| 二、方法、步骤: 1、阅读实验辅助材料,学会解读以下调度相关的信息:top命令输出的多核及调度相关信息、ps查看到的调度相关信息、/proc/cpuinfo、/proc/PID/sched、/proc/PID/status、/proc/PID/stat、/proc/sched_debug、/proc/schedstat。 借助google工具查找资料,学习使用Linux进程间调度API,学习使用通信:管道、消息队列、共享内存的API,完成以下实验操作 操作部分: 2、在一个空闲的单核Linux系统上用nice命令调整两个进程的优先级(20%)
- 要求:使得它们各自使用约1/5和4/5的CPU资源。用top和/proc/PID/sched展示各进程使用的调度策略以及调整前后的优先级变化,用top命令展示CPU资源分配的效果。
3、在一个空闲的双核Linux系统上启动P1/P2/P3/P4四个一直就绪不阻塞进程。(20%)
- 要求:使得P1/P3在第一个处理器上运行各占50%的CPU资源,P2/P4在另一个处理器上运行,各自30%和70%的CPU资源。展示并记录/proc/cpuinfo给出的系统核数,展示并记录进程在各处理器上的绑定情况,展示并记录top命令给出的CPU资源分配情况。运行第5个不阻塞进程,用top查看并记录负载均衡现象,用/proc/PID/sched展示并记录各进程在处理器核间的迁移次数。
4、在一个空闲的单核Linux系统运行两个进程,以相同优先级的RR实时调度的进程,在上述两个进程结束前运行另一个优先级更高的FIFO进程。(20%)
- 要求:用top和/proc/PID/sched展示并记录各进程的调度策略和优先级,展示并记录FIFO进程抢占CPU的现象,展示并记录两个RR进程轮流执行的过程。
5、设计编写以下程序,着重考虑其同步问题(40%):
- 一个程序(进程)从客户端读入按键信息,一次将“一整行”按键信息保存到一个共享存储的缓冲区内并等待读取进程将数据读走,不断重复上面的操作;
- 另一个程序(进程)生成两个进程/线程,用于显示缓冲区内的信息,这两个线程并发读取缓冲区信息后将缓冲区清空(一个线程的两次显示操作之间可以加入适当的时延以便于观察)。
- 在两个独立的终端窗口上分别运行上述两个程序,展示其同步与通信功能,要求一次只有一个任务在操作缓冲区。
要求: 使用posix信号量来完成这里的生产者和消费者的同步关系,其中消费者两个线程的互斥使用posix互斥量来实现。 运行程序,记录上述进程/线程完成通信的操作过程的截屏并给出文字说明。 通过/proc文件系统和ipcs命令查看和记录共享内存创建撤销等操作、信号量数值变化、进程阻塞的过程。
三.实验过程及内容:
- 阅读实验辅助材料,学会解读以下调度相关的信息:top命令输出的多核及调度相关信息、ps查看到的调度相关信息、/proc/cpuinfo、/proc/PID/sched、/proc/PID/status、/proc/PID/stat、/proc/sched_debug、/proc/schedstat。
- 根据实验辅助资料,关闭虚拟机并且设置cpu数目>1且小于本机cpu总数,如图1-1。
 图 1‑1 设置cpu数目
-
- 如图1-2,运行cat /proc/cpuinfo 查看cpu情况。
 图 1‑2 /proc/cpuinfo 查看cpu
-
- 如图1-3,使用top指令后可以查看系统整体的统计信息与各个进程的统计信息。从前5行我们可以看出:
- 系统运行了11分钟,有两个用户登录,1/5/15分钟的平均负载为0.02/0.20/0.25.
- 总任务数为340,其中1个正在运行的进程,260个阻塞进程,0个暂停、被跟踪进程,0个僵尸进程。
- 0.2%的cpu运行用户空间的代码,内核代码只占用0.2%的cpu时间,而空闲cpu时间占99.5%
- 低优先级的用户态代码、io等待、硬件中断、虚拟化等占用cpu时间都为0%,软中断占用0.1%cpu时间。
- 第四第五行都是内存相关统计,与free指令输出完全相同。
- 进程统计信息中,PR与NI是优先级与NICE值,S是status进程状态,%cpu是进程占用cpu单个时间的百分比,TIME是进程在cpu运行的时间,VIRT是进程虚存空间大小,RES是物理内存占用量,SHR是共享物理内存大小,%MEM是占物理内存总量的百分比
 图 1‑3 top指令查看进程与系统信息
-
- 按下“1”键,top指令前5行将变成cpu的信息展示,但是cpu却有4个,因为根据之前的/proc/cpuinfo指令,我们可以看到有两组cpu有相同的core id 和physical id,说明系统支持超线程技术,ubuntu下的linux为我们虚拟出来了两个额外的cpu。如图1-4.
