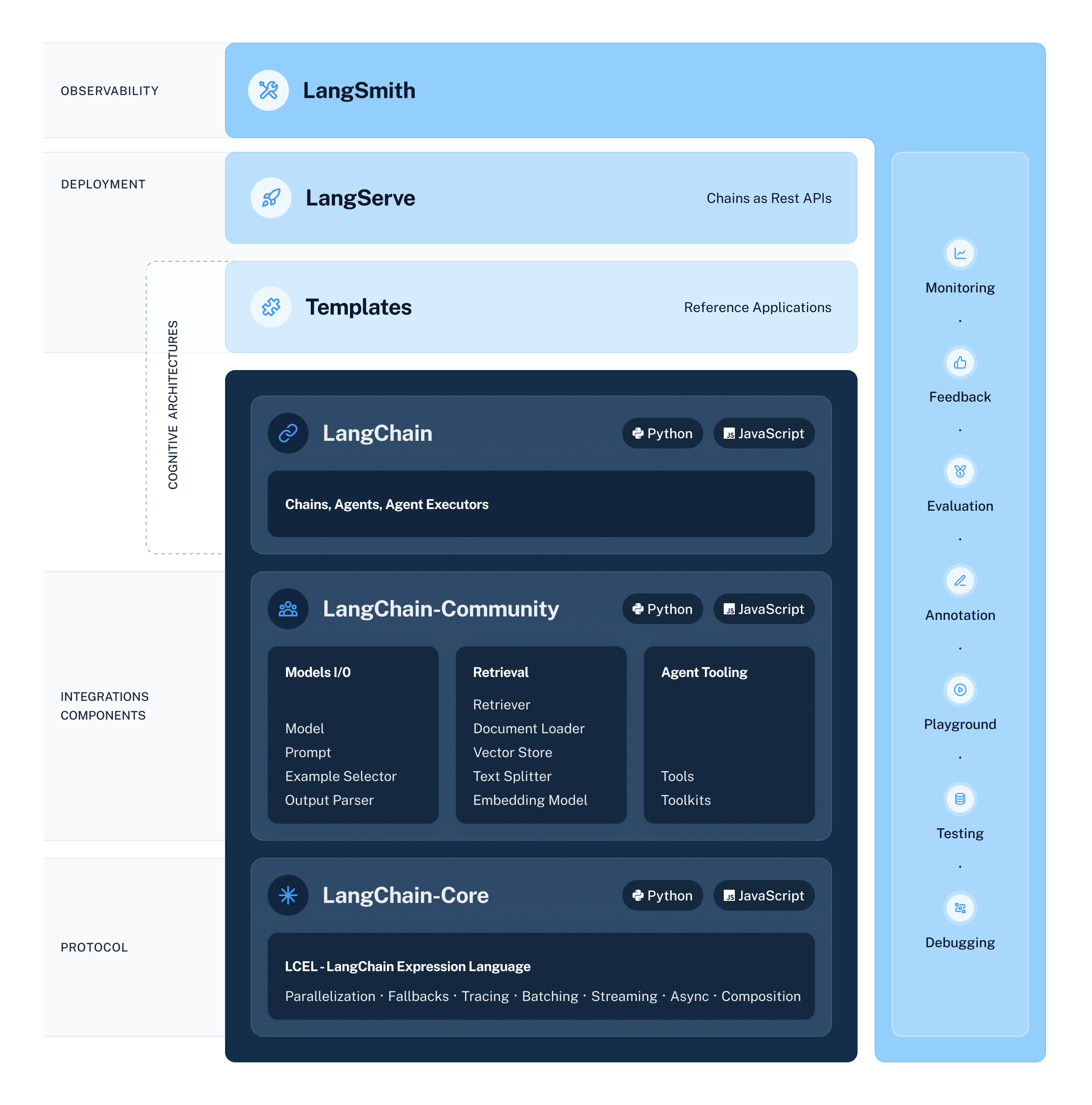
langchain-community
pip install langchain-community
比如,我们要是 模型 qwen-plus ,我们就需要安装langchain-community
ChatTongyi 类
ChatTongyi 类旨在简化与 Tongyi Qwen 聊天模型的交互,允许用户发送消息并接收响应,支持同步和异步操作。它还支持流式响应、工具调用和结构化输出。
- 类的实例化
用户可以通过导入该类并创建对象来实例化它,指定所需的模型和参数。例如:
from langchain_community.chat_models import ChatTongyi
tongyi_chat = ChatTongyi(
model="qwen-max",
# 其他参数...
)
- 同步调用:
用户可以发送一系列消息,每条消息是一个包含发送者类型(“system” 或 “human”)和消息内容的元组。invoke 方法处理这些消息并返回 AI 消息对象。
messages = [
("system", "你是一名专业的翻译家,可以将用户的中文翻译为英文。"),
("human", "我喜欢编程。"),
]
response = tongyi_chat.invoke(messages)
- 流式响应:
stream 方法允许用户以块的形式接收响应,这对于长消息特别有用。
for chunk in tongyi_chat.stream(messages):
print(chunk)
- 异步调用
该类支持异步操作,使用 ainvoke 方法进行非阻塞调用。这在需要高响应性的应用中尤其有用。
await tongyi_chat.ainvoke(messages)
- 工具调用
该类可以将工具(使用 Pydantic 模型定义)绑定到聊天模型,以增强其功能。例如,用户可以定义获取天气或人口数据的工具,并在聊天中调用它们。
from pydantic import BaseModel, Field
class GetWeather(BaseModel):
location: str
chat_with_tools = tongyi_chat.bind_tools([GetWeather])
ai_msg = chat_with_tools.invoke("今天哪个城市更热,哪个城市更大:洛杉矶还是纽约?")
