







1、准备数据集,提取特征,作为输入喂给神经网络( Neural Network NN)
2、搭建 NN 结构,从输入到输出(先搭建计算图,再用会话执行)
3、大量特征数据喂给 NN ,迭代优化 NN 参数
4、使用训练好的模型预测和分类
基于tensorflow的前向传播
变量初始化:在 sess.run 函数中用 tf.global_variables_initializer() 汇总所有待优化变量。
init_op = tf.global_variables_initializer()
sess.run(init_op)
计算图节点运算:在sess.run函数中写入待运算的节点
sess.run(y)
用 tf.placeholder占位,在 sess.run 函数中用函数中用 feed_dict喂数据
with tf.Session() as sess:
#喂一组数据:
x = tf.placeholder(tf.float32, shape=(1, 2))
y = x + x
r = sess.run(y, feed_dict={x: [[0.5,0.6]]})
print(r)
#喂多组数据:
x = tf.placeholder(tf.float32, shape=(None, 2))
y = tf.reduce_sum(x, 0)
r = sess.run(y, feed_dict={x: [[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})
print(r)
反向传播
反向传播 :训练模型参数 ,在所有参数上用梯度下降,使神经网络模型在训练数据上的损失函数最小。
损失函数
损失函数的计算有很多方法。
解决回归问题的损失函数:均方误差MSE
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uNKGPLo0-1591241211997)(images/1563865732862.png)]
用tensorflow 函数表示为loss_mse = tf.reduce_mean(tf.square(y_ - y))
反向传播训练方法: 以减小 loss 值为优化目标 ,有梯度下降 、 adam优化器等优化方法。
这两种优化方法用tensorflow 的函数可以表示为:
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
train_step=tf.train.AdamOptimizer(learning_rate).minimize(loss)
-
tf.train.GradientDescentOptimizer 使用随机梯度下降算法,使参数沿着
梯度的反方向,即总损失减小的方向移动,实现更新参数。其中,𝐽(𝜃)为损失函数, 𝜃为参数, 𝛼为学习率。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VWakDA4h-1591241211999)(images/1563866296204.png)]
-
tf.train.AdamOptimizer() 是利用自适应学习率的优化算法, Adam 算法和随机梯度下降算法不同。随机梯度下降算法保持单一的学习率更新所有的参数,学习率在训练过程中并不会改变。而 Adam 算法通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
学习率 learning_rate: 决定每次参数更新的幅度。
优化器中都需要一个叫做学习率的参数,使用时如果学习率选择过大会导致待优化的参数在最小值附近波动不收敛的情况,如果学习率选择过小,会出现收敛速度慢的情况。 我们可以选个比较小的值填入, 比如 0.01 、 0.001。
解决分类问题的损失函数:交叉熵( cross entropy )
假设有两个分布p(1, 0, 0)与 q(0.8, 0.1, 0.1),则它们在给定样本集上的交叉熵定义如下:
C
E
(
p
,
q
)
=
−
∑
p
(
x
)
l
o
g
q
(
x
)
CE(p,q)=−\sum_{}p(x)logq(x)
CE(p,q)=−∑p(x)logq(x)
用Tensorflow 函数表示
ce=-tf.reduce_sum(p * tf.log(tf.clip_by_value(q, 1e-12, 1.0)))
(1e-12 是为了防止log0出现)clip_by_value小于1e-12变为1e-12,大于1.0变为1.0
两个神经网络模型解决二分类问题中,已知标准答案为p = (1, 0),第一个神经网络模型预测结果为q1=(0.6, 0.4),第二个神经网络模型预测结果为q2=(0.8, 0.2),判断哪个神经网络模型预测的结果更接近标准答案。
根据交叉熵的计算公式得:
H1((1,0),(0.6,0.4)) = -(1*log0.6 + 0*log0.4) ≈≈ -(-0.222 + 0) = 0.222
H2((1,0),(0.8,0.2)) = -(1*log0.8 + 0*log0.2) ≈≈ -(-0.097 + 0) = 0.097
由于0.222>0.097,所以预测结果y2与标准答案与标准答案y_更接近,y2预测更准确。
总结:
交叉熵刻画了两个概率分布之间的距离, 它是分类问题中使用比较广的一种损失函数。
交叉熵越大,两个概率分布距离越远, 两个概率分布越相异 ;
交叉熵越小,两个概率分布距离越近 ,两个概率分布越相似 。,6,7,8
TensorFlow针对分类问题,实现了常见的交叉熵函数,分别是
- tf.nn.sigmoid_cross_entropy_with_logits
tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels)
计算方式:对输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得的结果不至于溢出。
适用:每个类别相互独立但互不排斥的情况:例如一幅图可以同时包含一条狗和一只大象。
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用。
import tensorflow as tf
import numpy as np
# 5个样本三分类问题,且一个样本可以同时拥有多类
y = np.array([[1,0,0],[1,0,0]], dtype='f8')
y_ = np.array([[12,3,2],[3,10,1]], dtype='f8')
sess =tf.Session()
y = np.array(y).astype(np.float64) # labels是float64的数据类型
error = sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_))
print(error)
