






文章目录
0 简介
今天学长向大家分享一个毕业设计项目
基于深度学习的图像修复算法 DCGAN
🧿 项目分享:见文末!
1 图像修复
图像修复是指利用复杂的算法重建图形中丢失或损坏的部分的过程。在现实生活中,这项工作仍然由经验丰富的图像修复师来完成。图像修复技术主要用来修复日常生活中被噪声污染或者人为破坏的破损图像,其次也可应用于替换图像中的小区域或者瑕疵。所以让图像修复借助深度学习的算法和框架自动化是一个值得深入研究的课题。
在原来的图像生成模型相应的增加一个图像修复代价优化器即可完成图像修复模型的构建。在训练时,应该在进行图像修复之前应该先迭代训练图像生成模型,找寻到能生成假图片的权重矩阵,再利用该权重矩阵进行图像修复模型迭代优化,具体来说是先完成图像生成迭代,然后停止图像生成优化,对图像生成的输入噪声迭代优化,找到与修复图相同的输入分布之后生成最佳假图片,提取假图片投影进行拼接即完成图像修复,下图展示这种图像修复模型的运行过程
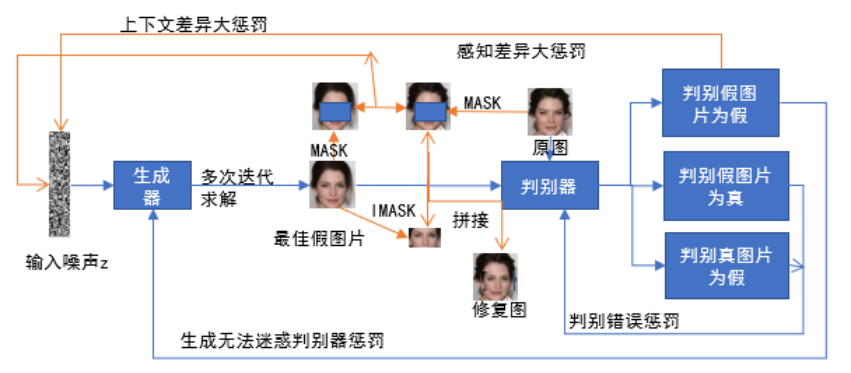
2 生成对抗网络与图像修复
2.1 生成对抗网络简介
生成对抗网络其实两个网络互相博弈,最终达到纳什均衡。这两个网络一个是生成器网络,它的目标接受随机噪声,不断训练生成假图片,为了方便叙述把生成假图片的函数记作G(z)。另一个网络是判别器网络,该网络负责判断输入的图片是由G(z)生成的假图片还是原图,如果是原图的会输出1,如果是假图片输出0.这两个网络的博弈过程具体说就是生成器网络输入随机噪声后不断生成足够接近真实图片的假图片去欺骗判别器网络,而判别器网络就是要把生成器网络生成的假图片判断出来,这样两者互相博弈,最终到达纳什均衡。图2.5是GAN网络的对抗生成原理图。
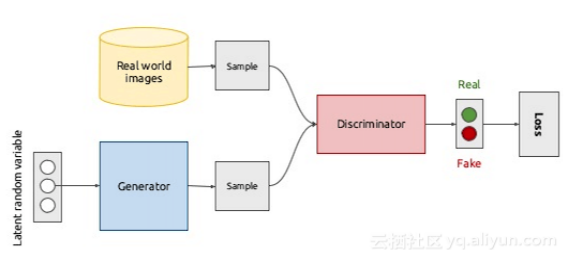
上图 GAN网络生成图片原理图 (输入随机噪声生成器生成的假图片以及真图片又作为判别器的输入,判别器判别错误惩罚判别器,判别正确惩罚生成器)
3 生成对抗网络在图像修复上的应用
把GAN网络应用于图像修复[9]时,首先不考虑的是使用破损的不完整图像进行修复,而是采用完整的原图进行GAN网络训练图像生成模型。首先随机输入一些噪声,使用GAN模型的生成器与判别器互相博弈,使生成器能有产生接近原图的假图片的能力。但是此时的模型还不足够生成最佳的假图片进行图像修复,因为该假图片的输入的概率分布不一定与待修复图片的概率分布一致,所以对假图片的输入噪声进行迭代更新,直到训练后输入的概率分布与待修复图片一致,即可提取由生成器生成的假图片和破损原图一样大一样位置的破损块,利用破损块与待修复图做简单的通道拼接之后即可完成图像修复工作。图2.6即为使用GAN网络进行图像修复的原理图。