- 结构化输出
该类可以返回结构化输出,通过定义 Pydantic 模型来指定期望的输出格式。这对于需要特定数据结构的应用非常有用。
class Joke(BaseModel):
setup: str
punchline: str
rating: Optional[int]
structured_chat = tongyi_chat.with_structured_output(Joke)
joke_response = structured_chat.invoke("给我讲一个关于猫的笑话")
- 响应元数据
response_metadata 属性提供有关响应的附加信息,例如模型名称、结束原因、请求 ID 和令牌使用统计信息。
ai_msg = tongyi_chat.invoke(messages)
metadata = ai_msg.response_metadata
使用模型 qwen-plus demo
基本使用
pip install dashscope
dashscope 是一个 API 客户端库,允许开发者与 Dashscope 平台进行交互。通过这个库,用户可以方便地调用各种 AI 模型,包括聊天、翻译、图像生成等功能。
安装 dashscope 和 langchain-community 是为了使用与阿里巴巴的 Tongyi Qwen 聊天模型相关的功能和工具。
总结
安装 dashscope 是为了能够访问和使用 Dashscope 平台上的 AI 模型。
安装 langchain-community 是为了利用其提供的工具和框架,快速构建基于语言模型的应用程序。
实例:
import os
from dotenv import load_dotenv
from langchain_community.chat_models import ChatTongyi
# 加载 .env 文件
load_dotenv()
api_base = os.getenv("PROXY")
api_key = os.getenv("API_KEY")
llm = ChatTongyi(
model="qwen-plus",
temperature=0,
api_key=api_key,
api_base=api_base,
max_tokens=512,
)
messages = [
("system", ""),
("human", "你知道西京刀客是谁吗?"),
]
response = llm.invoke(messages)
print(response)
# for chunk in llm.stream("你知道西京刀客是谁吗?"):
# print(chunk, end="", flush=False)
Tools
官方文档:https://python.langchain.com/docs/integrations/tools/
工具是设计为由模型调用的工具:它们的输入设计为由模型生成,其输出设计为传递回模型。
支持的在线搜索的工具: https://python.langchain.com/docs/integrations/tools/
使用 DuckDuckGo 进行搜索并将结果传递给 LangChain 模型
官方文档:https://python.langchain.com/docs/integrations/tools/ddg/
LangChain 确实提供了一些内置的工具,可以直接用于网页搜索。你可以使用 DuckDuckGo 或 SerpAPI 等工具来实现搜索功能。以下是如何使用 LangChain 中的 DuckDuckGo 搜索工具的示例。
pip install -U duckduckgo-search
注意:
警告提示直接从 langchain 导入工具已被弃用。你应该改为从 langchain-community 导入。更新你的导入语句如下:
新版本从langchain_community.tools 导入
from langchain_community.tools import DuckDuckGoSearchResults
import os
from dotenv import load_dotenv
from langchain_community.chat_models import ChatTongyi
from langchain_community.tools import DuckDuckGoSearchResults
# 加载 .env 文件
load_dotenv()
# 从环境变量中获取 API 配置
api_base = os.getenv("PROXY")
api_key = os.getenv("API_KEY")
# 初始化 DuckDuckGo 搜索工具
duckduckgo_tool = DuckDuckGoSearchResults()
# 初始化 ChatTongyi 模型
llm = ChatTongyi(
model="qwen-plus",
temperature=0,
api_key=api_key,
api_base=api_base,
max_tokens=512,
)
# 用户查询
user_query = ("西京刀客是谁?")
# 使用 DuckDuckGo 搜索工具进行查询
search_results = duckduckgo_tool.run(user_query)
print(search_results)
# 处理搜索结果,提取相关信息
if search_results and 'RelatedTopics' in search_results:
# 提取前几个结果的标题和链接
context = "\n".join(
[f"{topic['Text']}: {topic['FirstURL']}" for topic in search_results['RelatedTopics'] if 'Text' in topic and 'FirstURL' in topic]
)
else:
context = "没有找到相关结果。"
# 将搜索结果作为上下文传递给 ChatTongyi 模型
final_query = [
{"role": "system", "content": "你是一个智能助手。"},
{"role": "user", "content": f"根据以下信息回答问题:\n{context}\n\n问题:{user_query}"}
]
# 使用 invoke 方法生成响应
response = llm.invoke(final_query)
# 打印最终响应
print(response)



















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











