







0. 前言
- 在B站黄雍涛博士发了几个深度学习编译器的视频,感觉说得挺好,所以记录一下。
深度学习编译器(一)综述
-
深度学习编译器的作用:加速推理。
-
深度学习编译器总架构
- 一般分为前端与后端。
- 前端:把各种各样的模型转换为编译器认识的形式(如TVM的Relay,一般都是DAG的形式),再进行各类图优化、算子融合等(都属于经典的《编译原理》的一部分)。
- 后端:内核库(说白了就是加速矩阵乘法)以及代码生成(如LLVM/CUDA)
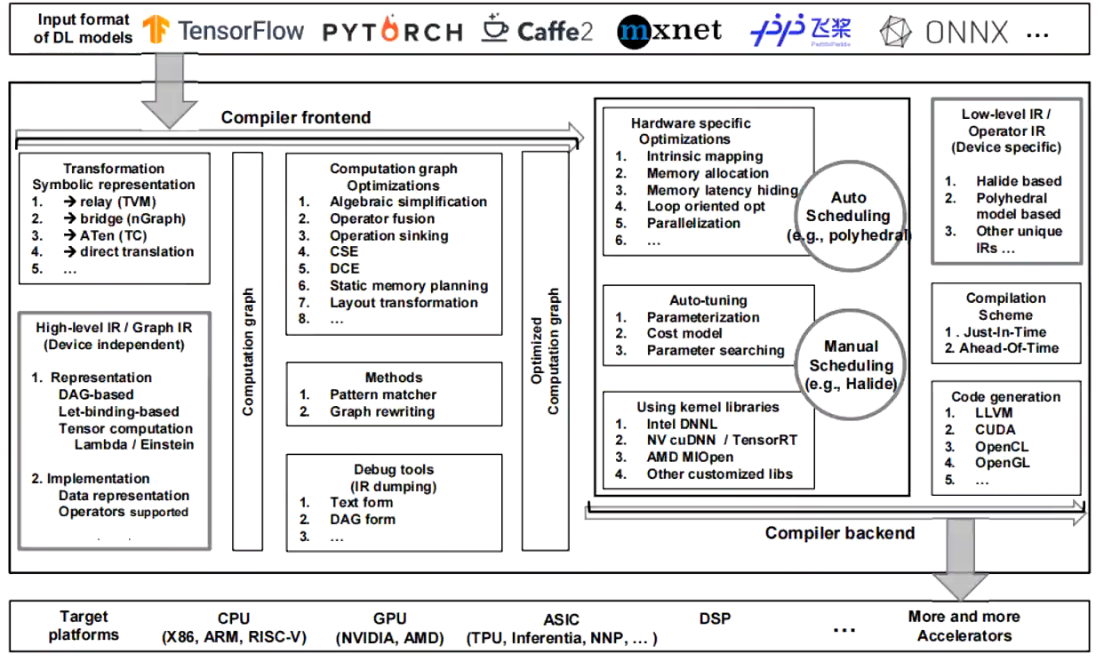
- 前端和高层IR
- IR,Intermediate representation,就是中间表达
- 从图论、数学的角度来考虑深度学习加速问题。
- 图的表示方法
- DAG:有向无环图
- Let-binidng:直接指向重要节点的输出。更多信息可参考这里
- 图计算的优化举例:Conv+BN+Relu
src/relay/transforms/fuse_ops.cc- 具体算法是“支配树算法”
- 后端和低层IR
- 从计算机低层的角度来考虑加速问题,如硬件设备、指令集、内核库。
- 各大厂有各自实现的内核库,如 intel 的 mkl+dnnl/openvino,nvidia的 cuda+cudnn/tensorrt
- 代码生成器:LLVM
- 看结构与TVM非常类似(第一代前端就是叫NNVM,致敬LLVM)
- 如果在CPU上进行模型优化,肯定会用到llvm
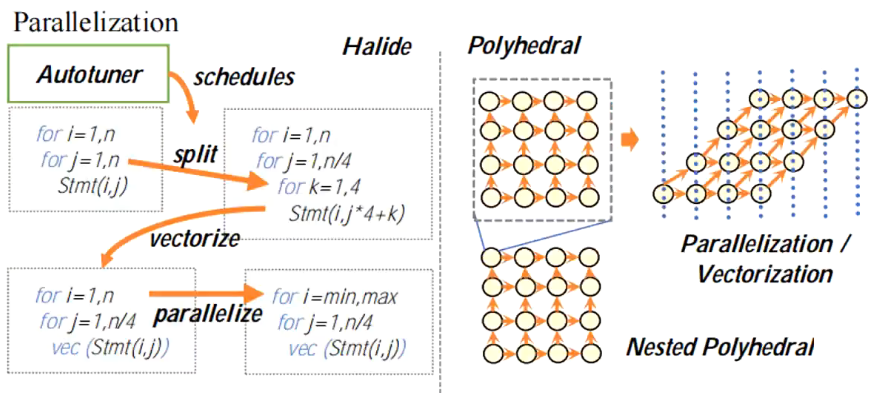
- 低层运算IR
- 有两种形式:Halide和Polyhedral
- TVM使用的就是Halide,有自动调节(Autotuner)功能,即有split/vectorize/parallelize等加速方法。
- Polyhedral(多面体模型),感觉就是更好地利用缓存?
