







 #define _SECURE_SCL 0
#include
<boost/foreach.hpp>
#include
<list>
#include
<vector>
#include
<algorithm>
#include
<cstdlib>
#include
<time.h>
#include
<stdio.h>
using namespace
std;template<typename Container>
#define _SECURE_SCL 0
#include
<boost/foreach.hpp>
#include
<list>
#include
<vector>
#include
<algorithm>
#include
<cstdlib>
#include
<time.h>
#include
<stdio.h>
using namespace
std;template<typename Container>

 void generate(typename Container & v) ...
{
void generate(typename Container & v) ...
{ size_t size = v.size();
size_t size = v.size();
 for (size_t i=0; i< size ; ++i) ...{ v[i] = i;//rand();
for (size_t i=0; i< size ; ++i) ...{ v[i] = i;//rand(); }
} }
struct case1 ...
{int operator() (const vector<int> & v, size_t size) ...{ int sum=0; vector<int>::const_iterator it = v.begin(); for (size_t i=0; i< size; ++i, ++it ) ...{ sum += *it; } return sum;}}
;struct case2 ...
{int operator() (const vector<int> & v, size_t size) ...{ int sum=0; for(size_t i=0; i< size; ++i) ...{ sum += v[i]; } return sum;}}
;struct case3 ...
{int operator() (const vector<int> & v, size_t size) ...{ int sum=0; BOOST_FOREACH(int x, v) ...{ sum += x; } return sum;}}
;struct case4 ...
{int operator() (const vector<int> & v, size_t size) ...{ int sum=0; for (vector<int>::const_iterator it = v.begin(); it != v.end(); ++it ) ...{ sum += *it; } return sum;}}
;template<typename T>
__int64 Do(typename T op, vector
<int> &v, int M) ...
{ size_t size = v.size(); __int64 sum = 0; for (int i=0;i<M;++i) ...{ generate(v); sum += op(v, size); } return sum;}
int main() ...
{ srand(static_cast<unsigned int>(time(NULL)) ); vector<int> v(65536); int M= 10000; printf("1 : %d ", Do(case1(),v,M)); printf("2 : %d ", Do(case2(),v,M)); printf("3 : %d ", Do(case3(),v,M)); printf("4 : %d ", Do(case4(),v,M)); }
}
struct case1 ...
{int operator() (const vector<int> & v, size_t size) ...{ int sum=0; vector<int>::const_iterator it = v.begin(); for (size_t i=0; i< size; ++i, ++it ) ...{ sum += *it; } return sum;}}
;struct case2 ...
{int operator() (const vector<int> & v, size_t size) ...{ int sum=0; for(size_t i=0; i< size; ++i) ...{ sum += v[i]; } return sum;}}
;struct case3 ...
{int operator() (const vector<int> & v, size_t size) ...{ int sum=0; BOOST_FOREACH(int x, v) ...{ sum += x; } return sum;}}
;struct case4 ...
{int operator() (const vector<int> & v, size_t size) ...{ int sum=0; for (vector<int>::const_iterator it = v.begin(); it != v.end(); ++it ) ...{ sum += *it; } return sum;}}
;template<typename T>
__int64 Do(typename T op, vector
<int> &v, int M) ...
{ size_t size = v.size(); __int64 sum = 0; for (int i=0;i<M;++i) ...{ generate(v); sum += op(v, size); } return sum;}
int main() ...
{ srand(static_cast<unsigned int>(time(NULL)) ); vector<int> v(65536); int M= 10000; printf("1 : %d ", Do(case1(),v,M)); printf("2 : %d ", Do(case2(),v,M)); printf("3 : %d ", Do(case3(),v,M)); printf("4 : %d ", Do(case4(),v,M)); }
debug模式下:
先不看case3,因为BOOST_FOREACH的效率在debug模式下与其它相差较大。Case4也不看

case1与case2的效率基本相同。
注意case1中的主要操作是*和++;而case2中主要是[]和size(),特别的,size()还可以改STL原码除去,这样case2将大为缩短时间。
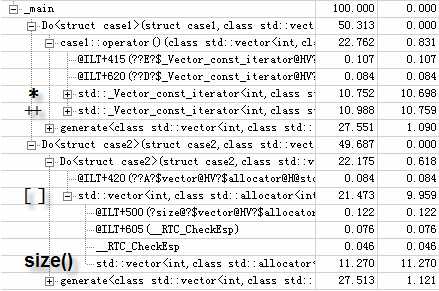
而在Release模式下,case2比case1略优:
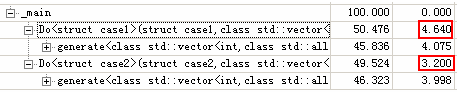
通过跟踪可以发现:
vector的size()函数里使用了一个三元操作符?:,而不是直接返回size,但这里没有安全检查。
operator*()与++()中,即便在release版本中,都会包含指针检查(ASM中的__imp___invalid_parameter_noinfo部分),每个操作都包括_SCL_SECURE_VALIDATE及_SCL_SECURE_VALIDATE_RANGE,但这些消耗的时间不多。两个检查若没通过都会转到__imp___invalid_parameter_noinfo中。
struct case1 {
int operator() (const vector<int> & v, size_t size) {
int sum=0;
vector<int>::const_iterator it = v.begin(); // 一个检查
for (size_t i=0; i< size; ++i, ++it ) { // 一个检查
sum += *it; // 一个检查
}
return sum;
}};
struct case2 {
int operator() (const vector<int> & v, size_t size) {
int sum=0;
for(size_t i=0; i< size; ++i) {
sum += v[i];//一个检查,但是包含求size()的检查
}
return sum;
}};
在[]操作中,包括一个_SCL_SECURE_VALIDATE_RANGE(_Pos < size()),而求size()费时。
Case4中包含更多的安全检查。
要消除这些安全查检,可以定义_SECURE_SCL为0。
消除检查之后,得到如下结果。两种方式的效率已经相当接近,但case1还是略优。改写后的Case3和4也与前两者接近。

剩下的只能用vtune来分析每个操作了。
结论:不论用哪种方法,release版的效率都差不多。
1. 少使用size()。
2. 使用[]访问,使调试与发布的运行效率接近。















 4001
4001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









