







本文为 「茶桁的 AI 秘籍 - BI 篇 第 15 篇」

Hi,你好。我是茶桁。
上一节课咱们介绍了推荐系统中使用的矩阵分解的原理,讲到最终我们设定了模型目标。
有了机器学习去解这个目标,要用到一些优化的方法。常见的优化方法有两种,一个叫 ALS,交替最小二乘法。还有一个就是 SGD,随机梯度下降。
ALS 求解方法
我们来看看,ALS 是怎样一个原理。交替最小二乘法有点像我们拧螺丝的一个过程,就是固定一边求解另一边。
上一节课中我们有了 user 矩阵和 item 矩阵,12*3的 user 和3*9的 item 这两个矩阵都是未知,都是模型要去求的。一个方程有两个未知,R 是已知。
一个方程有两个未知能依次求解出来吗?如果 item 已经知道了,R 也知道了,把 user 求出来这个很有可能。但是如果 R 知道,user 和 item 都不确定的话一次是不能求解出来的。
那怎么办?我们就要固定一个求解另一个,这叫做交替最小二乘法。
- step1: 固定 Y 优化 X
- step2: 固定 X 优化 Y
重复 step1 和 2,每一次求解过程都是一个收敛的,去拟合参数的过程。
最小二乘法的应用
最小二乘实际上我们都不陌生,在中学期间做过一些物理实验,物理老师就会说我们的实验报告要多次求解。
举个场景,比如要测量一把尺子,这个尺子到底有多长咱们做了 5 次实验,分别是 9.8、9.9、9.8、10.2 和 10.3,那你在写实验报告结论的时候一般就是相加再除上 5,这个叫平均值。
最小乘法是由道尔顿提出来
E = ∑ i = 1 n e i 2 = ∑ i = 1 n ( y i − y ^ ) 2 \begin{align*} E = \sum_{i=1}^n e_i^2 = \sum_{i=1}^n(y_i - \hat y)^2 \end{align*} E=i=1∑nei2=i=1∑n(yi−y^)2
不采用中位数和几何平均数背后的原理就是因为要求一个导数为 0 的函数。对其进行求导之后,导数为 0 的时候为最小值,因此:
d d y ∑ i = 1 n ( y i − y ) 2 = 2 ∑ i = 1 n ( y i − y ) = 0 \begin{align*} \frac{d}{dy}\sum_{i=1}^n(y_i-y)^2 = 2\sum_{i=1}^n(y_i - y) = 0 \end{align*} dydi=1∑n(yi−y)2=2i=1∑n(yi−y)=0
那么继续往下计算就可以得到
( y 1 − y ) + ( y 2 − y ) + ( y 3 − y ) + ( y 4 − y ) + ( y 5 − y ) = 0 \begin{align*} (y_1 - y) + (y_2 - y) + (y_3 - y) + (y_4 - y) + (y_5 - y) = 0 \end{align*} (y1−y)+(y2−y)+(y3−y)+(y4−y)+(y5−y)=0
所以,当它最小拟合的过程中就是
y = 1 n ∑ i = 1 n y i \begin{align*} y = \frac{1}{n}\sum_{i=1}^n y_i \end{align*} y=n1i=1∑nyi
也就等于
y
1
+
y
2
+
y
3
+
y
4
+
y
5
5
\begin{align*} \frac{y_1+y_2+y_3+y_4+y_5}{5} \end{align*}
5y1+y2+y3+y4+y5
