







0. 前言
- 相关资料:
- 论文基本信息
- 领域:Transformer & CV
- 作者单位:谷歌
- 发表时间:2020.11
- 一句话总结:使用纯Transformer用于图像识别
1. 要解决什么问题
-
之前在CV中,attention一般用于卷积网络中,或者用于替换CNN的一部分(但总体还是CNN结构)。
2. 用了什么方法
- 通过实验,作者发现以下情况
- 对于中等数据集(如ImageNet),Transformer的效果不如现在的SOTA结构。可能原因是Transformer没有CNN的translation equivariance(平移不变性)和locality(不知道怎么翻译,获取局部信息的能力?)
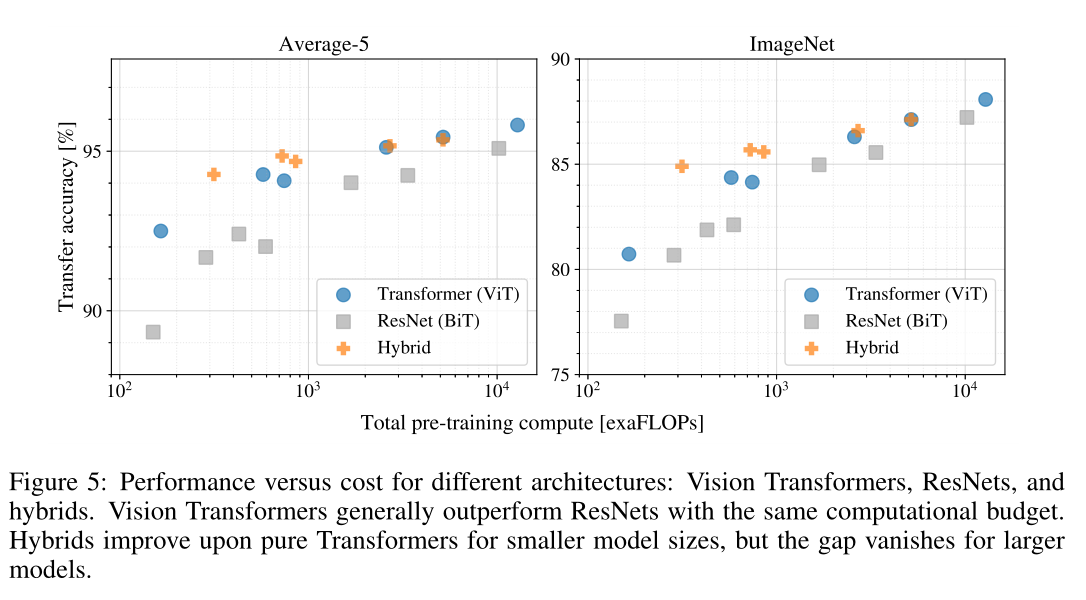
- 对于大型数据集(14M-300M图像),效果SOTA。
