







目录结构
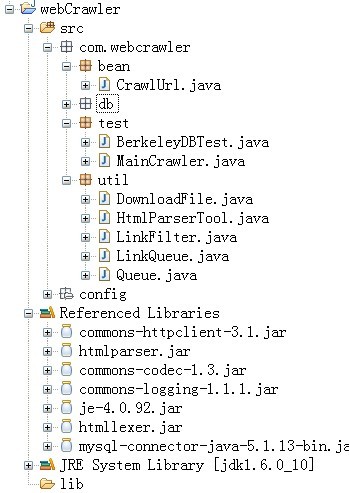
第一步:
com.webcrawler.util.Queue.java
第二步:
com.webcrawler.util.LinkQueue.java
第三步:
com.webcrawler.util.LinkFilter.java
第四步:
com.webcrawler.util.HtmlParserTool.java
第五步:
com.webcrawler.util.DownloadFile.java
第六步:
com.webcrawler.test.MainCrawler.java
That's all.
所有jar包在















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









