









How can Machine Learn? - Nonlinear Transformation
之前我们讨论的都是 线性模型,这一节我们讨论如何处理非线性模型的问题
1. Quadratic Hypotheses
线性模型可以通过VC Bound 进行约束,从而保证了数据量足够大,并且有算法找到合适的权值w。 但是对于非线性模型,我们如何处理呢?怎么能肯定的说非线性模型的机器学习是可行的呢?
1.首先,非线性模型很显然是线性不可分(non-linear separable)的,如图一所示。可以看到无论怎样都不可能用一条直线分开,图中能刚好用一个圆分割,所以管它叫圈圈可分(Circular Separable),用圆的公式稍做变形可以得到这个圆的公式(1)
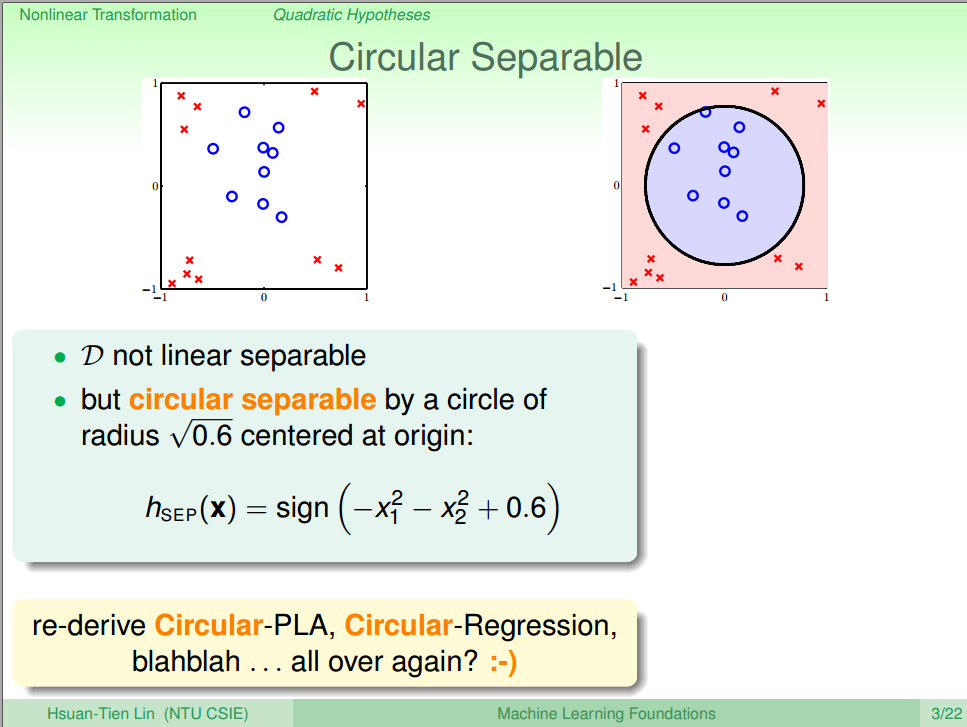
2.类似于之前对Linear Model的公式变化,我们对公式(1)稍作调整,可以得到公式类似的结果,如公式(2)所示。 公式(2)的是z 不是 x,这个公式把 {(xn,yn)} 转换成了线性可分的 {(zn,yn)} ,这种转换成为特征转化(feature transform)用符号 Φ 表示,经过特征转换后的图如图二所示。
$$
\begin{align*}
h_{SEP}(x) &= sign(-x_1^2 - x_1^2 + 0.6) \
&= sign( \underbrace{0.6}{w_0} \times \underbrace{1}{x_0} + \underbrace{(-1)}{w_1} \times \underbrace{x_1^2}{z_1} + \underbrace{(-1)}{w_2} \times \underbrace{x_2^2}{z_2}) \
&= sign(w^T z)
\end{align*}
\tag{
2
}
$$
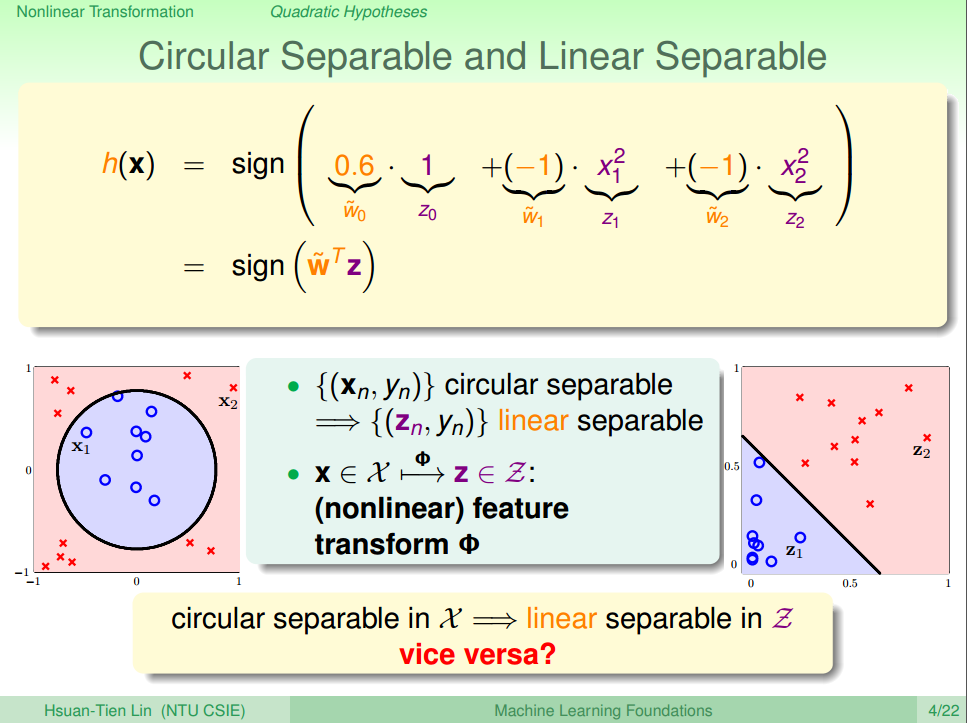
3.那么如果能在z空间线性可分,反过来能不能在x空间圆形可分呢?