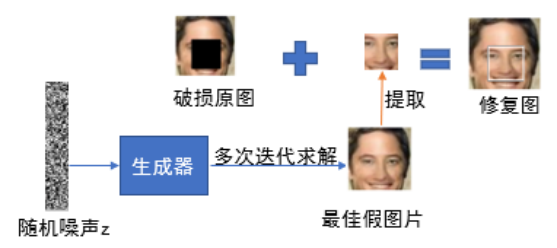
GAN网络进行图像修复的原理 (随机噪声经过生成器多次迭代后提取生成后假图片的部分填充到待修复图)
4 深度卷积对抗网络与图像修复
4.1 深度卷积对抗网络简介
DCGAN网络简单来理解就是把GAN网络框架的生成器和判别器用卷积神经网络实现。但是在进行实验时,为了提高训练收敛的速度,DCGAN对卷积网络的结构进行了一些修正,这些修正如下:
- (1) 取消卷积后的池化层,在判别器网络中取消的池化层改用卷积层,在生成器网络中取消的池化层改用转置卷积层。
- (2) 对判别器网络训练时除了输出层外都采用relu函数进行激活。输出层为保证输出为两个输出,采用sigmoid函数。
- (3) 对生成器网络训练时除了输出层外都采用修正的ReLU函数LeakyReLU函数进行激活。输出层为保证输出在-1到1之间,采用tanh激活。
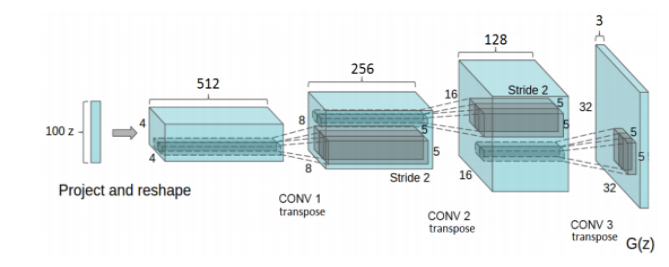
上图为DCGAN网络的生成器。
图2.7 DCGAN网络的生成器 (100维噪声经过三层转置卷积层图像
由窄深变为宽浅)
- (4) 卷积后每一层在激活前都使用batch_normalization归一化,避免参数过大,出现过拟合现象。
- (5) 取消密集(dense)层。
4.2 深度卷积对抗网络与图像修复
DCGAN网络实际是GAN网络的升级,所以使用DCGAN网络进行图像修复的原理与GAN网络相似。总的来说就是训练生成器具备生成假图片的能力,然后不断调整输入,使之能找到最佳假图片。关于原理细节和实验细节将在第三,四章详细介绍。
5 算法实现
5.1 数据集
Celeba数据集最初是由The Chinese University of Hong Kong的MMLAB收集的用来训练的人脸图片集,该人脸图片集包含202,599张各种名人的脸部图像,并对人脸的5个标志:眼睛的左边与右边,鼻子,嘴巴的左边与右边进行标记,本文采用的数据文件img_align_celeba.zip为所有脸部图像进行了裁剪和对齐的数据集文件。

