







台风的历史最佳路径数据集可以从中国气象局热带气旋资料中心下载,但是每年3/4月份左右才会发布上一年的数据,如果需要使用当年的数据,可以爬取中央气象台台风网(http://typhoon.nmc.cn/web.html)的数据。同时,在日常业务工作中,可能需要获取中央气象台的台风预报数据,进行一些其他处理。本篇介绍如何爬取中央气象台台风网的正在发展的台风数据,包括台风的历史实况分析和预报数据,以2021年的“查帕卡”和“烟花”为例。
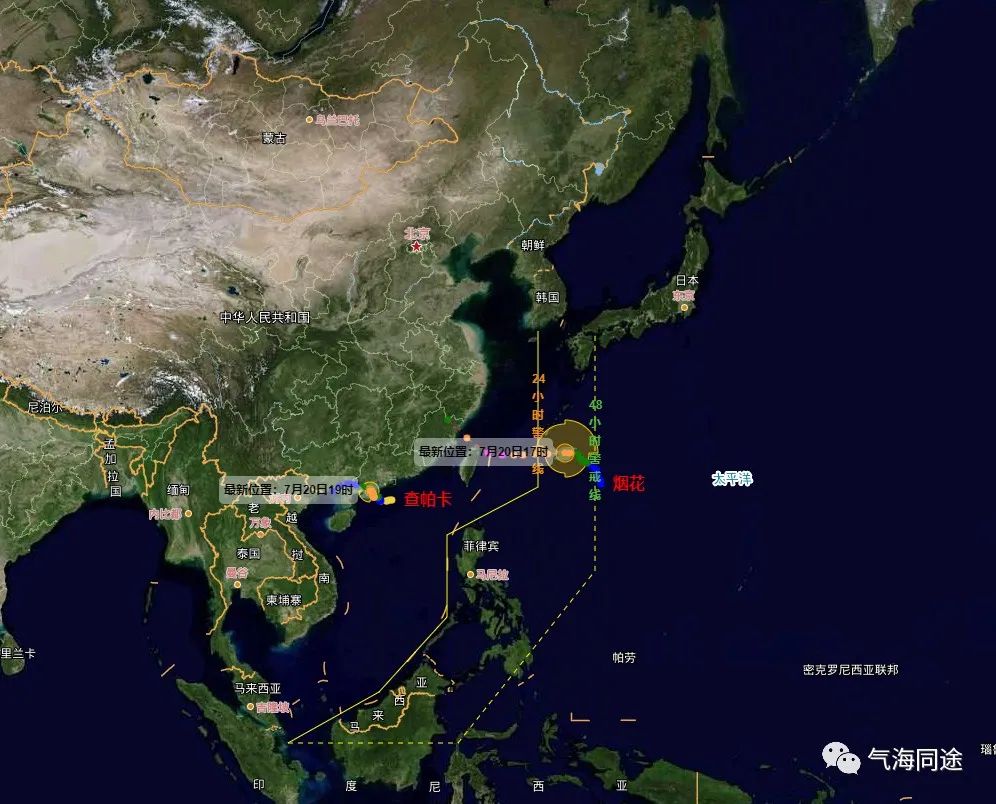
中央气象台台风网,图中为2106烟花和2107查帕克的信息(2021年7月20日20点)
一 确认当前正在发展的台风
使用Chrome浏览器开发者工具解析当前网页的元素。首先根据当前默认列表(默认当年的台风列表)的URL,爬取得到我们需要的台风id,台风名和编号以及是否是当前正在发展的台风。
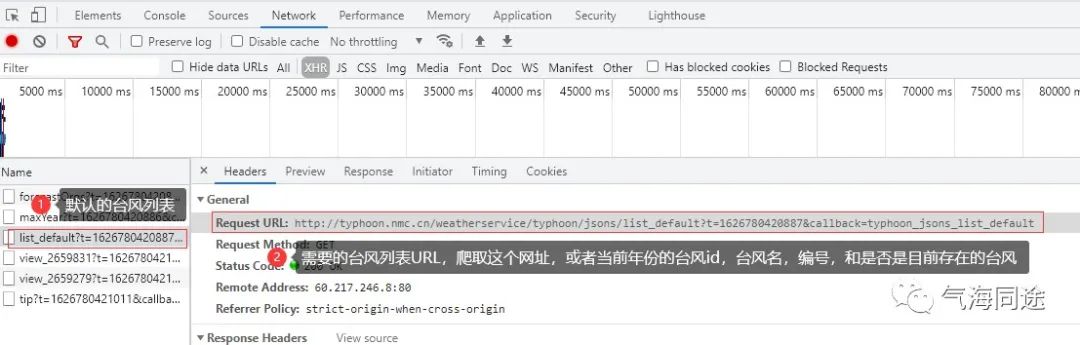
代码说明:
# 获取目前存在的西北太平洋台风,包括未编号但是给出路径预报的
def get_current_tc_list(url):
html_obj = requests.get(url, headers=headers, verify=False).text
data = json.loads(re.match(".*?({.*}).*", html_obj, re.S).group(1))['typhoonList']
item_list = []
for v in data:
state = v[7] # stop or start
if state == "start": # 只保留当前台风
item = {}
item['id'] = v[0]
item['tc_num'] = '%s' % v[4] # 编号
item['name_cn'] = '%s' % v[2] # 中文名
item['name_en'] = '%s' % v[1] # 英文名
item['dec'] = '%s' % v[6] # 名字含义
item_list.append(item)
return item_list
t = int(round(time.time() * 1000)) # 13位时间戳
url = 'http://typhoon.nmc.cn/weatherservice/typhoon/jsons/list_default?t=%s&callback=typhoon_jsons_list_default'%t
item_list = get_current_tc_list(url)二 爬取目标台风的历史实况和预报信息
根据上个步骤得到的台风id等信息,爬取目标台风的URL,然后解析得到台风的历史位置和强度等信息和未来的预报信息。
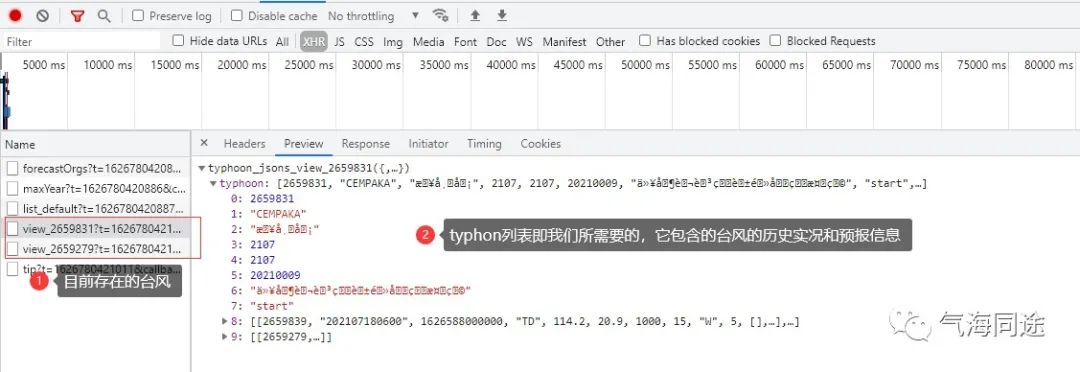
代码说明
#获取目标台风
def get_tc_info(item):
#根据获取的时间戳和台风id,确定要请求的URL,得到typhoon列表
t = int(round(time.time() * 1000)) # 13位时间戳
# callback: typhoon_jsons_view_ + 台风的id
url = 'http://typhoon.nmc.cn/weatherservice/typhoon/jsons/view_%s?t=%s&callback=typhoon_jsons_view_%s' % (item['id'], t, item['id'])
