










用Python获取Accuweather天气预报数据
Retrieve Weather Forecast Data in Python from Accuweather.com
By Jackson@ML
Web Scraping即Web网络爬取,是数据采集广泛采用的方式。为了进行必要的教学实验,本文尝试利用Python第三方库爬取Accuweather天气信息网站的基本数据。希望对广大读者有所帮助。
本次采集数据的库为requests-html, 在第三方库官网:https://pypi.org获取基本信息。
下面是该项目实现的主要步骤和基本思路。
1. 安装requests-html库
用pip安装必要的requests-html库,命令如下:
$ pip install requests-html
2. 导入HTMLSession库
从requests_html库导入模块HTMLSession:
$ from requests_html import HTMLSession
3. 建立一个会话
$ s = HTMLSession()
4. 选定目标url
选择需要获取数据的Web页面(例如:上海天气),复制完整的url并赋予变量。
该url根据不同Web站点,能够灵活输出用来处理天气数据。
url = f'https://www.accuweather.com/en/cn/shanghai/106577/weather-forecast/106577'
5. 构建requests并解析页面数据
复制页面的’User-Agent’属性文本,然后构建页面数据并赋予headers变量。
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36’
}
r = s.get(url, headers)
6. 编写完整代码,获取并输出天气数据情况
若要得出天气预报title,以及当地气温,则要搜索Web页面关键tag。可创建变量接收天气数据获取结果,由requests实例的html.find函数来获取。
*注:特定数据须与Web页面特定tag对应,例如和页面id – span的值对应。
temp = r.html.find(‘span#wob_tm’, first=True).text
同样,需要找到温度(摄氏度)单位标记和页面的class-vk_bk wob-unit的值相对应。
unit = r.html.find(‘div.vk_bk.wob-unit span.wob_t’, first=True)
再找到页面tag嵌套的描述数据,即div中嵌套的span,赋予变量desc, 如下代码:
desc = r.html.find(‘div.VQF4g’, first=True).find(‘span#wob_dc’, first=True).text
最终,将上述变量获取数据,打印输出到屏幕:
print(query, temp, unit, desc)
7. 实现项目代码
1)创建项目
建立项目文件夹weather-scraping,在旗下建立虚拟环境并激活(具体过程略,参看其它文章)。切换到项目代码文件夹。
使用命令ls 列出当前目录文件清单;同时,用touch命令创建新的Python文件,名为wether-scraping.py, 如下图:

2) 安装第三方库
进入到该环境,安装必要的库。
访问pypi.org官网,查找requests-html库的基本信息,如下图:
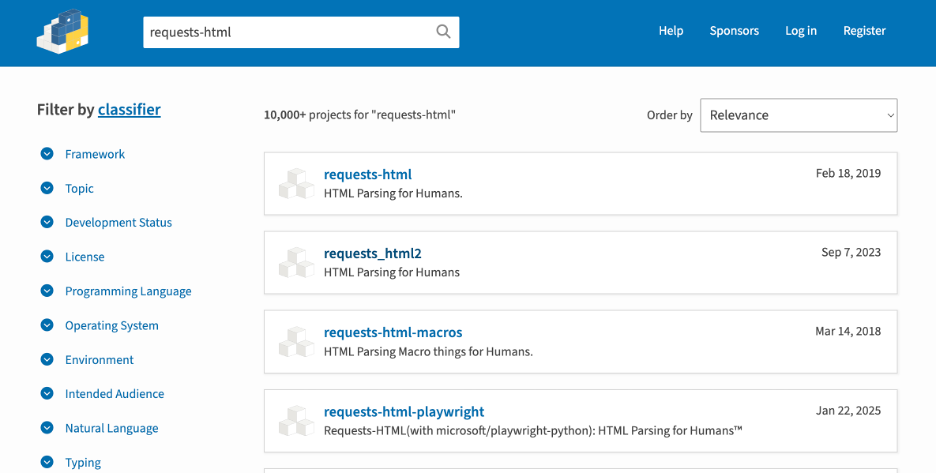
点击最上方的库链接,进入到详情页面。
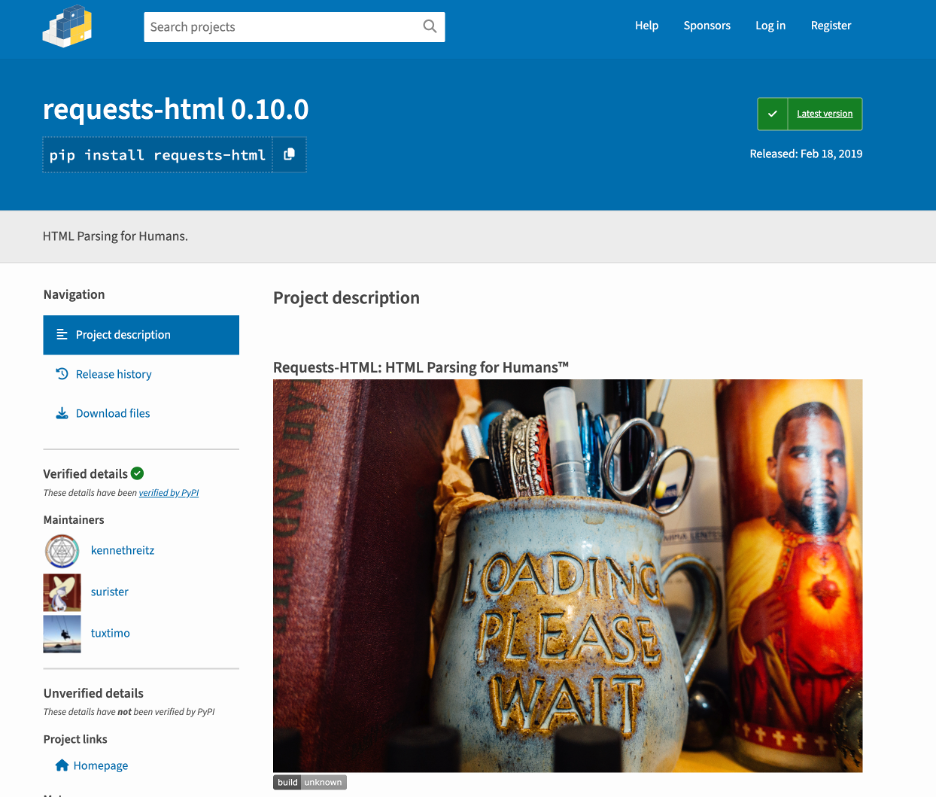
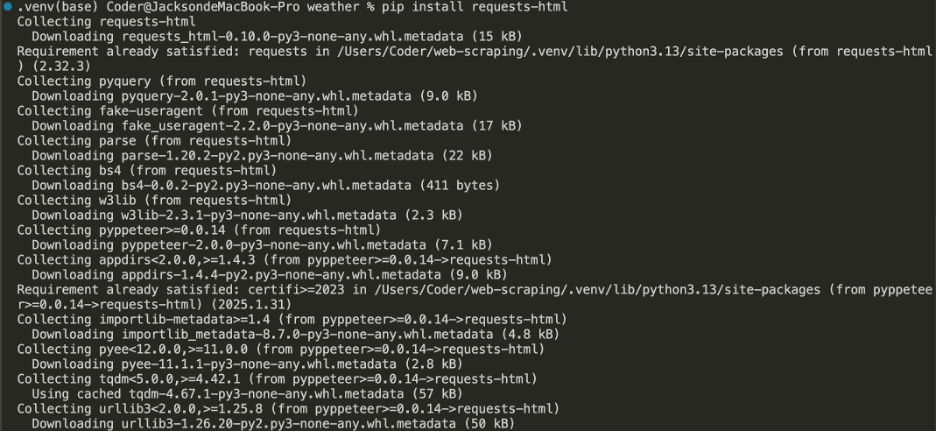
按照提示,在VS Code中新建Terminal(终端),并运行该命令安装库:
$ pip install requests-html
执行结果如下:
末了,提示pip版本过低,需要更新,因此执行命令:
$ pip install --upgrade pip
执行结果如下:

可看到,pip版本升级到pip-25.0.1。
这时候,还需要安装lxml,用来解析Web页面具体tag数据。

安装lxml-html-clean库:
$ pip install lxml_html_clean
执行结果如下:

3) 代码实现
根据前述章节,分别实现了必要的库安装、导入,并且建立headers,输入url(天气网站Web链接)以及利用HTMLSession模块实例方法get,以及其html方法find获取网站特定tag数据后,打印输出到Terminal(终端)。
我们简要获取Accuweather天气网站的title信息,代码如下:
from requests_html import HTMLSession
from lxml.html.clean import Cleaner
s = HTMLSession()
url = f'https://www.accuweather.com/en/cn/shanghai/106577/weather-forecast/106577'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36',
}
r = s.get(url, headers=headers)
search_site = r.html.find('title', first=True).text
print(f"Weather Forecast from:{search_site}")
在VS Code终端运行,结果如下图:

说明Web文本信息采集成功!
Web页面相应的选择器以及tag都可用于数据采集。后续相关项目的数据采集,将会有进一步项目实战奉上!
敬请关注、点赞和收藏。👍
您的认可,我的动力! 😃

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









