






文目录
- 深度学习基础
- ChatGPT的本质
- ChatGPT原理详解
一、深度学习基础
— 深度学习是什么?如何理解神经网络结构?
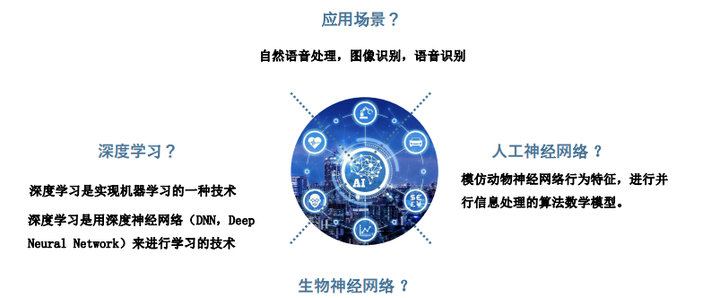
关于生物神经网络结构如下:

神经网络介绍
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络 (NN), 是一种模仿生物 神经网络结构和功能的计算模型。
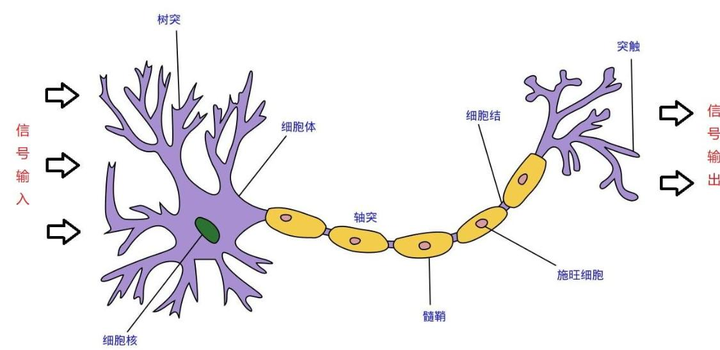
当电信号通过树突进入到核细胞时,会逐渐聚集电荷。达到一定的电位后,细胞会被激活,通过轴突发出信号。
从大脑的神经元抽象得到的模型的数学表示:

第一个感知机模型
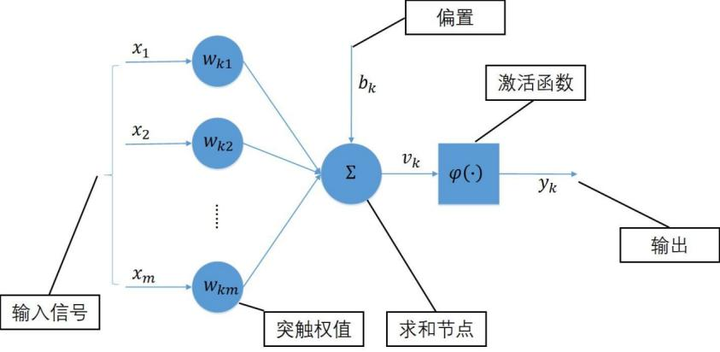
如果学习参数w

通过误差反向传播更新参数。
神经网络发展经历

神经网络中信息只想一个方向移动,即从输入节点向前移动,通过隐藏节点,再向输出节点移动。其中基本部分是:

1. 输入层: 即输入 x 的那一层
2. 输出层: 即输出 y 的那一层
3. 输入层和输出层之间都是隐藏层
1.确定神经网络层数
(1)输入层和输出层仅有一层,隐层有多层
2.确定每层单元的个数
(1)输入层单元个数根据输入数据个数定
(2)输出层单元个数根据目标分类个数确定
(3)隐层的单元个数如何确定?
• 神经网络介绍
=>隐层个数设定没有明确规则,根据准确度来进行判断和改进。
ChatGPT是在GPT基础上进一步开发的NLP模型
Generative Pre-trained Transformer( 生成式训练模型)
ChatGPT是基于GPT-3的优化实现版本
二、ChatGPT本质
2022年11月30日,OpenAI的CEO,Altman在推特上写道:“今天我们推出了ChatGPT,尝试在这里与它交谈”, 然后是一个链接(https://chat.openai.com/auth/login),任何人都可以注册一个帐户, 开始免费与 OpenAI的新聊天机器人ChatGPT交谈。

ChatGPT是由OpenAI开发的一种大型预训练语言模型, 其和人类沟通的方式为人机对话形式
这个时候,我们可以思考两个问题。机器如何判断一条输入句子的合理性?机器的回复是否是人类可以理解的或者是人类习惯在日常生活中习惯表达的。
什么是语言模型?
通俗理解:判断一个句子序列是否是正常语句, 即是否是人话.
标准定义:对于某个句子序列, 如{W1, W2, W3, …, Wn}, 语言模型就是计算该序列发生的概率, 即P(W1, W2, …, Wn). 如果给定的词序列符合语用习惯, 则给出高概率, 否则给出低概率


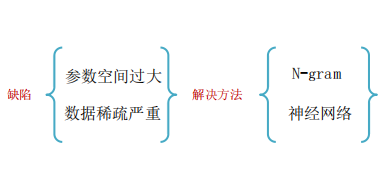
N-gram语言模型
为了解决上述问题, 引入马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关
如果一个词的出现与它周围的词是独立的, 那么我们就称之为unigram(一元语言模型).