5.2 基于人脸图片数据集的图像生成模型的构建
下面按照本章描写的步骤对Celeba图片进行图像生成模型的构建。本部分将会详细介绍模型的形成。
(1)Celeba图片数据的处理
①使用scipy的库函数对Celeba图片集进行裁剪[shape=64643]。
②首先从数据集中提取样本集。
③对数据集进行处理。
对数据具体的数据处理步骤和方法如下。

图像生成代价函数与优化器的构建
判别器代价函数 方法 因为判别器想要输入真图片输出1,想要输入假图片输出0,所以需要两个代价函数,一个利用交叉熵函数判断输入真图片输出与1的差别,另一个利用交叉熵函数判断输入假图片输出与0的差别,但是为了防止判别效果太好,导致梯度消失,所以添加很小的参数smooth,输入真图片时判断真图片与1个略比1小的差别。当两个差别过大,就惩罚判别器,以此得到好的判别效果。
关键代码如下:
#真图片输出与略比1小的标签的差距
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=d_logits_real, labels=tf.ones_like(d_logits_real) * (1 - smooth)))
#假图片输出与标签0的差距
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=d_logits_fake, labels=tf.zeros_like(d_model_fake)))
#两个差距之和构成判别器代价函数
d_loss = d_loss_real + d_loss_fake
生成器代价函数 方法 因为生成器想要自己构造的假图片让判别器输出1,所以生成器的构造利用交叉熵函数判断判别器输入假图片输出与1的差别。
代码 #假图片输出与标签1的差距
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=
d_logits_fake, labels=tf.ones_like(d_model_fake))
判别器优化器 方法 输入学习率learning_rate,权重衰减参数beta1,使用Adam优化器
代码 #判别器优化器
discriminator_optimizer = tf.train.AdamOptimizer(learning_rate=
learning_rate, beta1=beta1)
生成器优化器 方法 输入学习率learning_rate,权重衰减参数beta1,使用Adam优化器
代码 #生成器优化器
generator_optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, beta1=beta1)
参数确定
此参数是经过不断优化实验所得。
参数 参数值
输入噪声维度(z_size) 100
学习率(learning_rate) 0.0002
权重衰减率(beta1) 0.5
增加对抗攻击(smooth) 0.1
LeakyReLU的斜率(alpha) 0.2
训练的batch的大小(batch_size) 128
卷积核大小(ksize) 5*5
卷积步长(stride) 2
训练次数(epoch) 10
5.3 实现效果
此次模型采用优化一次判别器,再优化一次生成器的方法进行图像生成,下图展示了图像生成的过程。(输入为100维随机噪声向量,经过迭代不断生成假图片的过程)

6 模型改进
虽然使用一次判别器迭代,一次生成器迭代达到图像生成的目的,但是通过观察图损失变化图(红线是生成器生成损失,蓝线是判别器判别损失),容易发现判别器判别损失有趋于0的现象,此种现象叫做梯度消失。
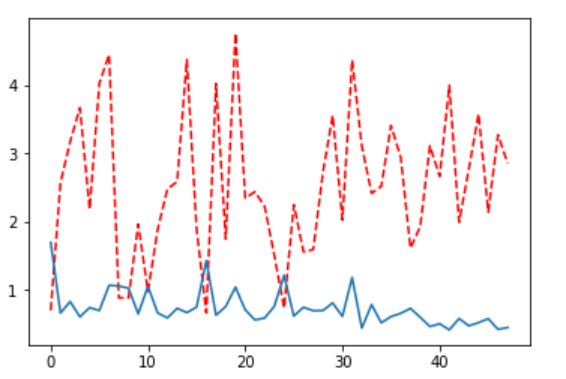
为了解决这种梯度消失现象,本文对图像生成模型进行了改进,在原有基础上增加了一次生成器损失,也就是优化后的模型变为一次判别器优化迭代,两次生成器迭代优化。图展示了优化后的损失变化图。很明显从图中能看出梯度消失得到了解决。
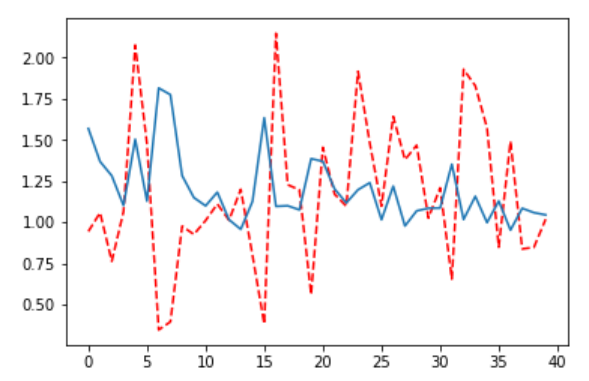
展示了进行优化后的图像生成过程,可以从图中看出图像生成的迭代效果也比之前有了提高

完整项目与论文获取:
https://gitee.com/sinonfin/algorithm-sharing
详细设计论文

5 最后
🧿 项目分享:见文末!















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









