







1 编程基础知识准备
函数编程环境
函数编程语言
2 推荐理论知识准备
协同过滤
基于物品的item-cf
基于用户的item-cf
FM
根据内容语意的词频
余弦相似度:数字表达后的夹角相似度
特征编码:对分类类型进行数字表示
独热编码:将类别编码 作为 数据表达,稀疏维度过高
emedding:稠密向量
向量:加入方向
矩阵:图片网格变成数字矩阵,销售省市数据变成数字矩阵
张量:
欧式距离:两点之间的距离
3 模型评估
均方根误差:两个向量平方相减开平方根
ROC:预测结果按照正,负概率排序,绘制真正率和假正率曲线,反应模型准确率
召回率:点击数据/模型预测数据
覆盖率:数据类别占总类别占比
信息流:带上下文的信息数据
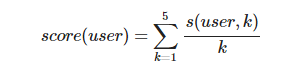
推荐系统测量指标:
1)用户满意度。这是最最关键的指标,推荐的内容用户喜欢。可以有两种方法,一是用户问卷调查,二是在线评测满意度,比如豆瓣的推荐物品旁边都有满意和不满意的按钮,亚马逊这种可以计算推荐的物品有没有被用户购买等等,一般用点击率,用户停留时间,转化率等指标来度量。
2)预测准确度。如果是类似电影评分机制,则一般计算均方根误差(误差平方和取均值)和平均绝对误差(误差绝对值和取平均)。如果是topN推荐的话,则主要计算召回率和准确率。准确率就是指我推荐的n个物品中有多少个是对的,其所占的比重。 召回率则是指正确结果中有多少比率的物品出现在了推荐结果中。两者的不同就是前者已推荐结果个数当除数,后者已正确结果个数当除数。
3)覆盖率。 推荐系统能够推荐出来的物品占总物品集合的比例。精确一点的可以信息熵和基尼系数来度量。
4)多样性。推荐结果中要体现多样性,比如我看电影,我既喜欢看格斗类的电影,同时又喜欢爱装文艺,那么给我的推荐列表中就应该这两个类型的电影都有,而且得根据我爱好比例来推荐,比如我平时80%是看格斗类的,20%是看文艺类的,那么推荐结果中最好也是这个比例。可以根据物品间的相似度来计算,一个推荐列表中如果所有内容的相似度都比较高,那么往往说明都是同一类内容,缺乏多样性。
5)新颖性。用户不知道的内容。方法一是取出已经看到过的内容,但这还不够,一般会计算推荐内容热门度,因为通常越不热门的内容越会让用户觉得新颖。比如我爱周星驰,那么推荐《临岐》就很有新颖性,因为大家都不知道这是周星驰出演的。
6)惊喜度。 定义惊喜度需要首先定义推荐结果和用户历史上喜欢的内容的相似度,其次需要定义用户对推荐结果的满意度。前面也曾提到,用户满意度只能通过问卷调查或者在线实验获得,而推荐结果和用户历史上喜欢的物品相似度一般可以用内容相似度定义。比如电影,但是我看了之后觉得很符合我的胃口,这就是惊喜度。像上面一个例子,只要我知道是周星驰演的,那可能就没什么惊喜度,因为我知道是因为演员才给我推荐的这部电影。 注:新颖性和惊喜度暂时没有什么可以度量的标准
7)信任度。如果用户信任推荐系统,那么往往会增加与推荐系统的互动,从而获得更好的个性化推荐。
度量推荐系统的信任度只能通过问卷调查的方式,询问用户是否信任推荐系统的推荐结果。
只有让用户了解推荐系统的运行机制,让用户认同推荐系统的运行机制,才会提高用户对推荐系统的信任度。其次是考虑用户的社交网络信息,利用用户的好友信息给用户做推荐,并且用好友进行推荐解释。
8)实时性。推荐系统需要实时地更新推荐列表来满足用户新的行为变化。
实时性的第二个方面是推荐系统需要能够将新鲜内容推荐给用户。
对于新内容推荐能力,我们可以利用用户推荐列表中有多大比例的物品是当天新加的来评测。
9)健壮性。即robust,鲁棒性)指标衡量了一个推荐系统抗击作弊的能力。
用常用的攻击方法向数据集中注入噪声数据,然后利用算法在注入噪声后的数据集上再次给用户生成推荐列表。最后,通过比较攻击前后推荐列表的相似度评测算法的健壮性。如果攻击后的推荐列表相对于攻击前没有发生大的变化,就说明算法比较健壮。
评测推荐效果的实验方法:
1)离线实验。 往往是从日志系统中取得用户的行为数据,然后将数据集分成训练数据和测试数据,比如80%的训练数据和20%的测试数据(还可以交叉验证),然后在训练数据集上训练用户的兴趣模型,在测试集上进行测试。 优点:只需要一个数据集即可,不需要实际的推荐系统(实际的也不可能直接拿来测试),离线计算,不需要人为干预,能方便快捷的测试大量不同的算法。缺点是无法获得很多实际推荐系统的指标,比如点击率,比如转化率(谁让没有人为干预呢。。)
2)用户调查。 离线实验往往测的最多的就是准确率,但是准确率不等于满意度,所以在算法上线之前,需要用户调查一下,测试一下用户满意度。
3)AB测试,通过一定的规则把用户随机分成几组,并对不同组的用户采用不同的推荐算法,这样的话能够比较公平的获得不同算法在实际在线时的一些性能指标。但是缺点是周期比较长,需要长期的实验才能得到可靠的结果。















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