- 本文网络特点
- 尽可能使用原始Transformer结构。
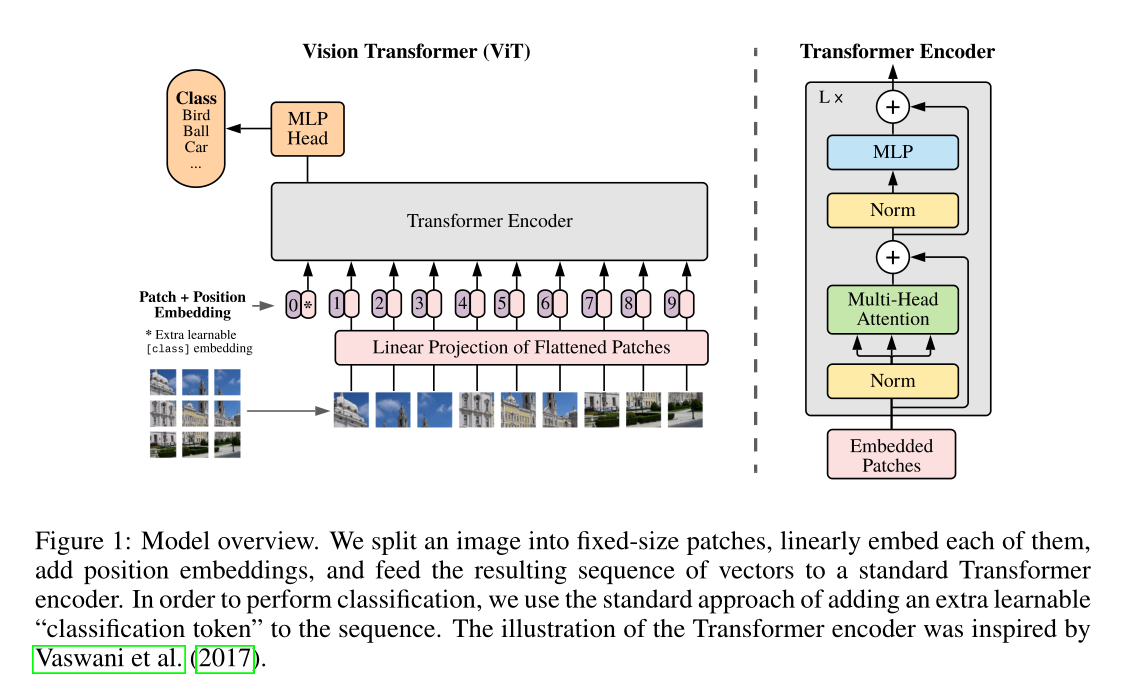
- 对于输入图像进行切片,每个切片之间没有重叠,将切片结果作为Transformer的序列输入。
- 即将HxWxC的图像转换为 Nx(P^2 x C),其中 N = HW/P^2
- 在处理更大尺寸图片时,每个Patch的尺寸不变,序列长度增加。
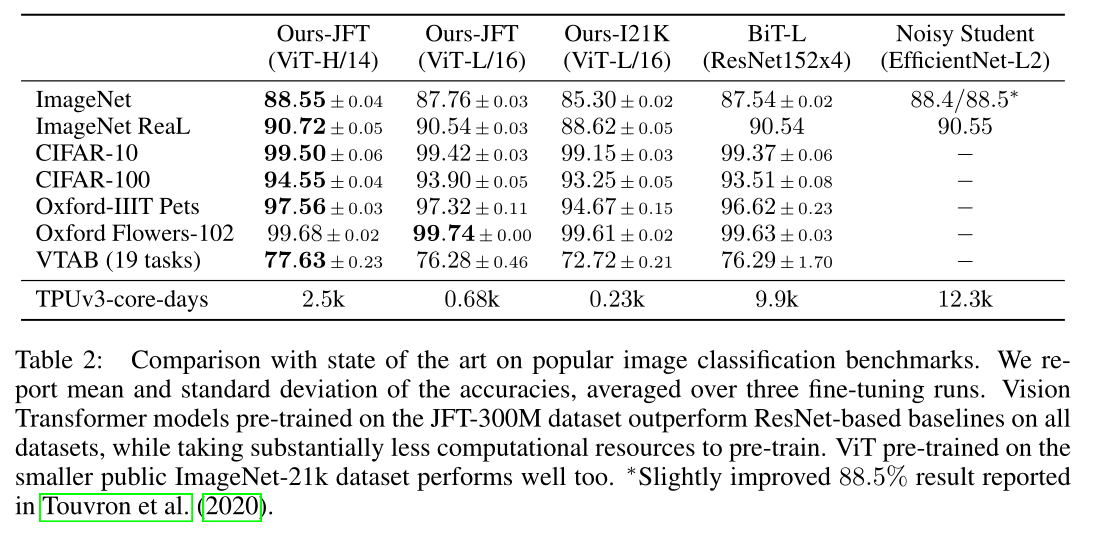
3. 效果如何
- 大数据集上效果可以
4. 还存在什么问题&可借鉴之处
- 这个数据patches有点意思,不过也有点卷积的意思。















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