print(error.mean(axis=1))
- tf.nn.softmax_cross_entropy_with_logits
tf.nn.softmax_cross_entropy_with_logits(labels=None, logits=None)
计算方式:对输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
适用:每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象。
import tensorflow as tf
import numpy as np
y = np.array([[1,0,0],[1,0,0]], dtype='f8')# 每一行只有一个1
y_ =np.array([[12,3,2],[3,10,1]], dtype='f8')
sess = tf.Session()
error = sess.run(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=y_))
print(error)
基于tensorflow训练神经网络
#coding utf-8
#导入模块,生成模拟数据集
import tensorflow as tf
import numpy as np
import sklearn.datasets as datasets
import matplotlib.pyplot as mp
BATCH_SIZE = 8 #批次 一批跑8个样本
X, Y = datasets.make_moons(200, noise=0.10)#造月亮 (200,2) (200,)
Y = np.array(np.column_stack((Y, ~Y+2)), dtype='f4')#(200,2)
print(Y)
#定义神经网络的输入、参数和输出,定义向前传播过程
x = tf.placeholder(tf.float32, shape=(None,2), name='x')
y = tf.placeholder(tf.float32, shape=(None,2), name='y')
w1 = tf.Variable(tf.random_normal((2,3),stddev=1,seed=1))
b1 = tf.Variable(tf.random_normal((3,),stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal((3,2),stddev=1,seed=1))
b2 = tf.Variable(tf.random_normal((2,),stddev=1,seed=1))
l1 = tf.nn.sigmoid(tf.add(tf.matmul(x,w1), b1)) #xw1+b1
y_ = tf.add(tf.matmul(l1,w2), b2)
#定义损失函数及反向传播方法
loss = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=y_)) #括号内单样本的交叉熵
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
#train_step=tf.train.AdamOptimizer(0.001).minimize(loss) #优化loss
#生成会话,训练STEPS轮
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
#训练模型
STEPS = 30000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = start + BATCH_SIZE
sess.run(train_step,feed_dict={x:X[start:end], y:Y[start:end]})
if i % 500 ==0: #每隔500输出一个loss值
total_loss = sess.run(loss,feed_dict={x:X, y:Y})
print("After %d training steps, loss on all data is %g"%(i,total_loss))
pred_y = sess.run(y_, feed_dict={x:X})
pred_y = np.piecewise(pred_y, [pred_y<0, pred_y>0], [0, 1])
l, r = X[:, 0].min() - 1, X[:, 0].max() + 1
b, t = X[:, 1].min() - 1, X[:, 1].max() + 1
n = 500
grid_x, grid_y = np.meshgrid(np.linspace(l, r, n), np.linspace(b, t, n))
samples = np.column_stack((grid_x.ravel(), grid_y.ravel())) #(250000, 2)
grid_z = sess.run(y_, feed_dict={x:samples})
grid_z = grid_z.reshape(-1, 2)[:,0] #(250000,)
grid_z = np.piecewise(grid_z, [grid_z<0, grid_z>0], [0, 1])
grid_z = grid_z.reshape(grid_x.shape)
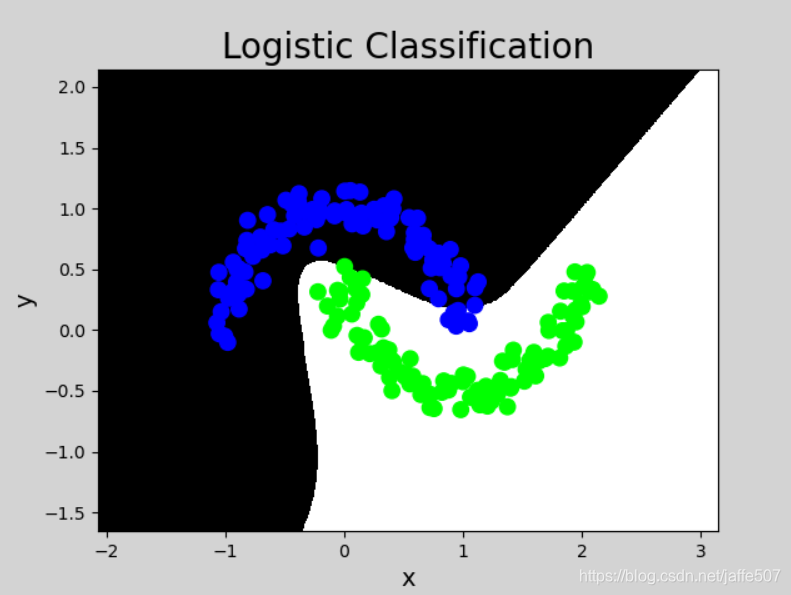
mp.figure('Logistic Classification', facecolor='lightgray')
mp.title('Logistic Classification', fontsize=20)
mp.xlabel('x', fontsize=14)
mp.ylabel('y', fontsize=14)
mp.tick_params(labelsize=10)
mp.pcolormesh(grid_x, grid_y, grid_z, cmap='gray')
mp.scatter(X[:, 0], X[:, 1], c=Y[:,0], cmap='brg', s=80)
mp.show()
由神经网络的实现 结果,我们可以看出,总共 训练 30000 轮。 每轮从 X 的数据集和 Y 的标签中抽取相对应的从 start 开始到 end 结束个特征值 和 标签 喂入神经网络。 用 sess.run 求出 loss, 每 500 轮打印一次 loss 值 。经过 3000 轮后 我们打印出 最终训练好的 参数 w1 、 w2 。














 2673
2673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









