









1. 概述
官网:https://github.com/gpustack
Open-source GPU cluster manager for running large language models(LLMs)
https://github.com/gpustack/gpustack,Manage GPU clusters for running AI models
GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。
官网特性介绍,具体可以参见相关 gpustack/README_CN.md at main · gpustack/gpustack
一个 100% 开源的大模型服务平台,用户只需要简单的设置,就可以高效整合包括 NVIDIA、Apple Metal、华为昇腾和摩尔线程在内的各种异构 GPU/NPU 资源,构建异构 GPU 集群,在私有环境提供企业级的大模型部署解决方案。
GPUStack 支持私有化部署 RAG 系统和 AI Agent 系统所需的各种关键模型,包括 LLM 大语言模型、VLM 多模态模型、Embedding 文本嵌入模型、Rerank 重排序模型、Text-to-Image 文生图模型,以及 Speech-to-Text(STT)和 Text-to-Speech(TTS)语音模型等。并提供统一认证和高可用负载均衡的 OpenAI 兼容 API,供用户从各类大模型云服务无缝迁移到本地部署的私有大模型服务。
GPUStack 是一个集群化和自动化的大模型部署解决方案,用户不需要手动管理多台 GPU 节点和手动协调分配资源,通过 GPUStack 内置的紧凑调度、分散调度、指定 Worker 标签调度、指定 GPU 调度等各种调度策略,用户无需手动干预即可自动分配合适的 GPU 资源来运行大模型。
对于无法在单个 GPU 节点运行的大参数量模型,GPUStack 提供分布式推理功能,可以自动将模型运行在跨主机的多个 GPU 上。同时,在实验环境中,用户还可以采用 GPU&CPU 混合推理或纯 CPU 推理模式,利用 CPU 算力来运行大模型,提供更广泛的兼容性和灵活性。
真实原因:在工作中选择这个平台的一个原因是,我用ollama无法很好的支撑 bge 等embedding模型。后来找到了Xinference平台,确实不错,但出现了一个小问题,始终无法运行在GPU上,而且相关的模型加载,出错的问题处理,都非常不方便。
GPUStack平台,完全解决了我的当前痛点问题,在加载模型过程中,清晰的日志可以很好的展示过程,另外对于GPU的支持非常好。而且可以实时监控占用情况。
2. 部署实施
参考:官网文档:Overview - GPUStack,包含安装、升级及使用说明。
2.1 环境要求
参考:Installation Requirements - GPUStack
GPUStack requires Python version 3.10 to 3.12.
ubuntu >= 20.04
CUDA 12以上。
2.2 脚本安装
1)创建虚拟环境
conda create -n gpustack python=3.12
# 激活
conda activate gpustack2)脚本安装
use the installation script available at https://get.gpustack.ai to install GPUStack as a service on systemd and launchd based systems.
直接参考官网给的各种脚本。
# Run server.
curl -sfL https://get.gpustack.ai | sh -s -
# Run server without the embedded worker.
curl -sfL https://get.gpustack.ai | sh -s - --disable-worker
# Run server with TLS.
curl -sfL https://get.gpustack.ai | sh -s - --ssl-keyfile /path/to/keyfile --ssl-certfile /path/to/certfile
# Run server with external postgresql database.
curl -sfL https://get.gpustack.ai | sh -s - --database-url "postgresql://username:password@host:port/database_name"
# Run worker with specified IP.
curl -sfL https://get.gpustack.ai | sh -s - --server-url http://myserver --token mytoken --worker-ip 192.168.1.100
# Install with a custom index URL.
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s -
# Install a custom wheel package other than releases form pypi.org.
curl -sfL https://get.gpustack.ai | INSTALL_PACKAGE_SPEC=https://repo.mycompany.com/my-gpustack.whl sh -s -
