






1 梯度下降法
参考链接:梯度下降法(Gradient Descent) – 现代机器学习的血液
2 微分理解
1、我们所要优化的函数必须是一个连续可微的函数,可微,既可微分,意思是在函数的任意定义域上导数存在。如果导数存在且是连续函数,则原函数是连续可微的。
2、函数图像中,某点的切线的斜率
3、函数的变化率

3 梯度理解


4 数学解释
5 手工求解
问题描述:
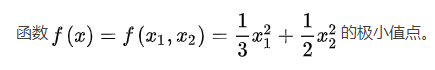
计算过程:

6 演示梯度下降法的数据变化

- 初始设定

- 计算位移量

- 更新位置

- 反复执行2和3的操作

函数 z zz 在 (1,0) 处取得最小值 0
7 Python 编程
- 导入所需库
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import math
from mpl_toolkits.mplot3d import Axes3D
import warnings
- 函数定义
def Z(x,y):
return 2*(x-1)**2 + y**2
# x方向上的梯度
def dx(x):
return 4*x-4
# y方向上的梯度
def dy(y):
return 2*y
- 赋初值
X = x_0 = 3
Y = y_0 = 2
# 学习率
alpha = 0.1
- 定义数据保存列表
globalX = [x_0]
globalY = [y_0]
globalZ = [Z(x_0,y_0)]
- 重复迭代30次
for i in range(30):
temX = X - alpha * dx(X)
temY = Y - alpha * dy(Y)
temZ = Z(temX, temY)
# X,Y 重新赋值
X = temX
Y = temY
# 将新值存储起来
globalX.append(temX)
globalY.append(temY)
globalZ.append(temZ)
- 打印结果
print(u"最终结果为:(x,y,z)=(%.5f, %.5f, %.5f)" % (X, Y, Z(X,Y)))
print(u"迭代过程中取值")
num = len(globalX)
for i in range(num):
print(u"x%d=%.5f, y%d=%.5f, z%d=%.5f" % (i,globalX[i],i,globalY[i],i,globalZ[i]))

- 绘制过程图
axisX = np.arange(-4,4,0.2)
axisY = np.arange(-4,4,0.2)
axisX, axisY = np.meshgrid(axisX, axisY) # 生成xv、yv,将axisX、axisY变成n*m的矩阵,方便后面绘图
valueZ = np.array(list(map(lambda t : Z(t[0],t[1]),zip(axisX.flatten(),axisY.flatten()))))
valueZ.shape = axisX.shape # 1600的Z图还原成原来的(40,40)
%matplotlib inline
#作图
fig = plt.figure(facecolor='w',figsize=(12,8))
ax = Axes3D(fig)
ax.plot_surface(axisX,axisY,valueZ,rstride=1,cstride=1,cmap=plt.cm.jet)
ax.plot(globalX,globalY,globalZ,'ko-')
ax.set_title(u'$ z=2×(x-1)^2 + y^2 $')
ax.set_xlabel(u'x')
ax.set_ylabel(u'y')
ax.set_zlabel('z')
plt.show()
';
















 1427
1427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









