







 超级会员免费看
超级会员免费看
动态slimmable网络:高性能的网络轻量化方法!对比slimmable涨点5.9%
论文链接:
https://arxiv.org/abs/2103.13258
代码:
https://github.com/changlin31/DS-Net
一、研究动机
动态剪枝算法及其问题
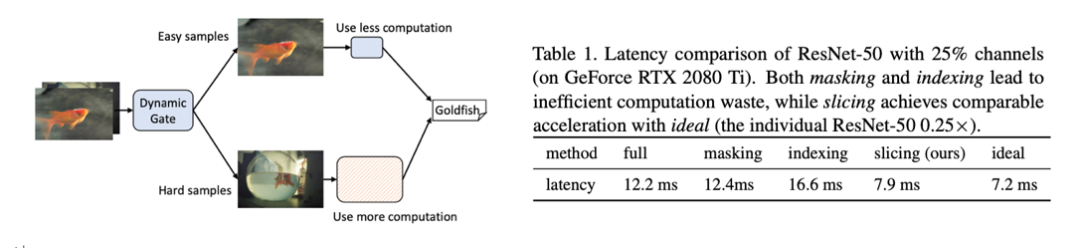
动态网络为每个输入自适应地配置不同的网络结构,而不是像神经网络搜索(NAS)或剪枝那样在整个数据集上优化网络结构,例如,根据每张输入图像的分类难度,将其路由到不同的计算复杂度的网络结构减少了在简单样本上的计算浪费,提高网络效率(见上图)。
其中动态剪枝方法,作为剪枝的自然扩展,在运行时根据不同的输入对卷积滤波器进行预测剪枝。这种变化的稀疏模式(spasepattern)与硬件计算不兼容。实际上,许多算法都是以零掩码(zero-masking)或低效路径索引(indexing)的方式实现的,这使得理论分析与实际加速之间存在很大的差距。如上表所示,masking和indexing都没有实际的加速效果,导致了计算浪费。本文作者提出一种致密(dense)的动态channel切分(dynamic channel slicing)方法,达到了与理论相符的加速效果(见上表)。
二、动态宽度可变超网络
Dynamic Slimmable Supernet

动态宽度可变网络(DS-Net)通过学习一个宽度可变超网络和一个动态门控机制来实现不同样本的动态路由。如上图所示,DS-Net中的超网络(上图黄色框)是指承担主要任务的整个模块。相比之下,动态门控(上图蓝色框)是一系列预测模块,它们将输入样本路由到超网络的不同宽度的子网络。
之前的动态网络工作将门控和超网络一起训练,而本文为了提高超网络中每个子网络的泛化性,提出了解缠的两阶段训练方法:
在第一阶段,禁用门控并用IEB技术训练超网络;
在第二阶段,固定超级网的权重并用SGS技术训练动态门控。
1.动态超网络(supernet)和动态可切分(slice-able)卷积
为避免产生稀疏channel,作者提出动态可切分(slice-able)卷积,通过预测出的剪枝率 𝜌,动态的切分使用卷积的前 𝜌× n个滤波器(n为总滤波器数)。
通过堆叠动态可切分(slice-able)卷积并禁用动态门控,就形成了类似slimmablenetwork的动态超网络。
2.In-place Ensemble Bootstrapping(IEB)
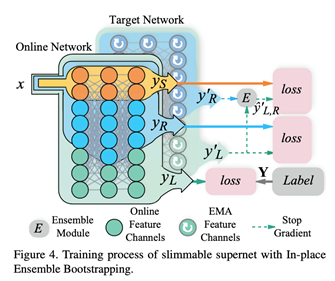
之前的slimmable network训练使用in-place distillation方法:最宽的子网络学习预测真实标签,同时生成软标签,并通过知识蒸馏的方式来训练其他较窄的子网络。但in-place distillation训练很不稳定,权重在训练早期会大幅突变,并可能导致模型最终训练失败或性能损失。
为此,作者提出In-place Ensemble Bootstrapping(IEB)策略来稳定动态超网络的训练并最终提高模型性能。首先,使用超网络的滑动平均(EMA)网络来生成训练子网络的软标签,因为EMA网络提供的目标更加稳定和精准。其次,使用包括最宽子网络和随机宽度子网络的多个模型的概率集成(probability ensemble)作为训练最窄网络的目标,因为多模型集成可以提供更多样、更泛化、更精准的软标签。(见上图)
三、动态宽度门控
(Dynamic Slimming Gate)
作者设计了双头(double headed)动态宽度门控的结构,并提出gate的训练策略sandwich gate sparsification(SGS)。
1. 双头门控设计