现在我们知道,物理上做实验,取多次结果最后求平均值其原理就是我们要去求一个导数为 0 的函数极值,也是因为我们的评价标准是最小二乘。
做了五次实验,得到五个数,就是 y1、y2 一直到 y5,是以这个例子为例。n 次实验其实应该是从 y1 一直到 yn。做物理实验做 n 次应该就是这 n 次的 n 分之一。
那现在也是一样的,用的一个叫做交替最小二乘,最小二乘是一种拟合技术,它可以让我们更好的去求这种参数估计。
最小二乘法在计算机产生之前已经变成了一个通用的数学工具,我们来看一下:
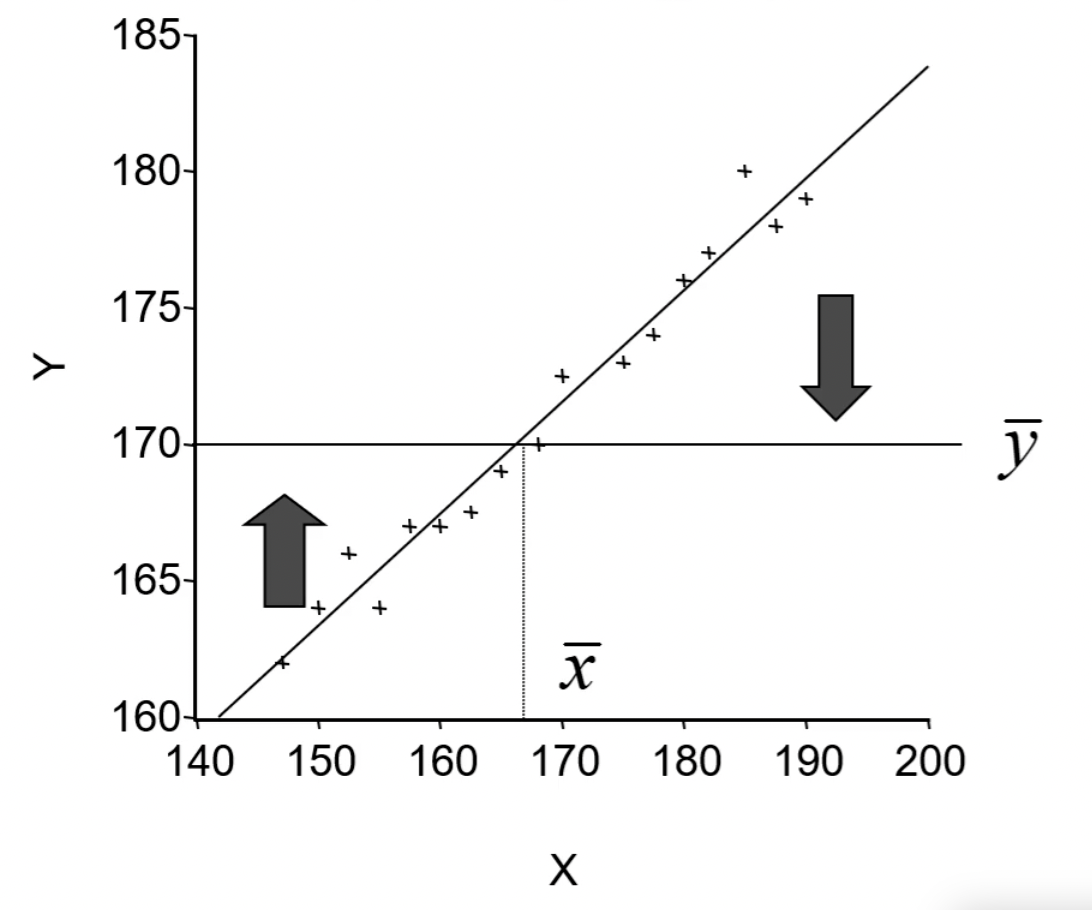
在 1889 年,那阵还没有计算机,道尔顿和他的朋友皮尔森收集了上千个家庭的身高、臂长和腿长的记录,企图寻找出儿子们身高与父亲们身高之间关系的具体表现形式。
看到皮尔森大家想到是什么样的内容?皮尔森也是一个统计学家,有个「皮尔森系数」。
那个时候他们也没有一个数据建模机器学习什么的,那他怎么去建模呢?他就认为儿子和父亲之间的关系用一个方程,拟合它就求解这个方程,把这个系数求出来就行了,就是最小二乘。
y = a + b x + u y ^ = 84.33 + 0.516 x \begin{align*} y & = a + bx + u \\ \hat y & = 84.33 + 0.516x \end{align*} yy^=a+bx+u=84.33+0.516x
所以最小二乘就是规定出来了一个标准,然后把这个参数拟合出来,通过导数为 0 的情况下极值来求解出来。这项乘法现在已经是一个重要的拟合技术,不仅仅用于我们刚才看到的线性回归,还在非线性的回归里面去使用。

所以非线性过程中也可以采用最小二乘法来做一个拟合,最小二乘法可以帮你来去拟合这样一个参数。
ALS 求解方法
到底是怎样一个使用过程呢?回到今天使用的 ALS 方法,对矩阵分解来求解一下。
- Step1, 固定 y 优化 x
我们想要去求解这个过程, r = x × y r = x \times y r=x×y,一个方程里面有两个未知数,能一次求解出来吗?求不出来。所以要固定一个求解另一个,如果把 y 固定了,也就是随机的初始一个 y,这个时候 y 是确定值,那么要求解的过程就变成了
m i n X u ∑ r u i ≠ 0 ( r u i − x u T y i ) 2 + λ ∑ ∣ ∣ x u ∣ ∣ 2 2 \begin{align*} min_{X_u} \sum_{r_{ui} \ne 0}(r_{ui} - x_u^T y_i)^2 + \lambda \sum||x_u||_2^2 \end{align*} minXurui=0∑(rui−xuTyi)2+λ∑∣∣xu∣∣22
原来后面是加了一个 y 2 y^2 y2, 因为 y 的平方是个固定的常量,任何的值 y 其实对它都没有影响。所以就把后面这项给它去掉了。那要拟合的话就变成了这个式子,所以要拟合它目标函数就是:
J ( x u ) = ( R u − Y u T x u ) T ( R u − Y u T x u ) + λ x u T x u \begin{align*} J(x_u) = (R_u - Y_u^T x_u)^T(R_u - Y_u^T x_u) + \lambda x_u^T x_u \end{align*} J(xu)=(Ru−YuTxu)T(Ru−YuTxu)+λxuTxu
转化为矩阵表达形式