# Install a specific version with extra audio dependencies.
curl -sfL https://get.gpustack.ai | INSTALL_PACKAGE_SPEC=gpustack[audio]==0.4.0 sh -s -根据实际情况,调整了端口,脚本如下:
# --port 7080
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s - --port 7080时间有点久,终于结束:
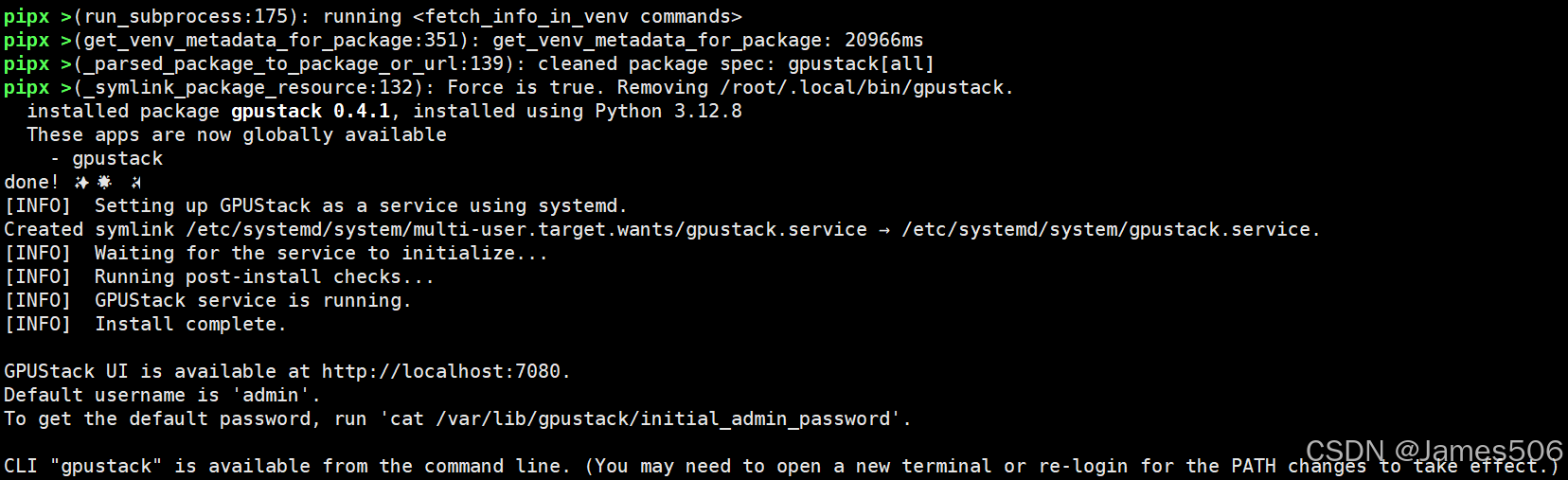
安装完毕后,创建了 gpustack 的后台服务:
systemctl start gpustack
systemctl stop gpustack
systemctl restart gpustack
systemctl enable gpustack3)获取初始 admin 密码
cat /var/lib/gpustack/initial_admin_password4)登录
因为对7080进行了内网映射到 ECS服务器上,并在域名上开了二级域名,对外访问。
或者直接 http:// ip : 端口 访问。
admin登录,输入默认密码,然后根据提示修改新的密码。
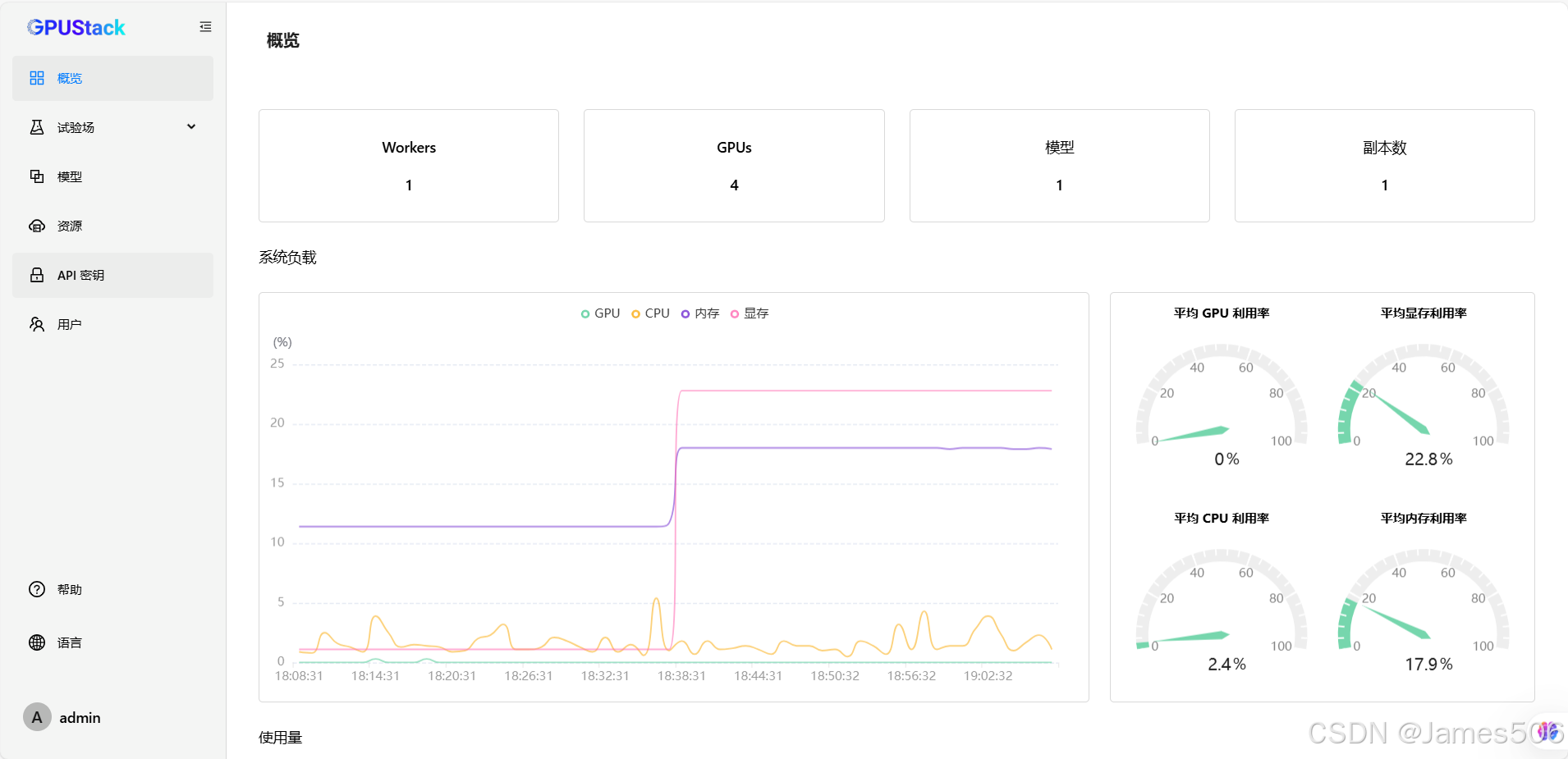
5)API密钥
新建,并记录,可以设置有效期。
6)部署模型
- GGUF 模型用 llama-box(支持 Linux, macOS 和 Windows)。
- 非 GGUF 的音频模型用 vox-box,其它非 GGUF 的模型用 vLLM(仅支持 x86 Linux)。
- 若需部署音频模型取消勾选 GGUF 复选框。
- vLLM不支持rerank的endpoint,要选gguf格式的。
- xinference的rerank可能是用transformers跑的,vLLM本身都不支持的。gpustack是用llama-box(llama.cpp)跑,要用gguf格式。
- 做embedding的话,vLLM跑safetensors的,或者llama-box跑gguf的都可以,reranker的话就只能gguf的。
部署模型时,可以选择多种渠道(HF,Ollama,ModelScope,本地),在国内选择 ollama或者modelscope,下载模型很快。
注意针对不同的模型类别,选择后端。另外可以指定GPU调度方式,在特定的GPU上运行。
部署完毕LLM、Embedding、Reranker模型后,可以在试验场进行测试验证。
# 简单测试
curl http://192.168.50.4/v1/rerank \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${YOUR_GPUSTACK_API_KEY}" \
