









CNN
convolutional neural network,不了解的可以学习https://arxiv.org/pdf/1901.06032.pdf,非常全面。
这里只是CNN的二次抽象,可以认为是这个话题的再次“全连接”层。
核心步骤则是:卷积、池化
对于分类问题,主要的流程:
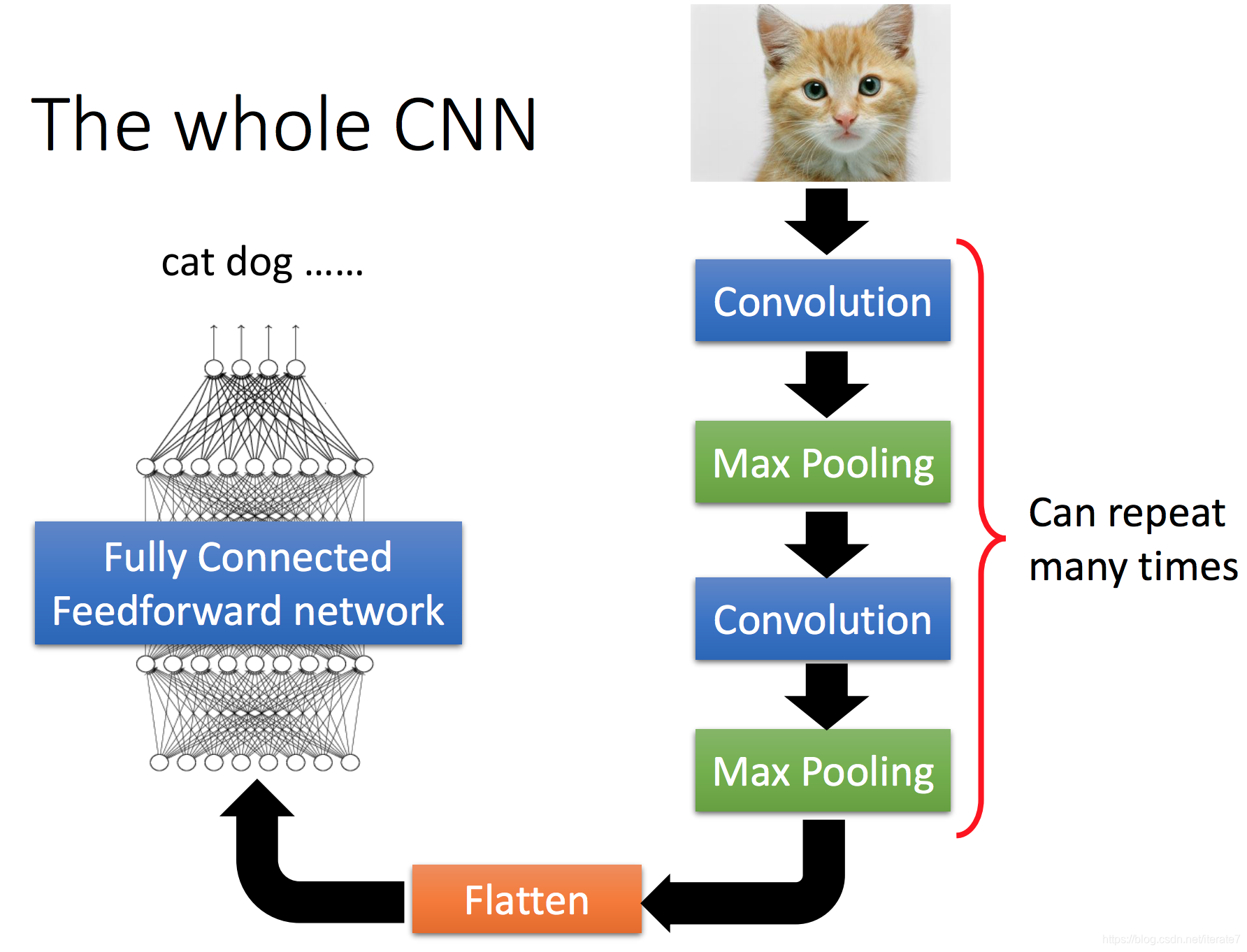
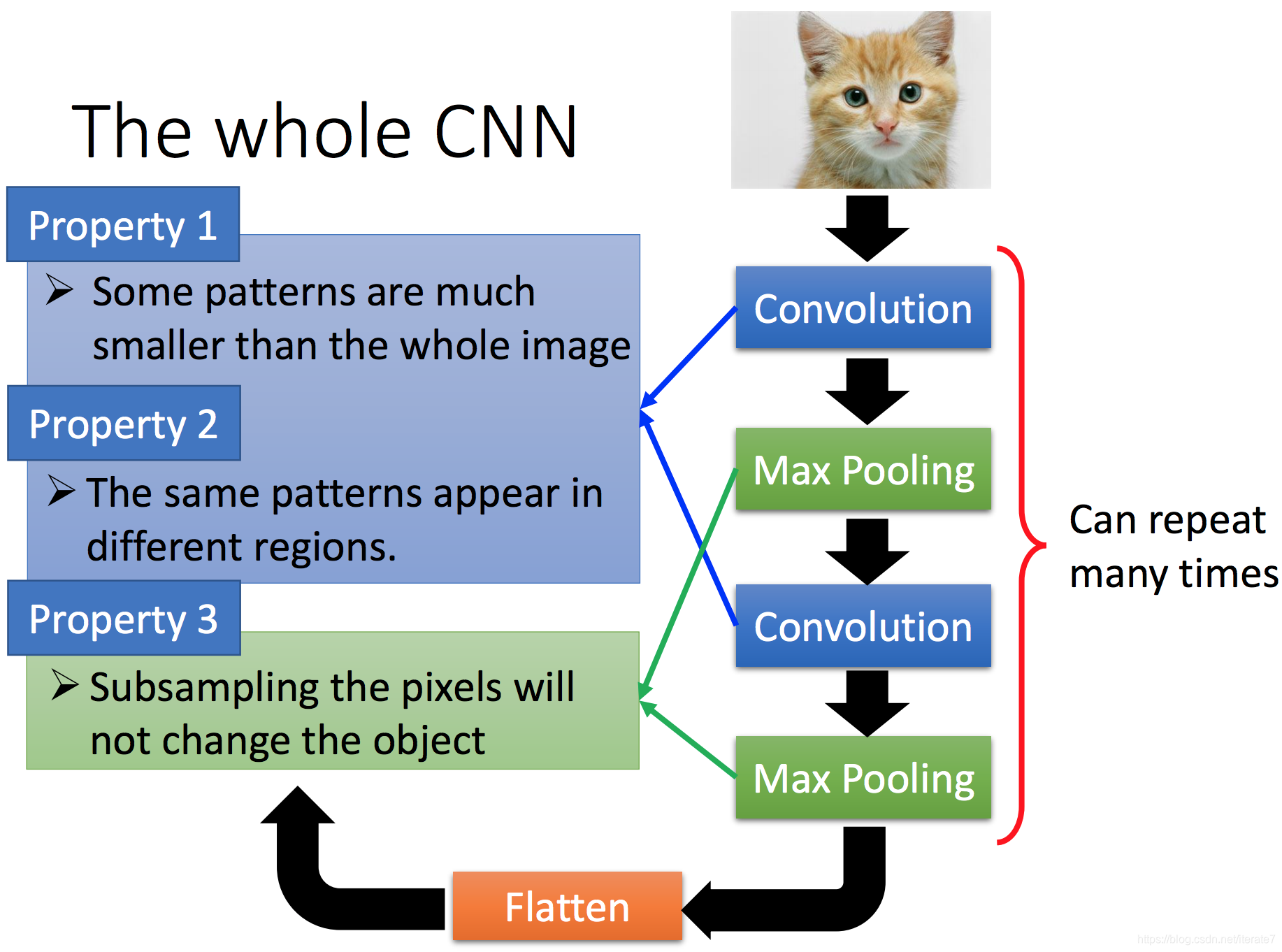
至于卷积和池化则在后面代码介绍,一句话理解:
卷积就是抽取某些特征。filter就是卷积核,抽取某类特征,如果想抽取不同的特征,则就是多个filter,抽取之后形成feature map。
我们要学习什么参数呢?
filter.
比如我们有3个filter,每个filter是3*3的matrix,那么要学习的参数就是3个matrix对应的weight。
为什么要cnn呢?不用fully connected?