如果一个词的出现仅依赖于它前面出现的一个词, 那么我们就称之为bigram(二元语言模型).
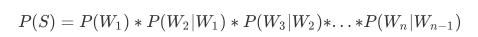
如果一个词的出现仅依赖于它前面出现的两个词, 那么我们就称之为trigram(三元语言模型)

一般来说, N元模型就是假设当前词的出现概率只与它前面的N-1个词有关, 而这些概率参数都是可以通过大规模语料库来计算的。
在实践中用的最多的就是bigram和trigram
bigram语言模型
举例说明:
首先我们准备一个语料库(简单理解让模型学习的数据集),为了计算对应的二元模型的参数, 即
P(Wi|Wi-1),我们要先计数即C(Wi-1, Wi),然后计数 C(Wi-1),再用除法可得到概率.
为了方便理解,了解P(A|B) 公式如下:

举例说明:
首先我们准备一个语料库(简单理解让模型学习的数据集),为了计算对应的二元模型的参数, 即
P(Wi|Wi-1),我们要先计数即C(Wi-1, Wi),然后计数 C(Wi-1),再用除法可得到概率.
C(Wi-1,Wi) 计数结果如下


C(Wi-1)的计数结果如下:

那么bigram语言模型针对上述语料的参数计算结果如何实现?假如,我想计算P(想|我)=0.38, 计算过程如 下显示: (其他参数计算过程类似)


如果针对这个语料库的二元模型(bigram)建立好之后, 就可以实现我们的目标计算:

C(Wi-1)的计数结果如下:

那么bigram语言模型针对上述语料的参数计算结果如何实现?假如,我想计算P(想|我)=0.38, 计算过程如 下显示:(其他参数计算过程类似)

如果预测:我想去打乒乓球?引入拉普拉斯变化。
神经网络语言模型

ChatGPT的本质

GPT-1(1.17亿参数)
GPT-1有一定泛化能力,能够用于和监督任务无关的 NLP 任务中
GPT-2(15亿参数)
除了理解能力外,GPT-2在生成方面表现 。非常好:阅读,摘要,聊天,编故事;
GPT-3(1750亿参数)
GPT-3实现将网页转化为相应代码、模仿人 。类叙事、创作定制诗歌、生成游戏剧本。InstructGPT是一个经过微调的GPT-3,实 现更好的输出将人类的反馈纳入训练过程,更好地使模 型输出与用户意图保持一致
三、ChatGPT原理详解
GPT-3原理初探
目前基于ChatGPT的论文并没有公布, 因此接下来我们基于openai官网的介绍对其原理进行解析

目前基于ChatGPT的论文并没有公布, 因此接下来我们基于openai官网的介绍对其原理进行解析

原始的GPT-3就是非一致模型, 类似GPT-3的大型语言模型都是基于来自互联网的大量文本数据进行训练, 能够生成类似人类的文本, 但它们可能并不总是产生符合人类期望的输出.

ChatGPT为了解决模型的不一致问题, 使用了人类反馈来指导学习过程, 对其进行了进一步训练. 所使用的具体技术就是强化学习(RLHF). ChatGPT是第一个将此技术用于实际场景的模型
强化学习(RL)
- 强化学习又称再励学习、评价学习或增强学习。
- 是机器学习的一个重要分支,主要用来解决连续决策的问题。
- 围棋可以归纳为一个强化学习问题,需要学习在各种局势下如何走出最好的招法。
- 用于描述和解决智能体(Agent)在与环境的交互过程中, 通过学习策略以达成回报最大化或实现特定目标的问题。
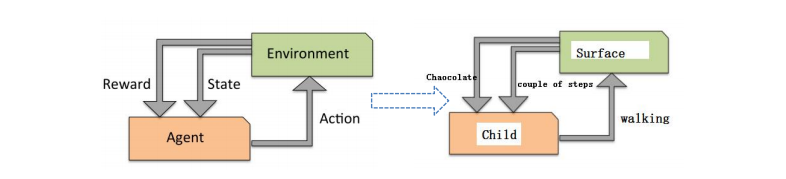
理解强化学习基本要素

如何让AI实现自动打游戏

强化学习和模型的关系
一个游戏里记录每一步的状态和行动:T={s1, a1, s2, a2, s3, a3, ..., st, at}

ChatGPT强化学习步骤



















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