-d '{
"model": "bge-reranker-v2-m3",
"top_n": 3,
"query": "test",
"documents": [
"test2",
"test3"
]
}'7)接口文档
发布的地址,添加 docs,可以看到全部的接口说明。
http:// ip: port / docs
2.3 Docker安装
目前支持 Linux with Nvidia GPUs。
宿主机器:Driver Version: 535.129.03 CUDA Version: 12.2
镜像中版本:Driver Version: 535.129.03 CUDA Version: 12.4
1)docker环境
要求安装 docker,并且安装并配置NVIDIA Container Toolkit。具体可以参考《docker的安装与使用摘要》
2)docker安装
# 新建目录
mkdir -p /data/gpustack
docker run -d --name gpustack --gpus all --restart always -p 7080:80 --ipc=host -v /data/gpustack:/var/lib/gpustack gpustack/gpustack启动完毕后一切正常,但下载模型后启动报错:
Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW原因:可能是因为镜像容器的 CUDA版本12.4 与宿主 12.2不匹配导致。因暂时无法在服务器上更新升级GPU驱动及CUDA版本,所以docker方式暂缓处理。后面再补充。
参考:
python - CUDA initialization: Unexpected error from cudaGetDeviceCount() - Stack Overflow
3. 多节点处理
目前server需要能够直连worker的一些端口,如果能通可以。未来可能会优化一下改成worker能单向连通server即可。
具体端口需求参考这里的port requirements Installation Requirements - GPUStack
要注意一下worker的注册ip,server是通过worker ip + 端口去连接的worker的,如果能通就可以,worker ip可以通过参数指定。
这种方式,与K8S的集群处理方式很像,而且管理起来非常方便。
(end)


















 5648
5648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