本质上是可以fully connnect的,如果计算足够牛逼。其实主要是减少参数训练,并且可以根据task设计更优秀的框架一样可以做到同样的performance。
核心是:卷积的特征抽取能力和参数共享。
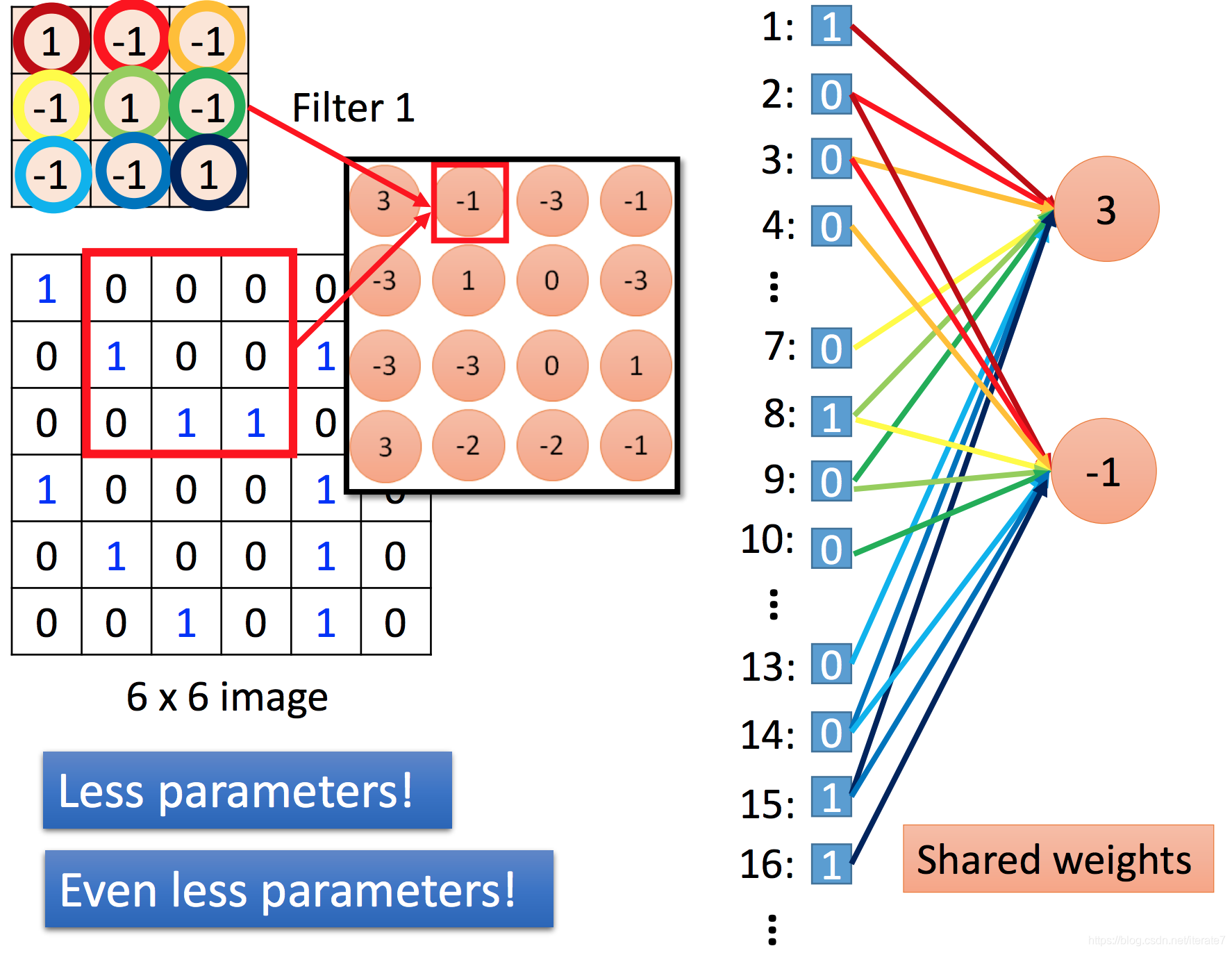
比如利用33的filter1进行特征抽取的时候。如果把66的image弄成一列,那么全连接形成3节点和-1节点,其实我们利用的filter1是一样的,那就是weight一样。这个就叫:shared weights。
最终的还有另外一个:不是所有的节点都参与计算到下一个节点,到底选择那些节点呢? 这就是kernel大小的点,上图中的红色框里的东西。 最新的kernel计算有了一个新的kernel叫做dilated kernel,叫空洞卷积。
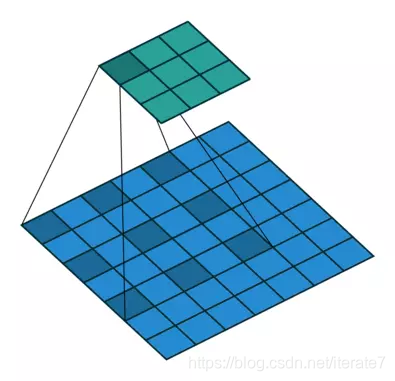
空洞卷积,其实可以扩大感受野,捕获更多的信息。
代码实战
#!/usr/bin/env python
# coding: utf-8
# ## 引入时间和导入数据
# - **pip install ipython-autotime**
# - **提前下载**
# sudo wget https://s3.amazonaws.com/img-datasets/mnist.npz*
# In[11]:
get_ipython().run_line_magic('load_ext', 'autotime')
from keras.datasets import mnist
# In[34]:
(X_train, y_train),(X_test,y_test) = mnist.load_data(path='mnist.npz')
# In[35]:
#numpy.ndarray
print(X_train.shape)
X_test.shape
# ## 展示图片、向量
# - 图片尺寸 28*28
# - 图片展示plt.imshow
#
# <hline>
#
# In[36]:
import matplotlib.pyplot as plt
plt.imshow(X_test[0])
plt.imshow(X_train[0])
plt.show()
print(X_train[0].shape)
print(X_train[0])#rgb
# In[37]:
#reshape to fit model
X_train = X_train.reshape(60000,28,28,1) # last is grey
X_test = X_test.reshape(10000,28,28,1)
X_train[0]
