







目录
支持向量机简介
支持向量机是线性分类器,是一种学霸方法,能最大限度分开两个类,即不仅做得对,还要保证质量

如何保证分类的正确性最大呢?


这是一个分类器求解的优化问题。
因为是线性分类器,线性不可分情况不好办。可以将当前数据引入更高维度中,运用线性超平面求解。超平面是分类的决策边界,比数据集低一维。

支持向量就是指离分隔超平面最近的那些点。
寻找最大间隔
那么,如何找到最佳决策分界面呢?以wx+b=0表示决策分界面,最大化间隔的目标就是找出分类器定义中的w和b。为此,我们必须找到具有最小间隔的数据点,而这些数据点也就是前面提到的支持向量。一旦找到具有最小间隔的数据点,我们就需要对该间隔最大化。
这是最值优化问题要求解的公式:

直接求解上述问题相当困难,所以我们根据拉格朗日乘子法将它转换成为另一种更容易求解的形式。具体演算流程参考:
支持向量机(SVM)——原理篇 - 知乎 (zhihu.com)

约束条件为:
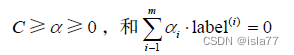
其中常数C用于控制 “最大化间隔” 和 “保证大部分点的函数间隔小于1.0” 这两个目标的权重。在优化算法的实现代码中,常数C是一个参数,因此可以通过调节该参数得到不同的结果。一旦求出了所有的alpha,那么分隔超平面就可以通过这些alpha来表达。SVM的主要工作就是求解alpha。
因此,支持向量机方法的优缺点:
优点:强分类器,能保证最大化区分两个类别,所以模型性能优异;泛化错误率低,计算开销不大,结果易解释。
缺点:对参数调节和核函数的选择敏感,不能处理不同类别相互交融的情况,只能大致上保持正确。
适用数据类型:数值型和标称型
一般过程:
1.收集数据
2.准备数据:数值型
3.分析数据:有助于可视化分隔超平面
4.训练算法:大部分时间用于训练,主要实现两个参数的调优
5.测试算法:十分简单的计算过程
6.使用算法:几乎所有的分类问题都可以使用SVM,SVM本身是一个二类分类器,对多类问题需要做一些代码上的调整。
序列最小优化算法SMO
SMO算法的工作原理:每次循环中选择两个alpha进行优化,一旦找到一对合适的alpha,那么就增大一个同时减小另一个,这里所谓的合适是指两个alpha要符合一定的条件,条件之一是个alpha必须在间隔边界之外;第二个条件是这两个alpha还没有进行过区间化处理或者不在边界上。
简化版SMO算法:首先在数据集上遍历每一个alpha,然后再随机选择另一个,从而构成alpha对。完整版SMO算法则是同时确定要优化的最佳alpha对。同时改变两个alpha至关重要,因为我们的约束条件:

改变一个alpha可能导致该条件失效,因此同时改变两个alpha。
辅助函数
import numpy as np
def loadDataSet(fileName):
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]),float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
def selectJrand(i,m): #i是第一个alpha的下标,m是所有alpha的数目,输出一个不等于i的j
j=i
while(j==i):
j=int(np.random.uniform(0,m))
return j
def clipAlpha(aj,H,L): #调整aj范围,介于最大值H和最小值L之间
if aj>H:
aj=H
if L>aj:
aj=L
return aj简化版SMO算法:
def smoSimple(dataMatIn,classLabels,C,toler,maxIter): #数据集,类别标签,常数C,容错率,退出前最大循环次数
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
b=0
m,n = np.shape(dataMatrix)
alphas = np.mat(np.zeros((m,1)))#初始化alpha参数,设为0
iter = 0 #储存在没有任何alpha改变的情况下遍历数据集的次数
while (iter<maxIter): #外循环:最大循环次数之内
alphaPairsChanged = 0 #记录alpha是否已经进行优化
for i in range(m):#内循环:对数据集中每个数据向量
fxi = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T))+b #wx+b,是预测的类别
Ei = fxi-float(labelMat[i]) #误差Ei
if((labelMat[i]*Ei<-toler) and (alphas[i]<C)) or ((labelMat[i]*Ei>toler) and (alphas[i]>0)):
j = selectJrand(i,m) #随机选择另一个alpha
fxj = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T))+b
E 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1668
1668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