html_obj = requests.get(url, headers=headers, verify=False).text
data = json.loads(re.match(".*?({.*}).*", html_obj, re.S).group(1))['typhoon']
# 建立字典保存信息
info_dicts = { 'tc_num':item['tc_num'], #编号
'name_cn':item['name_cn'], #中文名
'name_en':item['name_en'], #英文名
'dateUTC':[], #日期 UTC
'dateCST':[], #日期 CST
'vmax':[], #最大风速 m/s
'grade':[], #等级
'latTC':[], #位置deg
'lonTC':[],
'mslp':[], #中心气压hPa
'attr':[]} #属性,预报forecast,实况analysis
#先遍历所有实况
for v in data[8]:
info_dicts['dateUTC'].append(v[1])
info_dicts['dateCST'].append(date_pred(v[1], 8)) # UTC to CST
info_dicts['vmax'].append(v[7])
info_dicts['grade'].append(get_type(v[3]))
info_dicts['lonTC'].append(v[4])
info_dicts['latTC'].append(v[5])
info_dicts['mslp'].append(v[6])
info_dicts['attr'].append('analysis')
#最新预报时刻
dateUTC0 = info_dicts['dateUTC'][-1]
#获取最新的一次预报
BABJ_list = data[8][-1][11]['BABJ']
for i in range(len(BABJ_list)):
pred_hour = int(BABJ_list[i][0]) #预报时效,hour
dateUTC_pred = date_pred(dateUTC0, pred_hour)
info_dicts['dateUTC'].append(dateUTC_pred)
info_dicts['dateCST'].append(date_pred(dateUTC_pred, 8))
info_dicts['vmax'].append(BABJ_list[i][5])
info_dicts['grade'].append(get_type(BABJ_list[i][7]))
info_dicts['lonTC'].append(BABJ_list[i][2])
info_dicts['latTC'].append(BABJ_list[i][3])
info_dicts['mslp'].append(BABJ_list[i][4])
info_dicts['attr'].append('forecast')
tc_info = pd.DataFrame(info_dicts)
return tc_info三 获取到的台风信息
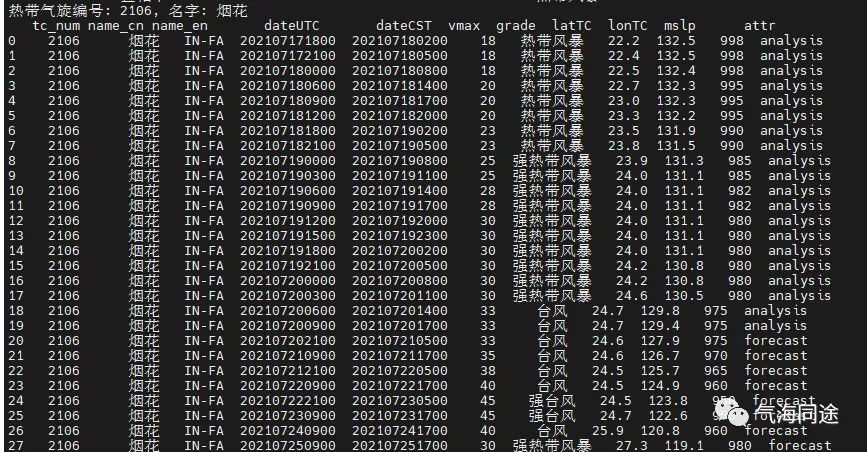
2021-07-020:20左右爬取到的台风信息如下,以烟花为例,analysis表示历史实况分析,forecast表示预报数据。
扫描下方二维码关注气海同途公号,回复“台风路径”关键字即可获取。


















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









