







1. 协同过滤(CF)
协同过滤分基于用户和基于物品的协同过滤,不管哪种方式,计算步骤如下:
I. 收集用户偏好
II. 找到相似的用户或物品
III. 计算推荐
所谓的用户偏好就是:用户与物品之间的联系,如评分、投票、转发、保存书签、标记标签等用户行为。
所谓的相似用户(或物品)就是:计算向量间的相似度。举例如下:
有用户ABCDE,以及他们对商品1和商品2的打分,建立笛卡尔坐标系,横轴是用户对商品1的评分,纵轴是用户对商品2的评分,那么用户A和用户E的相似度就是AE的欧氏距离。
对于相似度,我们有多种计算方式:欧氏距离,皮尔逊相关系数,COS相似度等,目前应用比较广泛的是皮尔逊相关系数。计算公式如下:
I. 欧几里得距离公式
II. 皮尔逊相关系数(协方差除以标准差)

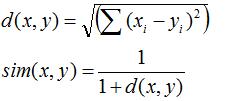
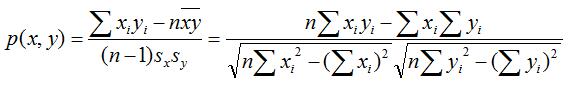
III. COS相似度
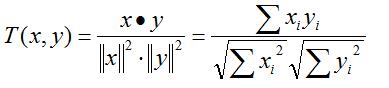
相似度计算好后,选择相似的用户或物品的方式有两种:一是选择固定前几位,二是选择一个阈值,该阈值范围内的都是近邻
协同过滤到此可分别分析基于用户和基于物品的协同过滤。
1.1. 基于用户的协同过滤
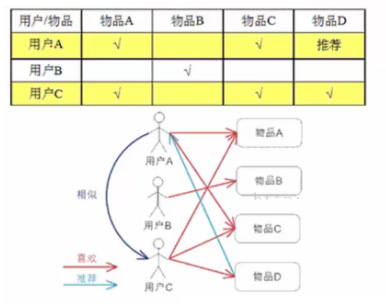
核心思想:计算用户之间的相似度,比如上面A和C的相似度高,那么把C喜欢的物品D推荐给A。这里计算相似度时,可以将用户对物品的喜好映射成向量再计算相似度,比如用户A的向量是[1 0 1 0],用户B的向量是[0 1 0 0]
这种模型的问题:
I. 基于用户的协同过滤会产生一张很大的稀疏矩阵(比如淘宝用户几亿,商品千千万万,每人喜好就那几样,比如我买过一样调料品,我对应的向量是[000000...001000...0000],只有某列为1,其余全为0)
II. 我们计算相似度需要两两计算,如果有5亿用户就得计算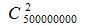
III. 对于新用户,无法得到可用向量
IV. 如果一个物品卖得好,但是相邻用户没有打分,这个物品就不会被推荐,则进入恶性循环。
针对这些问题的相关建议:
I. 相似度计算用皮尔逊相关系数
II. 用户相似度上再乘以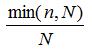
III. 对数据进行归一化,消除数据本身的影响
IV. 设置阈值,阈值范围内的就是近邻。
1.2. 基于物品的协同过滤
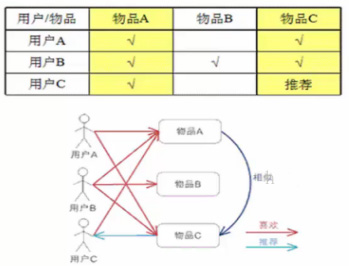
核心思想:计算物品之间的相似度,比如上图A与C相似度高,那么把物品C推荐给喜欢物品A的用户C。这里计算相似度,把用户对商品的喜好映射成向量,比如物品A的向量是[1 1 1],物品B的向量是[0 1 0]。