R u = [ r u i 1 , . . . , r u i m ] T 用户对 m 个物品的评分 Y u = [ y i 1 , . . . , y i m ] m 个物品的向量 \begin{align*} R_u & = [r_{{ui}_1}, ..., r_{{ui}_m}]^T & 用户对 m 个物品的评分 \\ Y_u & = [y_{i_1}, ..., y_{i_m}] & m 个物品的向量 \end{align*} RuYu=[rui1,...,ruim]T=[yi1,...,yim]用户对m个物品的评分m个物品的向量
这个目标函数现在只有一个要求解的 x,什么情况下可以让目标函数最小化,也就是学习的目标最小化?应该就是刚才说的“导数为 0 ”的时候。导数为 0 就是对于 x 在这个点上去求导,对目标函数 J 关于 x u x_u xu 求梯度,并令梯度为零,得到
∂ J ( x i ) ∂ x u = − 2 Y u ( R u − Y u T x u ) + 2 λ x u = 0 \begin{align*} \frac{\partial J(x_i)}{\partial x_u} = -2Y_u(R_u - Y_u^Tx_u) + 2\lambda x_u = 0 \end{align*} ∂xu∂J(xi)=−2Yu(Ru−YuTxu)+2λxu=0
如果是这个式子等于 0 那 x 就直接求出来了。因为 y 是确定值,r 是确定值,lambda 是代入的人工设定的参数,它应该也是确定下来的。在学习参数之前,只有 x u x_u xu 是未知的。所以 x u x_u xu 就可以得到一个方程,具体求导的推导过程这里就不展开详细写了。
x u = ( Y u Y u T + λ I ) − 1 Y u R u \begin{align*} x_u = (Y_uY_u^T+\lambda I)^{-1}Y_uR_u \end{align*} xu=(YuYuT+λI)−1YuRu
那 y 确定情况下,x 就可以求出来了。
这个 x 是最终解吗?并不是,别忘记之前咱们说的前提是 y 固定的,因为 y 它还没有学完。这个过程就是先做了一边,先学好了 x。当你 y 确定下来之后像拧螺丝一样,这边就拧紧一些,但实际上它是两个都要学。
x 学好一部分,下一过程应该就是要学 y 了,所以在下个过程我们其实就是把 x 固定再优化 y。因为你已经把 x 确定下来了,通过导数为 0 直接可以计算出来,优化 y 跟刚才的过程原理是一样的,你就这里就把对 y 的导数求出来,这样 y 也优化了。
所以第二次 y 学到了,然后再下一次把 y 优化固定下来以后再优化 x,以此类推,我们就做了一个交替最小二乘。所以交替最小二乘的概念就是确定固定一个优化另一个。
我也不知道给大家讲明白没有,大家可以先理解概念,然后再去看公式。公式对于概念的理解并没有那么重要,咱们这里重点还是想要去把概念搞清楚。有什么问题呢,可以给我留言,文章下留言或者私信都可以。
所以交替最小二乘是一个优化的方法。同时学两个很难,但是我们可以固定一个求解另一个,当你固定一个的时候就变成了只需要学一个矩阵。那这个矩阵可以利用梯度为 0 的情况下来进行求解。在学习过程中其实不需要完全自己推导,要知道是它大概原理,为什么叫 ALS。不能说只知道名称叫 ALS,至少要知道它是个优化方法,这个优化方法利用了最小二乘来求解,最小二乘没法一步到位,因为有两个要学,所以就是固定一个求解另一个。这是我们这套方法核心的概念。