 图 1‑4 top指令下的cpu信息
-
- Linux 在/proc/sched_debug 中给出了整个系统范围的调度相关统计信息,但其内容分为多个小节。
- 前面部分为系统整体信息(图1-5)
 图 1‑5系统整体信息
-
- 而后面部分按逻辑cpu分成多个部分,由于我的系统为双cpu+双核,所以有cpu#0、cpu#1、cpu#2、cpu#3四个部分的统计信息(图1-6),比较发现有个异常的现象:.ur_uniterruptible在cpu0和cpu3是负值,查阅资料发现,透过这个变数会统计目前rq中有多少task属于TASK_UNINTERRUPTIBLE的状态。当呼叫函数active_task时,会把nr_uninterruptible值减一,并透过 该函数enqueue_task把对应的task依据所在的scheduling class放在 对应的rq中,并把目前rq中nr_running值加一。
 图 1‑6 0号处理器的信息
-
- 对于cpu0有cfs类型的cfs_rq[0]和RT类型的rt_rq,从图1-7可以看出,两者都没有就绪的实时进程,CPU0 上就绪进程则在“runnable_tasks:”标签的后面,各列信息分别是:switches 切换次数、prio 优先级、wait-time 等待 IO 的时间、sum-exec 运行时间以及 sum-sleep 阻塞时间。同理,CPU1 则有 cfs_rq[1]和 rt_rq[1]等内容。
 图 1‑7 cfs队列详情
-
- 使用/proc/schedstat指令,可以显示其他的调度统计信息,如图1-8,我们可以看到在四个cpu后面最后三个数字,其分别代表该处理器上进程执行时间总和、进程等待运行时间的总和以及时间片总数。
 图 1‑8 使用/proc/schedstat指令
-
- 阅读材料时,发现有一句有逻辑错误,如图1-9。
 图 1‑9 红色框框“但是”运用不正确
-
- 接下来我们用ps –aux来查看系统中全部进程的状态。如图1-10,我们可以看到STAT一列,其代表的是BSD格式的进程状态,通过man ps指令可以看到其各个状态的解释(图1-11),通过手册我们可以看到:大部分进程为S与I也就是可中断睡眠和多线程状态,有些带<号表示比默认优先级高。
- 根据查看bash进程所在行,我们可以看到:虽然bash从01:45就开始启动运行,但是其TIME始终为0:00,也就是说linux认为它几乎没有运行,所以可以推断在没有按键的时候,bash都是在阻塞状态,只有在执行命令那一瞬间是running,其余时间都是“睡眠”状态。
  图 1‑10 ps-aux指令执行  图 1‑11 STAT状态解释
-
- 根据提供的试验资料,编写HelloWorld-loop-getchar.c的代码,目的在于实现阻塞等待按键功能,查看进程调度状态变化(图1-12)。
 图 1‑12 编写的阻塞循环进程
-
- 我们执行上述程序,并且在必要的时候按下任意键使得程序的循环可以继续(图1-13),然后我们使用ps命令可以看到Helloworld-loop-getchar进程交替进入前台运行的running和interruptible状态(图1-14),这更加加深了我们对进程状态的理解。
 图 1‑13 运行getchar程序  图 1‑14 ps-aux查看进程状态
-
- 暂停上述程序,并执行/proc/pid/status,发现该进程变成了T状态也就是暂停状态,其父进程id为1607,文件描述符大小为256,虚存空间占用4512kB,物理内存占用796KB(图1-15).