深度学习编译器(二)Auto TVM
-
参考资料:
-
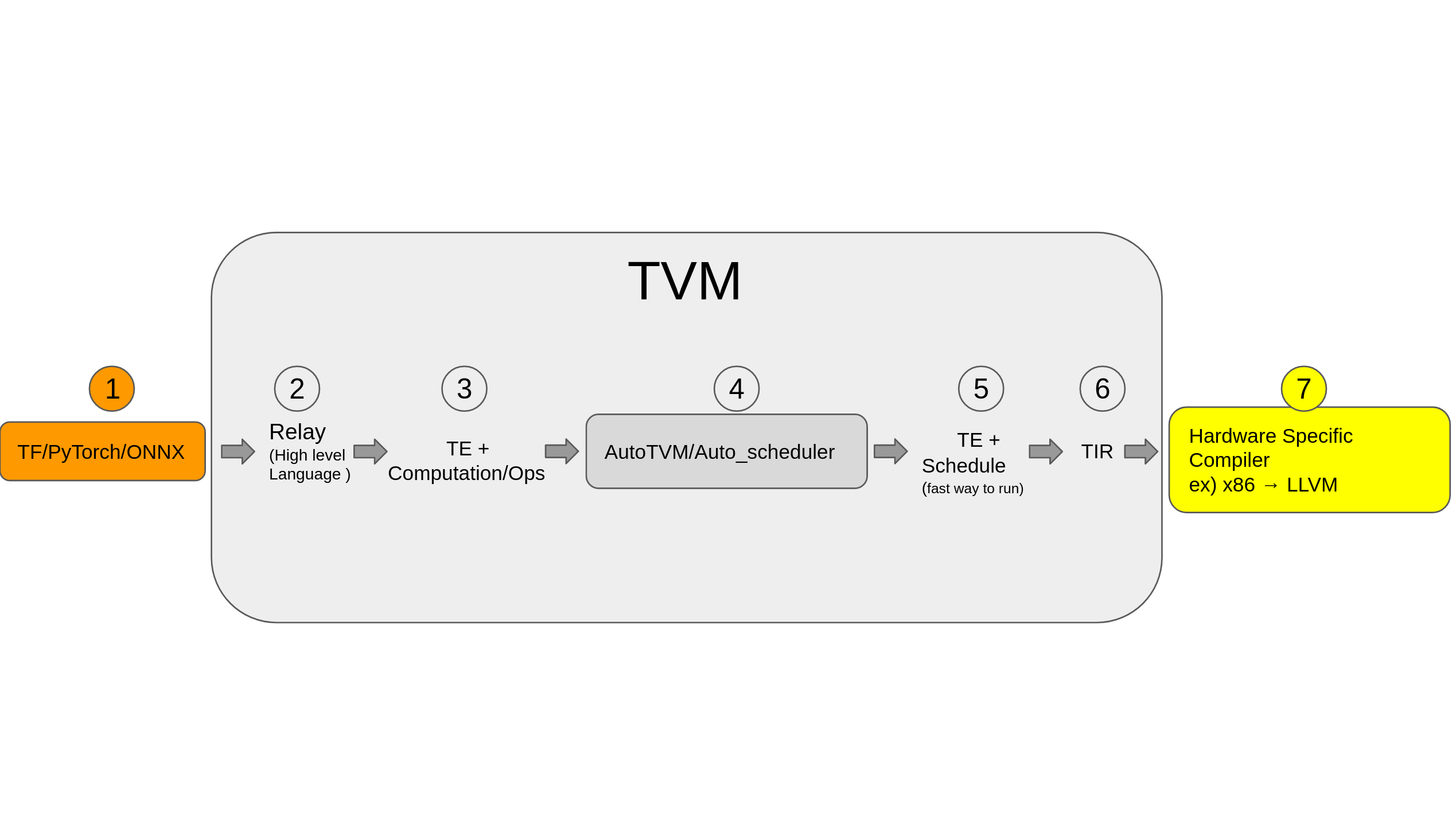
TVM 总体结构(图来自官网)
- 1:训练框架结果以及ONNX
- 2:TVM 高层表达 Relay IR
- 3:TE 张量表达
- 4:优化张量计算的具体执行流程
- 5:TE Schedule 调度
- 6:硬件底层可识别的 TIR
- 7:硬件(如图中的x86)
- TVM 与 NCNN/MNN 等的区别
- NCNN/MNN等:手写汇编
- TVM:AutoTVM
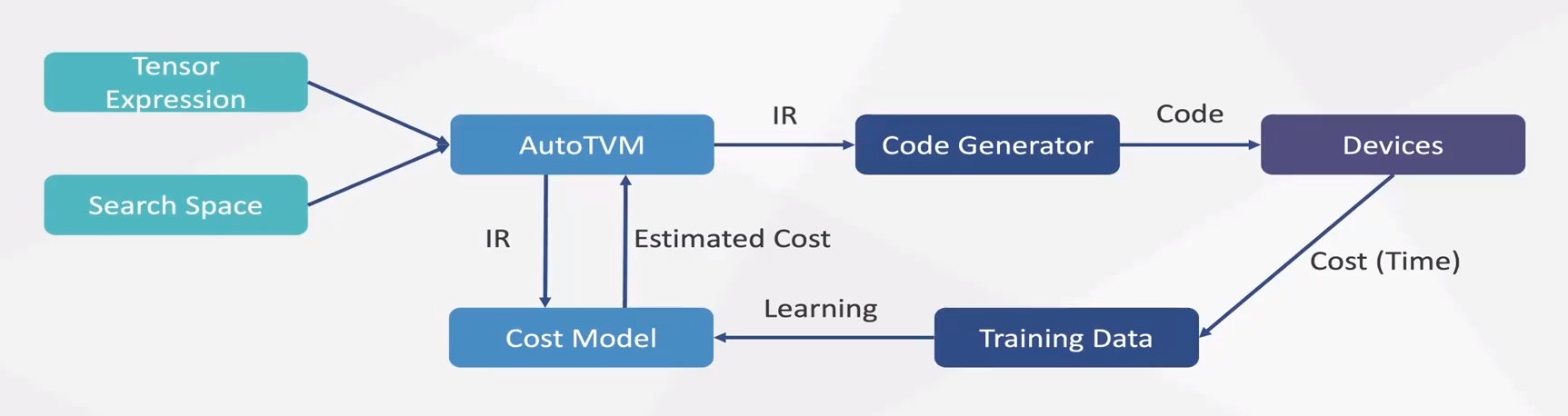
- AutoTVM
- 在用户定义的 Search Space 中具体执行 TE 的优化,tuning整个过程,通过 Cost Model 找到消耗最少的模型,生成json文件。
- 两个疑问
- Search Space 是什么?优化了什么?
- Search Space 介绍(自动调度优化了什么)
- 举了一个矩阵乘法的例子
- 左边是普通方式计算,上面是代码,下面是计算流程
- 中间是使用了 loop tiling 进行优化,本事就是分治。
- 具体分多大根据硬件不同需要尝试。
- TVM 就是
- 右边可以看到,在分块后,每块利用高效算子(充分利用缓存等资源)计算

- AutoTVM 流程
- 构建 Runner 和 Builder,运行tune以及构建Task
- 创建搜索任务,模版中可选参数和搜索任务绑定。
- 使用tune进行本地测试,记录测试结果。
- 调用测试结果,将最优结果填入模版,生成调度,实际计算。
深度学习编译器(三) Auto Schedule
-
AutoSchedule 就是 Ansor 的实现。
-
AutoTVM与AutoSchedule的区别
- AutoTVM是基于模版(template)的,而AutoSchedule没有模版(template-free)
-
Schedule常用原语:split/reorder/fuse/compute-at/tile/parallel/vectorize/unroll/bind/compute-inline
- AutoTVM最常用的是split、tile,其他很少
- AutoTVM会经常用到其他类型
-
什么是 template?