这种模式的优势:
I. 通常情况下物品数量远远小于用户数量,这样基于物品的向量计算量会小些
II. 可以预想计算相似度,物品是不会变的,人的喜好是会变的
1.3. 冷启动问题
不管是基于用户的协同过滤还是基于物品的协同过滤,都会遇到冷启动问题:
基于用户冷启动问题:
I. 引导用户把自己的属性表达出来(不如第一次进入会问你感兴趣的领域)
II. 利用现有的开放数据平台获取用户属性
III. 利用注册信息(不是很好)
IV. 推荐排行榜单,大众从众心理,再慢慢收集用户喜好
基于物品冷启动问题:
I. 文本分析
II. 主题建模
III. 打标签
IV. 推荐排行榜单
前三种是根据物品的描述
两种协同过滤的比较:
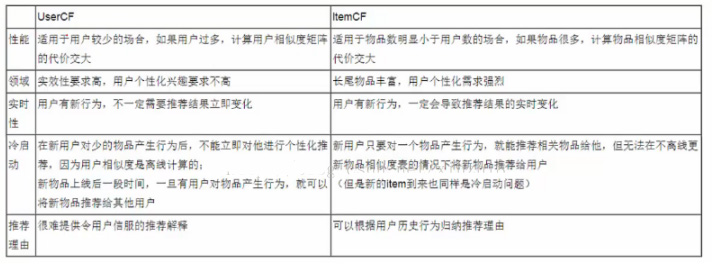
应用场景,基于用户的协同过滤:时事新闻,突发情况;基于物品的协同过滤:电子商务,电影等。
2. 隐语义模型(LFM)
协同过滤是基于统计学,这种模型可以很好地解释,但隐语义模型中包含两个隐含因子,类似于神经网络的隐藏层,根本不好解释隐含因子与最终结果有什么直观联系,但这并不妨碍我们去做这个模型。我们只需要根据现有的数据去训练出合适的隐含因子,使得目标函数最优化,那么模型就是可用的。
LFM在各项指标性能上均优于UserCF和ItemCF。但当数据集非常稀疏时,LFM的性能明显下降。甚至不如UserCF和ItemCF。
2.1. 对隐含语义模型的理解
我有N个用户对M个电影的评分数据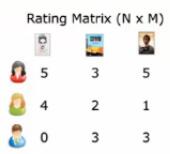
首先,我要对这个N*M矩阵进行分解,得出用户与隐含因子的关系(F*N矩阵),电影与隐含因子的关系(F*M矩阵),当然事先你可以随便设置这两个矩阵。然后与最终结果对比,即损失值,然后反向传播更新隐含因子,使得隐含因子下的目标函数损失最小。这个过程类似BP神经网络。
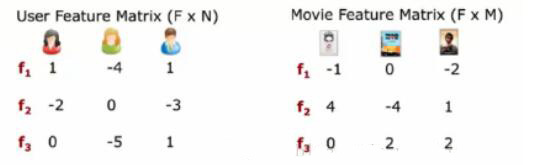
得到最优的F*N,F*M矩阵,再计算F*N的转置矩阵乘以F*M,还原为N*M矩阵,如下图
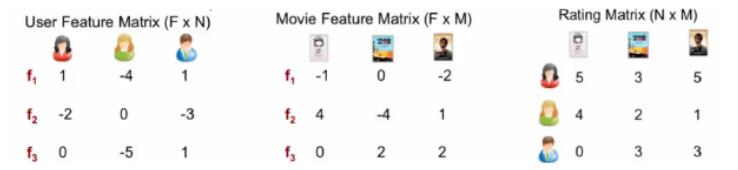
2.2. 目标函数
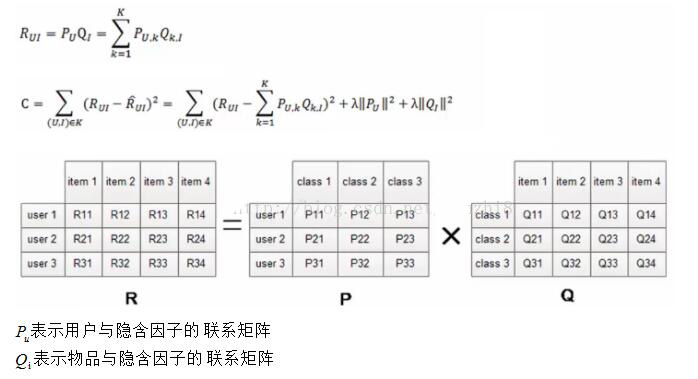
有了目标函数,对目标函数求偏导,就完成了

参数选择:
I. 特征个数F不要太大,类似神经网络中的神经元个数
II. 学习率不好太大
III. 正则项参数不要太大
IV. 负样本/正样本比例确定好,根据准确率、召回率、覆盖率确定。

















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