 图 1‑15 /proc/pid/status指令
-
- 我们使用/proc/3321/stat指令查看进程活动信息,该指令的所有统计值都是从进程启动到累计当前时刻(图1-16)。
- 第一个数字代表pid=3321,然后进程名称为HelloWorld-loop,状态为T:stopped,父进程id为1607,线程组号为3321,任务所在的会话组id为1607,该任务的tty中断设备号为34816,主设备号为34815/256,次设备号为34815-主设备号,终端的进程组号为39052,进程标志位为1077936128,该任务不需要从硬盘拷数据而发生的缺页次数为96。
- 累计的该任务的所有的 waited-for 进程曾经发生的次缺页的次数目为0,该任务需要从硬盘拷数据而发生的缺页(主缺页)的次数为0,累计的该任务的所有的 waited-for 进程曾经发生的主缺页的次数目为0,该任务在用户态运行的时间为367jiffies,该任务在核心态运行的时间、累计的该任务的所有的 waited-for 进程曾经在用户态运行的时间、累计的该任务的所有的 waited-for 进程曾经在核心态运行的时间都为0;
- 任务的动态优先级为20,任务的 NICE 值为0,该任务所在的线程组里线程的个数为1;由于计时间隔导致的下一个 SIGALRM 发送进程的时延为0;该任务启动的时间为32920jiffies;该任务的虚拟地址空间大小为4620288 page;该任务当前驻留物理地址空间的大小为199。
- 该任务能驻留物理地址空间的最大值为1844674;该任务在虚拟地址空间的代码段的起始地址为4073709551615;该任务在虚拟地址空间的代码段的结束地址为94193026588672;该任务在虚拟地址空间的栈的结束地址为94193026590904;esp(32 位堆栈指针) 的当前值为140726375713792;EIP(32 位指令指针)的当前值、待处理信号的位图、阻塞信号的位图、忽略的信号的位图、被俘获的信号的位图、调度的调用点都为0;
 图 1‑16 /proc/PID/stat 内容
- 在一个空闲的单核Linux系统上用nice命令调整两个进程的优先级
- 要求:使得它们各自使用约1/5和4/5的CPU资源。用top和/proc/PID/sched展示各进程使用的调度策略以及调整前后的优先级变化,用top命令展示CPU资源分配的效果
- 如图2-1,将虚拟机设置为单核,并且编写Run-NICE.sh脚本(图2-2),目的是为了运行两个相同的程序,两个进程都按照普通优先级来运行。
 图 2‑1将虚拟机切换成单核  图 2‑2 编写Run-NICE.sh脚本
-
- 运行脚本后,我们执行ps –a指令,发现两个进程执行时间都相等。
 图 2‑3 运行脚本后ps –a执行结果
-
- 使用top指令观察,两个进程优先级与NICE值都相同,且cpu占比都为48.8%,也就是1:1。
 图 2‑4 top指令观察占用cpu情况
-
- 接着从屏显 1-13 比较一下两者的/proc/PID/sched 差异,两个的启动时间 se.exec_start、虚拟时间推进 se.vruntime 都是接近的,但是各自获得 CPU 上运行的时间 se.sum_exec_runtim差异较小,分别是978416.774481和978417.002082(图2-5)。
 图 2‑5 /proc/pid/sched 观察优先级及运行时间
-
- 我们使用renice指令调整两个进程的nice值,进而达到调整优先级的效果(图2-6)。
- 理论上来说,pri=20+NICE值,在修改后原本pri=20,NICE=0的两个进程应该会变成pri=5,NICE=-15以及pri=11,NICE=-9。
 图 2‑6 renice调整NICE值
-
- 我们使用top指令来观察改变nice值后的进程所占用的cpu对比,发现符合预期,且cpu占比对比为1:4,分别是80.4%与20.2%(图2-7)。
 图 2‑7 top指令观察调整nice值后的两进程所占cpu
-
- 使用cat /proc/pid/sched观察更改NICE值后两进程(图2-8),观察得知:
- 两个的启动时间 se.exec_start、虚拟时间推进 se.vruntime 都是接近的,但是各自获得 CPU 上运行的时间 se.sum_exec_runtime差异较大,分别是2262860.003864 和1496434.923960。由于这两个进程一直在做加法,因此从来没有主动让出 CPU,所以它们的自愿切换次数 nr_voluntary_switches 都为 0,进程切换次数nr_switches等于被强制切换的次数nr_involuntary_switches。
 图 2‑8 观察调整NICE后两进程
- 在一个空闲的双核Linux系统上启动P1/P2/P/P4四个一直就绪不阻塞进程。。
- 要求:使得P1/P3在第一个处理器上运行各占50%的CPU资源,P2/P4在另一个处理器上运行,各自30%和70%的CPU资源。展示并记录/proc/cpuinfo给出的系统核数,展示并记录进程在各处理器上的绑定情况,展示并记录top命令给出的CPU资源分配情况。运行第5个不阻塞进程,用top查看并记录负载均衡现象,用/proc/PID/sched展示并记录各进程在处理器核间的迁移次数。
- 展示并且记录/proc/cpuinfo给出的系统核数,图中给出了两个cpu,每个是单核(图3-1)。
 图 3‑1 双核/proc/cpuinfo展示
-
- 编写P1.c/P2.c/P3.c/P4.c/P5.c,每个都是一样的代码,为了实现不阻塞进程,选择了无限循环,如图3-2所示:
 图 3‑2 不阻塞进程的代码
-
- 运行p1-p4,查得pid为34996-34999,使用taskset更改其使用的cpu(图3-3)。
 图 3‑3 taskset更改进程占用的cpu
-
- 通过图3-4我们可以看出,在更改优先级之前,各个进程所占用的cpu基本上是在1:1,于是我们将p2加入进程组,执行cd /sys/fs/cgroup/cpu,然后创建一个新的cgroup,把要控制的process的id 放到这个cgroup的task中,最后限制cpu使用率在30%(图3-5),最后查看top指令发现得到了我们满意的结果:p1与p3各占cpu0的50%,p2与p4各占cpu的30%与70%(图3-6)。
 图 3‑4 分配cpu及限制使用率之前进程占用cpu情况  图 3‑5 对p2,p4设置进程组,并限制其cpu使用  图 3‑6 加入进程组限制cpu后结果
-
- 使用cat /proc/34996/sched /proc/34997/sched /proc/34998/sched /proc/34999/sched指令查看四个进程的cpu之间迁移信息(图3-7/3-8/3-9/3-10),可以看出,p1与p3进程的cpu之间迁移次数基本相同,由于使用了cgroup而不是通过调整NICE值来控制进程占用的cpu,所以p2和p4之间的cpu迁移次数接近,不同的是彼此的虚拟时间推进和cpu运行时间的差,两者虚拟时间推进相差三倍,cpu执行时间相差两倍。
 图 3‑7 p1的cpu之间迁移次数  图 3‑8 p3进程cpu之间迁移次数  图 3‑9 p2进程的cpu迁移次数  图 3‑10 p4的cpu迁移次数
- 在一个空闲的单核Linux系统运行两个进程,以相同优先级的RR实时调度的进程,在上述两个进程结束前运行另一个优先级更高的FIFO进程。
- 要求:用top和/proc/PID/sched展示并记录各进程的调度策略和优先级,展示并记录FIFO进程抢占CPU的现象,展示并记录两个RR进程轮流执行的过程。
- 创建并编写RR.c的程序代码,该程序首先是通过fork创建两个优先级相同的实时调度进程,然后将其的优先级设置为1,并且采用RR调度也就是时间片轮转调度,两个RR调度的进程不停地打印当前系统的时间(图4-1、图4-2)。
 图 4‑1 编写RR.c
-
- 如图4-2,编写FIFO.c程序代码,此文件目的在于创建一个FIFA进程调度策略的进程,并赋予起比前者RR进程调度的进程优先级更高,为2。他在运行7000000000个循环后就会自动退出。
 图 4‑2 编写FIFO.C
-
- 进入超级用户,运行./RR.c & ,然后发现进程交替打印出自己的pid(图4-3),然后使用top指令,查看到两RR进程PRI为-2,cpu占比为1:1,且确定都为RR进程(图4-4),在/proc/pid/sched 中,我们看到两个进程的优先级为98(图4-5).
