









 本文探讨了数据科学中精准营销的两阶段预测模型,详细介绍了数据准备步骤,包括问题类型发现、变量筛选方法,以及分类和连续变量的压缩策略。重点讲解了分类变量的重编码、基于目标变量的转换-WOE,连续变量的主成分分析和变量聚类思路。
本文探讨了数据科学中精准营销的两阶段预测模型,详细介绍了数据准备步骤,包括问题类型发现、变量筛选方法,以及分类和连续变量的压缩策略。重点讲解了分类变量的重编码、基于目标变量的转换-WOE,连续变量的主成分分析和变量聚类思路。
数据科学 13 精准营销的两阶段预测模型(概念)
13.1 总体思路
13.1.1 数据准备步骤

- 粗筛,变量好几千:用pearson,spearman
- 变量100以内时:用IV方法
- 变量30-50时:逐步法
1、 发现数据问题类型
- 脏数据或数据不正确
- 比如 ‘0’ 代表真实的0,还是代表缺失;Age = -2003
- 数据不一致
- 比如收入单位是万元,利润单位是元,或者一个单位是美元,一个是人民币
- 数据重复
- 这个问题在前面已经解决
- 缺失值
- 离群值
2、 不要将变量筛选全放到建模的时候
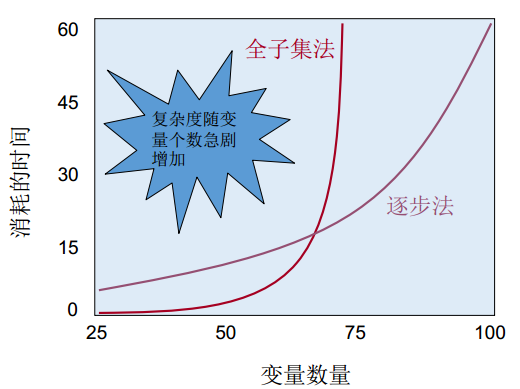
13.2.2 解决方案
1、 简单方案
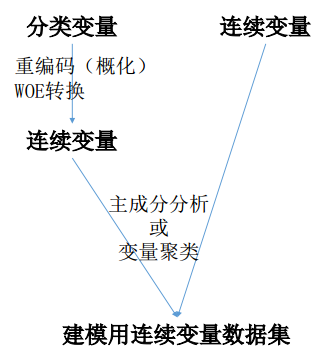
2、 建模标准流程(适用于工业场景)
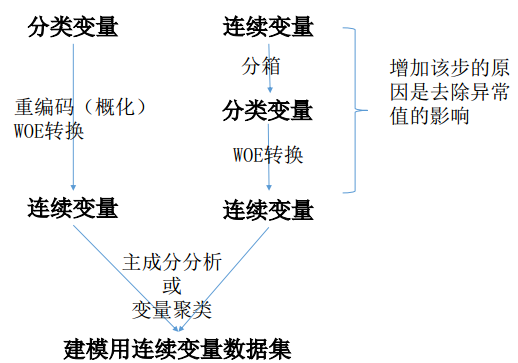
13.2 分类变量的压缩
13.2.1 水平变量编码转换

1、分类变量重编码(概化)
- A 分类变量的哑变量编码法
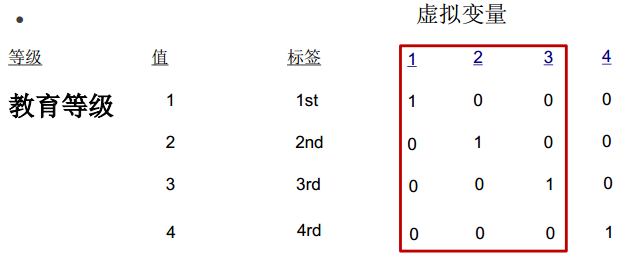
- B 当水平数较多时
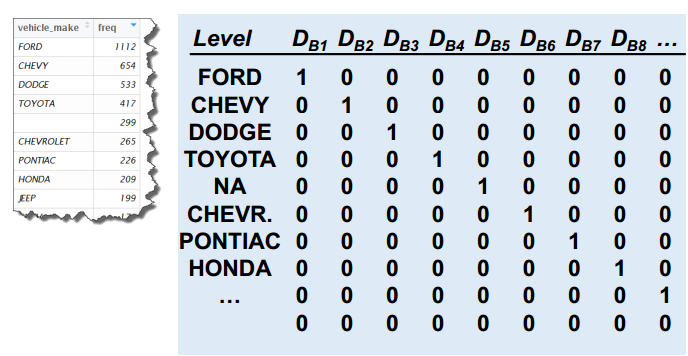
汽车制造商(vehicle_make)这个变量有155个水平,要生成154个哑变量。(占用大量自由度,其最致命的问题在下面)
- C Quasi-Complete问题(似不完整数据问题)
()