# In[38]:
from keras.utils import to_categorical
#one-hot, y向量化
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
y_train[0]
# In[39]:
from keras.models import Sequential
from keras.layers import Dense,Conv2D,Flatten
model = Sequential()
# 3*3 filter_size; 64: filter number
model.add(Conv2D(64,kernel_size=3,activation='relu', input_shape=(28,28,1)))
model.add(Conv2D(32,kernel_size=3,activation='relu'))
model.add(Flatten())
model.add(Dense(10,activation='softmax'))
# In[41]:
model.compile(optimizer='adam',
loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, validation_data=(X_test,y_test),epochs=3)
# In[48]:
## 随机预测一副图片
ret = model.predict(X_test[0:1])
ret
# In[49]:
plt.imshow(X_test[0].reshape(28,28))
plt.show()
# In[ ]:
文本处理
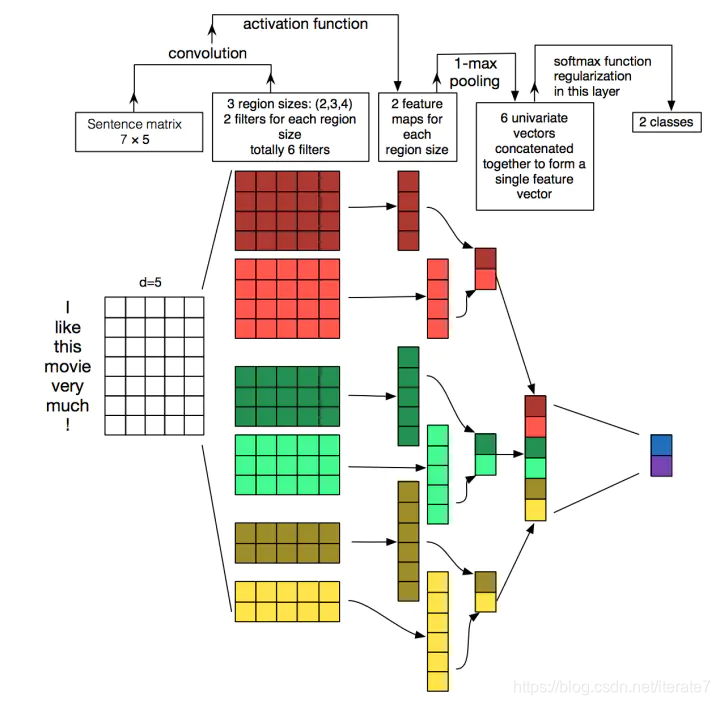
总结
- 特点一稀疏交互(sparse interactions);也就是用小窗口卷积核
- 参数共享,卷积核的参数是一样的
- 等变表示;其实就是平移和卷积操作对结果是无影响的。
参考文献
Multi-scale context aggregation with dilated convolutions
https://arxiv.org/pdf/1901.06032.pdf
http://cs231n.github.io/convolutional-networks/
https://www.bilibili.com/video/av44989461/?spm_id_from=trigger_reload
https://arxiv.org/pdf/1510.03820.pdf














 2804
2804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