首先,作者提出通过当前层输入特征来预测出一个one-hot向量,对应选择剪枝率列表中的一个值。输入特征首先通过全局池化(global pooling)来消除空间维度,再通过两个以ReLU相隔的全连接层,并求argmax,得到one-hot向量。由于这一结构与频道注意力相似,作者将两者除最后一层全连接外的层进行共享,形成包含动态宽度头和频道注意力头的双头动态宽度门控。
2. Sandwich Gate Sparsification(SGS)
由于argmax不可导,之前使用argmax作为网络中间层的工作一般使用gumbel-softmax作为替代,来近似求导,以便梯度回传。但是,本文作者发现采用这个方法进行gate训练时,很容易使其gate坍塌成静态。
为此,作者提出Sandwich Gate Sparsification训练策略。首先,每个输入样本都按,“是否能被最窄网络正确预测”,分为容易和困难两类。然后,将两类难易样本打上one-hot标签,使用交叉熵直接优化gate。这种训练方式避免了间接和近似的梯度回传,克服了gate收敛困难的问题,并提高了gate的动态多样性。
四、实验
1. ImageNet结果
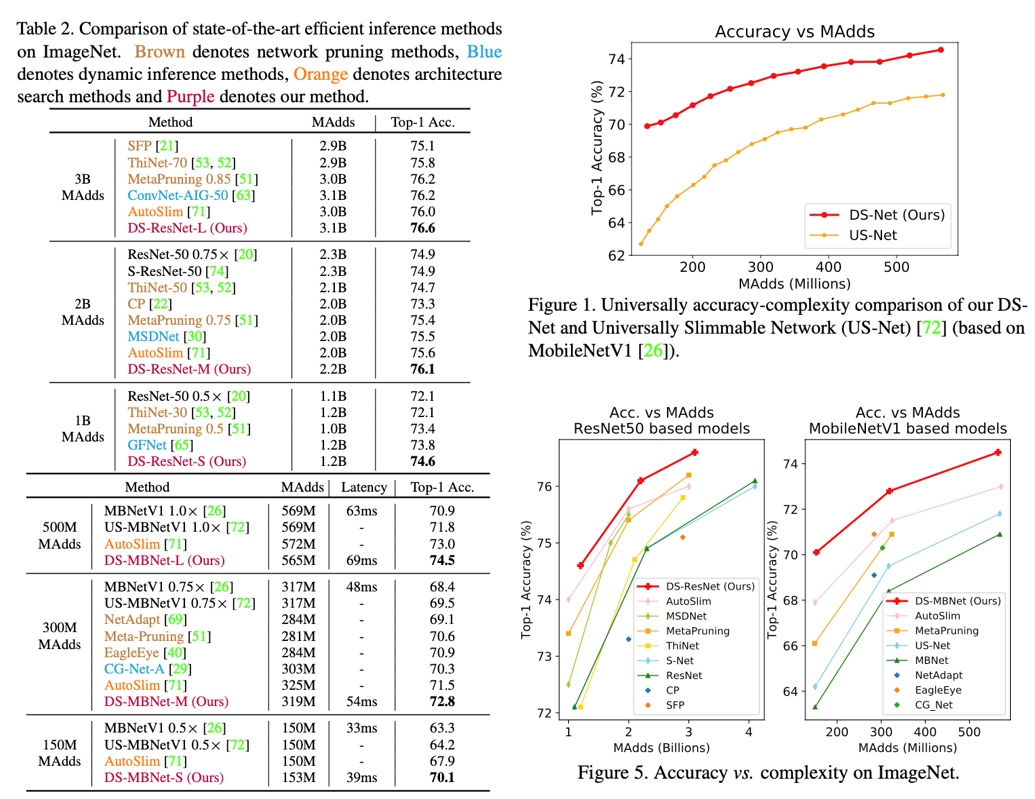
如Table 2和Figure 5所示,DS-Net超过了现有的模型压缩方法:DS-Net成功加速ResNet-50和MobileNetV1(2-4倍的计算量减少,和1.17倍、1.62倍的实际加速);优于静态剪枝方法,比EagleEye和Meta-Pruning分别高出1.9%和2.2%;优于其他强大的动态网络,比动态剪枝方法CGNet高出2.5%;也优于静态slimmable网络,比AutoSlim和US-Net分别高出2.2%和5.9%(Figure 1)。
2. CIFAR-10迁移结果和VOC目标检测结果

在CIFAR-10上,DS-ResNet可减少2.5倍计算量,并在精度上超过原ResNet50 0.6%和1.0%,甚至以五分之一的计算量,超过ResNet101。(Table 3)
在VOC目标检测任务,DS-MBNet相比原MobileNet达成了0.9和1.8的mAP提升,同时计算量分别减少1.59倍和1.34倍。(Table 4)
3. 消融实验
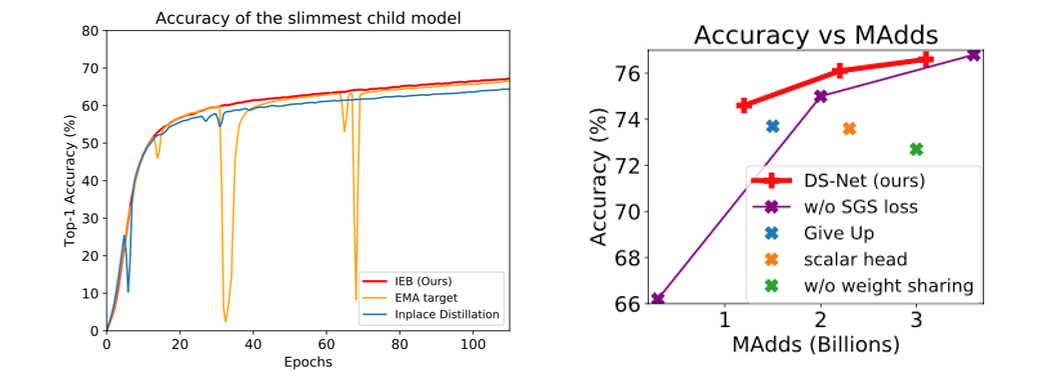
见上图左侧,使用IEB时,supernet避免了训练过程中的精度的波动,稳定的收敛到更高的精度(Figure 6),在最窄和最宽的子网络上比in-placedistillation分别提高了1.8%和0.6%。
见上图右侧,使用SGS时(红色线),优于不使用SGS的精度(紫色线);使用双头权重共享门控(红色线),优于不使用权重共享(绿色点);使用one-hot方式预测(红色线),优于直接预测标量剪枝率(橙色点)。
更多实验和细节请参照文章。















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