 图 4‑3 RR进程交替打印  图 4‑4 top查看RR进程详细信息   图 4‑5 /proc/pid/sched展示进程详细信息
-
- 把ununtu调成单核单cpu,然后先运行./RR (在mobaxterm上),然后在vmware命令行上运行./FIFA,发现RR的两个进程被阻塞,中间转去执行了./FIFA,出现了抢占的现象(图4-6),为了比较RR调度与FIFO调度的优先级以及区别,我们编写了一个FIFA-RR.sh的脚本(图4-7),并且运行脚本并执行top(4-8),几秒后再执行top(4-9),发现FIFO调度的进程进行时会阻塞RR调度的进程。
 图 4‑6 FIFA进程抢占RR进程  图 4‑7 编写FIFA-RR.sh脚本  图 4‑8 一开始运行脚本的top图  图 4‑9 过了几秒后FIFO调度进程退出后的top
-
- 再次执行脚本,同时快速对FIFO调度的进程以及RR调度的进程执行 cat /proc/pid/sched命令,然后发现FIFA进程的调度策略为FIFO,优先级为97(图4-10),RR进程的调度策略为RR,优先级为98(图4-11)。
 图 4‑10 FIFA进程的/proc/pid/sched 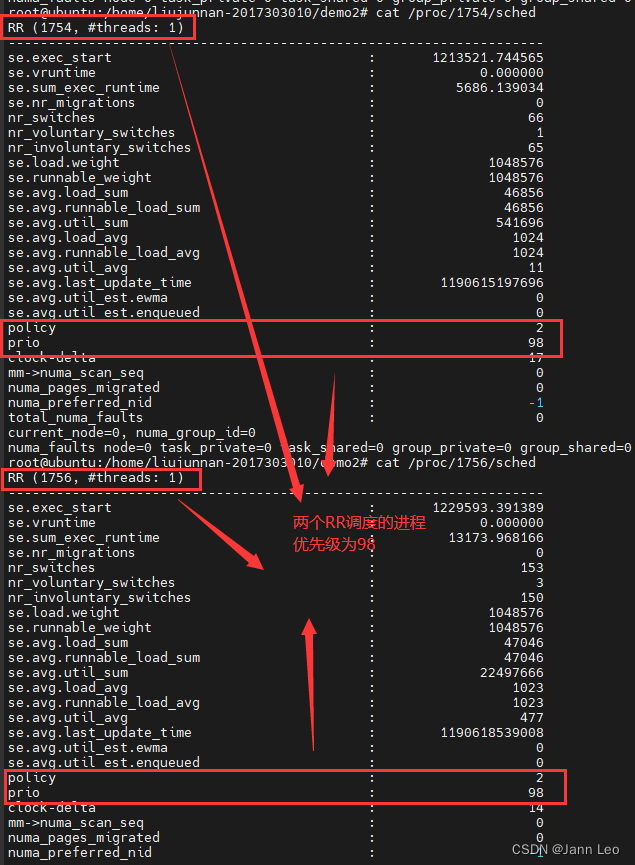 图 4‑11 RR进程的/proc/pid/sched
- 设计编写以下程序,着重考虑其同步问题
- 一个程序(进程)从客户端读入按键信息,一次将“一整行”按键信息保存到一个共享存储的缓冲区内并等待读取进程将数据读走,不断重复上面的操作;
- 另一个程序(进程)生成两个进程/线程,用于显示缓冲区内的信息,这两个线程并发读取缓冲区信息后将缓冲区清空(一个线程的两次显示操作之间可以加入适当的时延以便于观察)。
- 这道题显然是让我们写生产者与消费者相关的代码,其中特别要注意的是最内层是互斥资源,防止死锁,对于生产者消费者代码中的信号量思路如下。
- w_mutex 控制同一时间只有一人操作缓冲区
- empty 表示缓冲区是否有空位
- full 表示缓冲区是否有数据,1 则有数据
- r_mutex 保证同一时间只有一个消费者在读数据
- 我们写下生产者代码producer.c (图5-1),思路是首先等待empty,确保有空位,等待w_mutex,以便可以霸占缓冲区,所有准备工作以及信号量完成后,我们就可以进行写数据操作,完成后释放w_mutex以及full信号量即可。
 图 5‑1 producer.c程序详情
-
- 我们接着编写消费者代码 consumer.c,主要思路是:先等待full信号量,确保有数据可读取,等待r_mutex,保证只有我一个在读操作缓冲,等待w_mutex,防止有人在写缓冲,然后才能进行读操作,完成操作后相继释放w_mutex,r_mutex和empty即可(图5-2)。
 图 5‑2 consumer.c 详情
-
- 将生产者使用gcc编译,然后运行,之后我们使用ipcs -m指令可以看到,生产者产生了2048字节的虚拟内存(图5-3)。
 图 5‑3 生产者产生内存
-
- 我们通过查看 /dev/shm 目录下的文件来检查创建的信号量。率先启动生产者进程,产生三个信号量,分别是 empty,full 和 w_mutex,如图5-4:
 图 5‑4 生产者产生的3个信号量
-
- 我们使用gcc编译消费者consumer.c,然后使用生产者发送信息,我们可以看到2568与2569线程交替print,当2568线程霸占缓冲区的时候,2569号线程被挂载到等待队列。当2568号线程释放对应信号量的时候,2569号马上被调出(图5-5)。
 图 5‑5 两线程交替打印生产者信息 | 





















 694
694

 非常没帮助
非常没帮助
 没帮助
没帮助
 一般
一般
 有帮助
有帮助
 非常有帮助
非常有帮助
 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