刚刚举的那个场景是一个显式的评分,思考一下,我们的行为除了显式的行为还有什么行为?在推荐系统里面还有一类数据也需要预估,就是你的隐式的行为数据。显式的是评分、购买、收藏、喜欢,都是一些明确的用户对商品的偏好。但隐式行为比较常见的应该是阅读时长,浏览、点击等等。点击了不代表你喜欢,只能代表你可能当下想要看一看,有可能你马上就关掉了,所以这个都属于隐式行为。
显式行为和隐式行为谁的数据量会更大?在推荐系统里面质量是一个维度,数据量也是个维度。如果数据量很小不太容易训练,训练的过程中我们其实希望数据量大一点会更好。应该是我们的隐式行为数据量更大,通常我们有个规则就是说 100 个人看帖只有一个人回帖。
那么猜你喜欢还要猜一下用户会不会点击,会不会浏览,这个也就是隐式行为的维度。同样可以把 ALS 这个方法用于隐式的矩阵分解。也就是说原来的数据都是一些浏览的行为、点击的行为,我们基于这些来去判断。
当 r u i > r_{ui} > rui> 0 时,用户 u 对商品 i 有行为,当 r u i = 0 r_{ui} = 0 rui=0 时,用户 u 对商品没有行为。
P u i = { 1 r u i > 0 0 r u i = 0 \begin{align*} P_{ui} = \begin{cases} 1 & r_{ui} > 0\\ 0 & r_{ui} = 0 \end{cases} \end{align*} Pui={10rui>0rui=0
P u i P_{ui} Pui 这里代表是用户的偏好,大于 0 的情况下,认为用户有行为,它是有偏好的,等于 0 的情况下是没有行为。
同理以刚才这个为例,也要建一个目标函数,看看这个目标函数长什么样,也分成两块。
m i n X , Y ∑ u , i c u i ( P u i − x u T y i ) 2 − λ [ ∑ u ∣ ∣ x u ∣ ∣ 2 2 + ∑ i ∣ ∣ y i ∣ ∣ 2 2 ] \begin{align*} min_{X, Y}\sum_{u,i}c_{ui}(P_{ui} - x_u^Ty_i)^2 - \lambda \left [ \sum_{u} ||x_u||_2^2 + \sum_{i} ||y_i||_2^2 \right ] \end{align*} minX,Yu,i∑cui(Pui−xuTyi)2−λ[u∑∣∣xu∣∣22+i∑∣∣yi∣∣22]
左边这是拆出来大矩阵的一个情况,把一个大矩阵拆成了 x 和 y,原来矩阵是 P u i P_{ui} Pui, P u i P_{ui} Pui 是 0 和 1,有行为和没有行为两个状态。拆完之后可以还原,让这两个结果误差最小。
前面还乘了一个 c u i c_{ui} cui, c u i c_{ui} cui 是对隐式矩阵进行分解,引入的置信度。你可以把它理解成是一个强度或者在计算误差的时候它有一个 weight。
c u i = 1 + α r u i \begin{align*} c_{ui} = 1 + \alpha r_{ui} \end{align*} cui=1+αrui
当 r u i > 0 r_{ui} > 0 rui>0 时, c u i c_{ui} cui与 r u i r_{ui} rui 显性递增,当 r u i = 0 r_{ui} = 0 rui=0 时, c u i = 1 c_{ui}=1 cui=1,也就是 c u i c_{ui} cui 最小值为 1.
举个场景,如果你要去预估一个疑似点击的误差。一个用户他可能对一个商品点击了 1 次和一个用户点击这个商品点击了 10 次,同样是一个商品,点击 1 次和点击 10 次,如果你预测的不准确谁的误差会更大一点?是点击 1 次的还是点击 10 次?