- 我个人感觉是,操作(原语)都已经确定了(可能不止一套),但各个原语的参数没有确定。
-
Template 的优缺点
-
Ansor 论文(即AutoSchedule)
-
缺点:
- 模版代码量很大(TVM中超过15k)。如果要新的硬件平台、新的算子,就需要新的模版。
- 都是局部优化,而不是全局优化。换句话说,都是针对单个算子的优化。
-
Template-free的优点
- 不需要不停添加template
- 准全局优化(如conv+bn+relu的fuse),又如(mattrans+matmul+softmax)
- 扩展了搜索空间
- 搜索的速度更快(auto-tune的时间)
- 推理速度更快(效果更好)
-
-
并行化外循环,矢量化、展开内循环
-
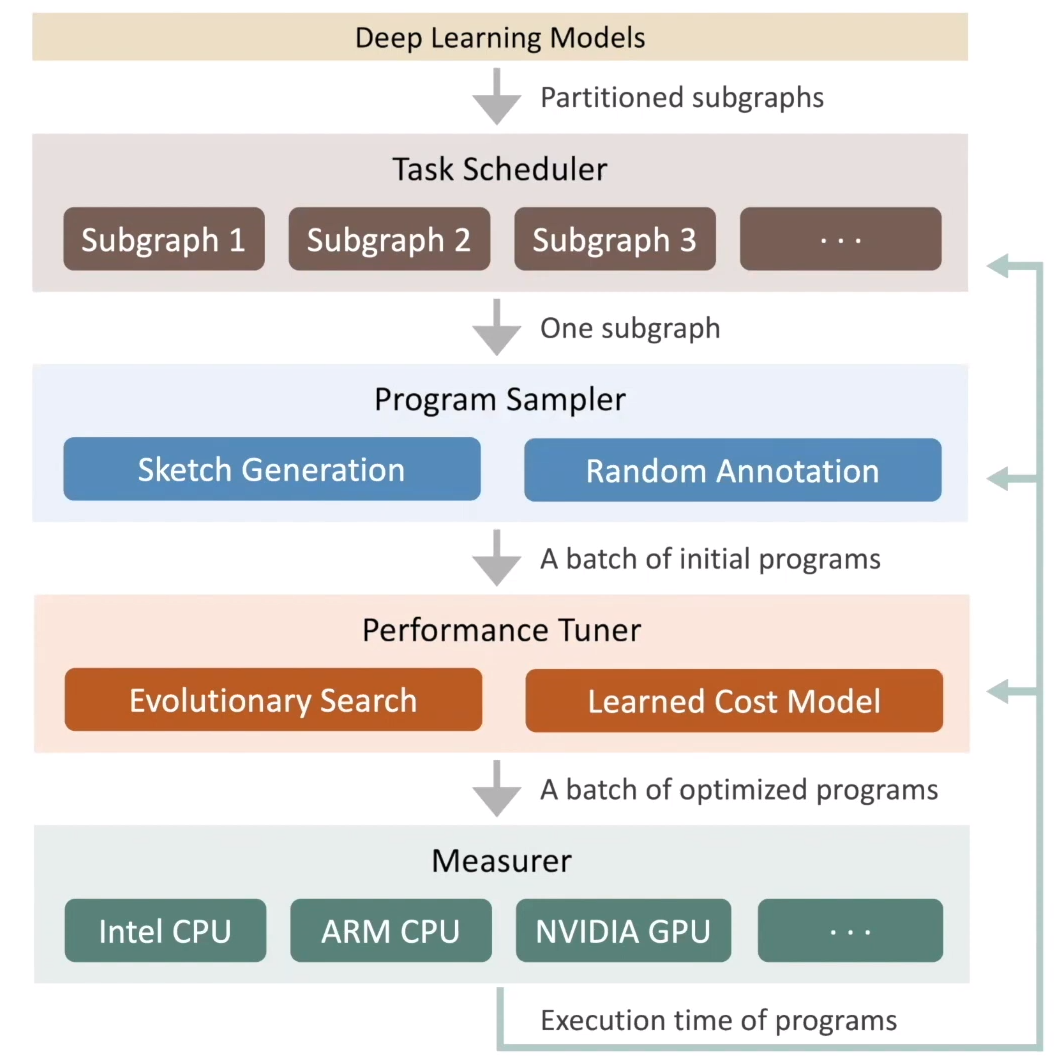
AutoSchedule的流程如下图所示
- 推荐看这个视频
- Task Scheduler(任务调度器):为优化模型中的多个子图,并分配时间资源
- 为什么是“准全局优化”?因为优化的是子图。
- Program Sampler(程序采样器):构造打的搜索空间,并从中采样不同的程序
- 先生成一个草图(可以看成是一个模版,但不是固定的模版)
- Performance Tuner(性能微调器):微调采样到程序的性能
- 进化算法、XGB就在这里,预估程序运行时间
- 使用过程与AutoTVM没啥区别,具体参考官方样例。















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









