







 本文介绍了基于文本向量空间模型(VSM)的文本聚类算法,通过文本预处理、计算词频、归一化、IDF频率加权和TF-IDF加权来确定文本的相似度,从而实现文本的自动分类和组织。
本文介绍了基于文本向量空间模型(VSM)的文本聚类算法,通过文本预处理、计算词频、归一化、IDF频率加权和TF-IDF加权来确定文本的相似度,从而实现文本的自动分类和组织。
基于文本向量空间模型的文本聚类算法
@[vsm|向量空间模型|文本相似度]
本文源地址http://www.houzhuo.net/archives/51.html
vsm概念简单,把对文本内容的处理转化为向量空间中的
向量计算,以空间上的相似度来直观表达语义上的相似度。
目录
文本聚类
文本聚类主要依据聚类假设:同类的文档相似度较大,非同类的文档相似度较小。作为一种无监督的机器学习方法,聚类由于不需要训练过程、以及不需要预先对文档手工标注类别,因此具有较高的灵活性和自动化处理能力,成为对文本信息进行有效组织、摘要和导航的重要手段。
向量空间模型vsm
所有的文本都可表现成向量的形式:
向量中的每一维都代表在文档中出现的一个独立词组或单个词,并且我们给每个词组赋予一个权值(最简单就是词频,或者广为人知的tf_idf权重)。所以一个文档就会转换成一个n维的向量。向量夹角公式
接下来就是利用中学所学的的公式来计算向量之间的夹角,夹角越小即代表较高的相似度。当然,我们比较之前需要将两个向量转化为同一维度(下面的代码中将加以演示)
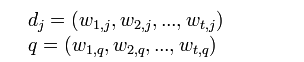
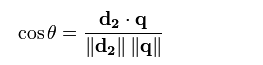
文本预处理:
__author__ = 'iothz'
import string
from string import *
list_of_all_file =[]
str_of_file1 = ""
str_of_file2 = ""
file1 = open('science.txt', 'r')
for line in file1.readlines():
nopunc =line.replace(",", "").replace(".", "").replace("?", "").replace("\"", "").replace("\'", "").replace(")", "").replace("(", "").replace("[", " ").replace("]", " ").replace("\n", " ")
str_of_file1 +=nopunc
list_of_all_file.append(str_of_file1)
file2 = open('science2.txt', 'r')
for line in file2.readlines():
nopunc =line.replace(",", "").replace(".", "").replace("?", "").replace("\"", "").replace("\'", "").replace(")", "").replace("(", "").replace("[", " ").replace("]", " ").replace("\n", " ")
str_of_file2 +=nopunc
list_of_all_file.append(str_of_file2)文本预处理方法各不相同,上面代码去除两个文本的标点,并添加到一个list中方便下面处理
获取每篇文档词频
from collections import Counter
def build_lexicon(corpus):
lexicon = set()
for doc in corpus:
lexicon. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