同样对一个商品用户以前有过行为,他如果有过 10 次行为的话更容易证明他的强度会更大,所以如果你预测的不准确,这里的 loss function 数值要加上一个倍数。如果要拟合的更好我们需要把这个倍数加进去。所以这里的倍数我们叫做 c u i c_{ui} cui,它就是个置信度,就是个强度的概念。
这个强度的概念就是希望对于那些用户行为过多的一些商品是具有一定的 weight,一个加成的属性。我们加成的 c u i c_{ui} cui 就如上方所写的公式,公式内的 α \alpha α是我们设定的一个系数, r u i r_{ui} rui 是点击的次数。就是它原来一个值,是跟你的点击次数成正比的。而原来如果 r u i r_{ui} rui 本身为 0 的情况下我们的倍数就为 1,所以 weight 最小值就是为 1。如果你之前实际点击过 10 次,基于这个公式计算 c u i c_{ui} cui 很明显它应该是大于 1 的一个值,因此在我们的公式里面它就加上了一个权重的概念。
同理我们想要去求解也是采用 ALS 交替最小二乘,固定 y 求 x
x u = ( Y Λ u Y T + λ I ) − 1 Y Λ u P u Λ u = [ c u 1 ⋱ c u M ] \begin{align*} x_u & = (Y\varLambda_uY^T+\lambda I)^{-1}Y\varLambda_uP_u \\ \varLambda_u & = \begin{bmatrix} c_{u1} & & \\& \ddots & \\ & & c_{uM} \end{bmatrix} \end{align*} xuΛu=(YΛuYT+λI)−1YΛuPu= cu1⋱cuM
Λ u \varLambda_u Λu为用户 u 对所有物品的置信度 c u i c_{ui} cui 构成的对角阵。
过程就不给大家推导了,因为原理都是 X,Y,跟刚才那个过程都是类似的,只不过现在用了一个 P 矩阵不是 R 矩阵了。还有,我们又有一个 C 作为我们的置信度。结论就是说我们按照导数为 0 的情况下以 y 确定了求 x,就是求它导数为 0 的极值的情况,就可以把这个值求解出来。而中间这个lambda对角就等于
c
u
i
c_{ui}
cui 的一个值。而这是求出来的一个 x 的一个过程,同样 x 求完以后再回头来求 y,直到把这个结果求完。
那我们来思考一下,在原来固定 y 求 x 过程中,最开始那个 y 是怎么选的呢?其实这个也不难,最开始只要随机、给它一个初始化的值就行了,就像我们去训练一些值,训练 LR,SVM 时这些参数它怎么来的,怎么学的?其实在背后计算机里面都是给它一个随机值,先给它一个初始化的值。对最终的结果有没有影响呢?对最终的结果影响不大,基本上是没有影响的。
当你理论上运行足够多的次数,它的状态应该是统一的,这是理论的一个足够多次数。那如果你的次数相对固定,比如说 20 次还是 30 次它的结果差别也不是很大。这是固定一边求解另一边,再把 x 固定再求解完也是一样的。那么在求 X、Y 的过程中,如果把 x 它的这个公式求完了 y 相对来说好求。为什么,X、Y 它有什么样的性质?它的性质也比较简单,X、Y 的性质我们把它称为叫对称性,所以对称性只需要把 X、Y 变一下就可以得出来。
这个就是我们的 ALS 用于隐式的分解。所以 ALS 它是个矩阵分解的一套方法,这套方法既可以用到显式,也可以用到隐式。
那让我们在回顾一下,这节课有点长。我们先从一个例子出发,给了 12 个人和 9 部电影打分的情况让你去预估这 12 个人对没有打分那些电影会打成多少分,这是我们的业务场景。在去求解这个业务场景过程中我们要采用了一个降维的策略,拆出来 user 矩阵和 item 矩阵,猜出来后那怎么评估它猜的好坏呢?目标是要学出来这两个矩阵,怎么去评估它的好坏?我们就需要有一个方程,通过它来去评估。那目标函数包含了两部分,一部分是 MSE,一部分是 L2 正则。
方程建好之后,参数 X、Y 怎么学?通过 ALS。ALS 就是固定一个求解另一个,这样不断地固定和求解,x y 就求出来了。再把 x、y 做一个乘法,就得到 R’,R’和 R 之间他们已知的地方已经比较接近了,误差比较小了,那么未知地方我们就可以用 R’预估出来这个值来去代表你的预测值。这样预测值从大到小做排序就可以给用户做推荐。
以上就把我们刚刚 ALS 矩阵分解大概原理给大家讲完了。这是推荐系统里一个非常核心的概念,就是猜你喜欢,猜到没有填的那个分数到底属于多少分。
















 2106
2106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











