







一元线性回归
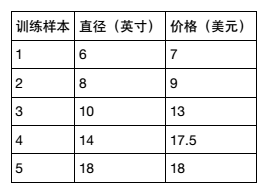
假设你想计算匹萨的价格。 虽然看看菜单就知道了,不过也可以用机器学习方法建一个线性回归模型,通过分析匹萨直径与价格的线性关系,来预测任意直径匹萨的价格。假设我们查到了部分匹萨的直径与价格的数据,这就构成了训练数据,如下表所示:
import matplotlib.pyplot as plt
def runplt():
plt.figure()
plt.title("Cost and diameter")
plt.xlabel("Diameter/inch")
plt.ylabel("Cost/dollar")
plt.axis([0,25,0,30])
plt.grid(True)
return plt
plt = runplt()
X = [[6],[8],[10],[14],[18]]
y = [[7],[9],[13],[17.5],[18]]
plt.plot(X,y,'k.')
plt.show()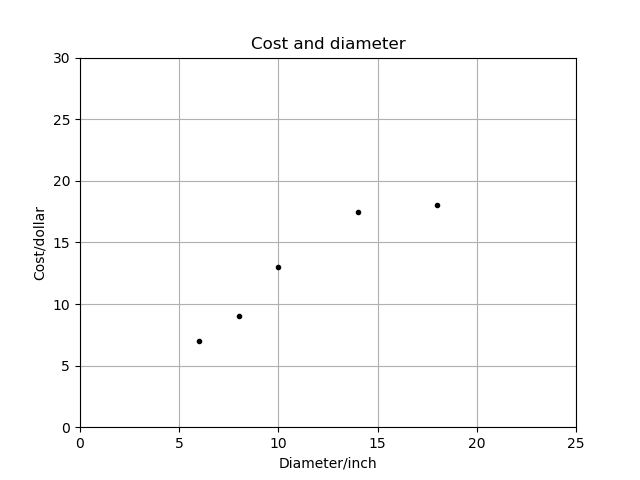
上图中,x轴表示匹萨直径,y轴表示匹萨价格。 能够看出,匹萨价格与其直径正相关,这与我们的日常经验也比较吻合,自然是越大越贵。
下面就用 scikit-learn 来建模
#创建并拟合模型
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X,y)
print("Predict 12 inch cost:$%.2f" % model.predict([[12]]))
>> Predict 12 inch cost:$13.68上述代码中 sklearn.linear_model.LinearRegression 类是一个估计器(estimator)。 估计器依据观测值来预测结果。 在 scikit-learn 里面,所有的估计器都带有 fit() 和 predict() 方法。 fit() 用来分析模型参数,predict() 是通过 fit() 算出的模型参数构成的模型,对解释变量进行预测获得的值。 因为所有的估计器都有这两种方法,所有 scikit-learn 很容易实验不同的模型。 LinearRegression 类的 fit() 方法学习下面的一元线性回归模型:

plt = runplt()
X = [[6],[8],[10],[14],[18]]
y = [[7],[9],[13],[17.5],[18]]
model = LinearRegression()
model.fit(X,y)
X2 = [[0], [10], [14], [25]]
y2 = model.predict(X2)
plt.plot(X, y, 'k.')
plt.plot(X2, y2, 'g-')
plt.show()
带成本函数的模型拟合评估
由若干参数生成的回归直线。 如何判断哪一条直线才是最佳拟合呢?
一元线性回归拟合模型的参数估计常用方法是普通最小二乘法(ordinary least squares )或线性最小二乘法(linear least squares)。 首先,我们定义出拟合成本函数,然后对参数进行数理统计。
成本函数(cost function)也叫损失函数(loss function),用来定义模型与观测值的误差。 模型预测的价格与训练集数据的差异称为残差(residuals)或训练误差(training errors)。 后面会用模型计算测试集,那时模型预测的价格与测试集数据的差异称为预测误差(prediction errors)或训练误差(test errors)。模型的残差是训练样本点与线性回归模型的纵向距离,如下图所示:
model = LinearRegression()
model.fit(X,y)
X2 = [[0], [10], [14], [25]]
y2  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