由于某个水平中, Y缺乏变异而导致无法计算。
由于这份数据中的许多汽车制造商只有一条记录,因此无法直接将这个变量直接纳入分类模型中。(解决方法,如下)
- D 合并不同水平
- 方法1:将频次少的水平简单合为一类,看上去简单,但是精度降低不大,问题是水平数依然不少。(将频次少的合为other)
- 方法2:根据每个水平Y=1的占比, 将值接近的划分为一类。本步骤手工处理比较麻烦,将来学了决策树之后,可以使用该技术进行处理。
- 合并后保留10-20个水平合适


压缩之后的分类变量还是会生成若干个哑变量。从道理上讲,在后续建模中,由一个分类变量生成的哑变量要么同时在模型中,要么都不在模型中。但是在模型选择变量时不能满足这个要求,因此较好的方法是将分类变量转换为连续变量。
2、 基于目标变量的转换-WOE(基于证据的权重调整)
**不要使用原始变量进行WOE转换** ,**要使用重分组后变量进行WOE转换**
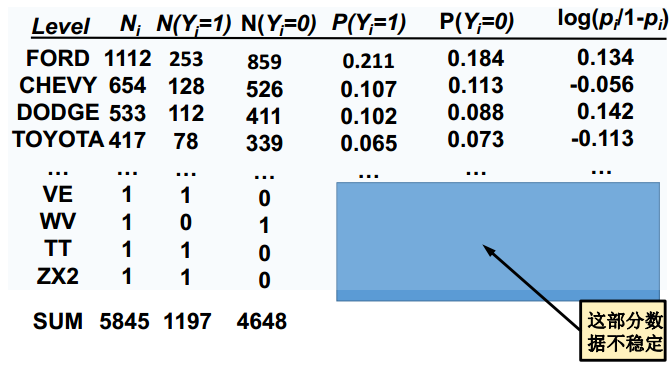
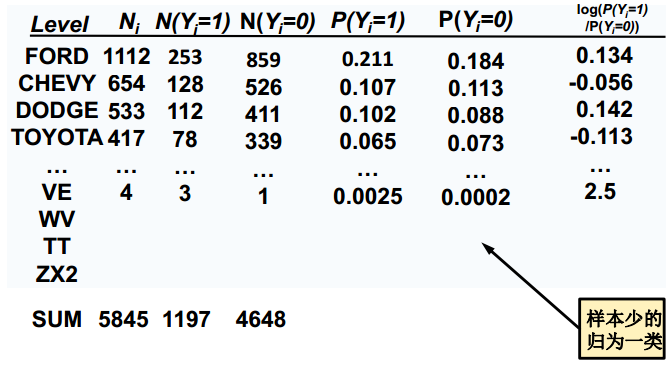
经过woe转换,变量变成连续变量。(第二张图的最后一列
l
o
g
(
P
(
Y
i
)
/
P
(
Y
i
=
0
)
)
log(P(Y_i)/P(Y_i=0))
log(P(Yi)/P(Yi=0))即为转换后的变量)
说明:
基于目标变量的转换是一种思路,实际工作中的实现方法很多,目前本节讲的是思路最简单,但是操作很麻烦的做法,实际工作中并不经常使用。
13.3 连续变量的压缩

13.3.1 主成分分析的思路
主成分分析,是考察多个变量间相关性一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关。

13.3.2 变量聚类思路



















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











