






1、逻辑回归的含义
Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalizedlinear model)。
这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
如果是连续的,就是多重线性回归;
如果是二项分布,就是Logistic回归;
如果是Poisson分布,就是Poisson回归;
如果是负二项分布,就是负二项回归。
Logistic回归的主要用途:
寻找危险因素:寻找某一疾病的危险因素等;
预测:根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
判别:实际上跟预测有些类似,也是根据模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病
2、 查准率与查全率
对于二分类问题,分类结果混淆矩阵与查准/查全率定义如下

3、F-Score
定义:P和R指标有时会出现矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure,又称F-Score。F-Measure是P和R的加权调和平均,即:
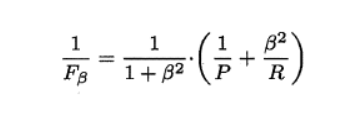
F1-score:特别地,当β=1时,也就是常见的F1度量,是P和R的调和平均,当F1较高时,模型的性能越好。

4、实践应用
1、问题描述
目标图像识别系统识别的效果
实验结果如下:
算法1(产品1)的检测结果:检测出“男生”人数82人,其中78人为男生,4人其实是女生;
算法2(产品2)的检测结果:检测出“男生”人数88人,其中80人为男生,8人其实是女生;
经过人工检测,视频中实际准确的总人数为100人,其中男生80人,女生20人。
判断哪种算法更好?
2、获取混淆矩阵
算法1

算法2

3、计算查准率,查全率,F1-score
算法1
查准率:
P = 78 78 + 2 = 0.975 {P=\frac{78}{78+2}=0.975}P=
78+2
78
=0.975
查全率:
R = 78 78 + 4 = 0.9512 {R=\frac{78}{78+4}=0.9512}R=
78+4
78
=0.9512
F1-score:
F 1 = 2 ∗ 78 100 + 78 − 16 = 0.963 {F1=\frac{278}{100+78-16}=0.963}F1=
100+78−16
2∗78
=0.963
算法2
查准率:
P = 80 80 + 0 = 1 {P=\frac{80}{80+0}=1}P=
80+0
80
=1
查全率:
R = 80 80 + 8 = 0.91 {R=\frac{80}{80+8}=0.91}R=
80+8
80
=0.91
F1-score:
F 1 = 2 ∗ 80 100 + 80 − 12 = 0.952 {F1=\frac{280}{100+80-12}=0.952}F1=
100+80−12
2∗80
=0.952
评估算法
4、从查准率评价指标来看,算法2都要优于算法1,从查全率和F1度量评价指标来看,算法1都要优于算法2。总的来说,算法2更好。















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