答案是能的,下面进行证明。首先我们通过带入不同的值,得到不同情况下的空间图,如表格1所示
表格1
| w | 假设函数h(x) | 形状 |
|---|---|---|
| (0.6, -1, -1) | sign(0.6-x_1^2-1x_2^2) | 圆形(circle) |
| (0.6, -1, -2) | sign(0.6-x_1^2-2x_2^2) | 椭圆形(ellipse) |
| (0.6, -1, +2) | sign(0.6-x_1^2+2x_2^2) | 抛物线(hyperbola) |
| (0.6, +1, +2) | sign(0.6+x_1^2+2x_2^2) | constant:全为+1 |
然后我们可以初步看出,可以表示多种图形,但是这并不是全部图形,比如说圆形的话是经过圆形的圆。所以我们用公式(3)来表示任意的二次曲面图形。
可以发现无论怎样的情况,z空间都能对应到x空间去,也就是说通过算法在z空间里找到合适的权值w,就可以对应在x空间得到我们需要的图形。所以这种方法是可行的。
2. Nonlinear Transform
上一部分我们定义了什么了二次hypothesis: z空间,那么这部分将介绍如何设计一个好的二次hypothesis来达到良好的分类效果。那么目标就是在z空间中设计一个最佳的分类线。
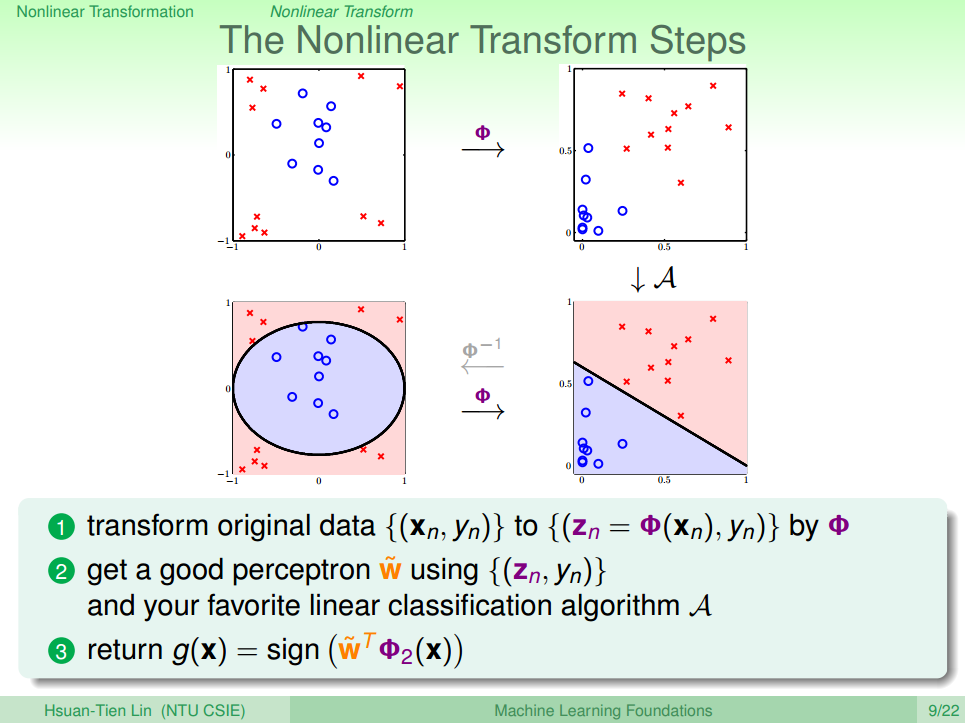
整个过程就是通过特征转换的映射关系,把X空间的问题换到Z空间去做线性分类,具体步骤如下,也可以参考图三。
- 通过特征转换函数 Φ ,将在X空间中不可分的数据集 {(xn,yn)} 转换成在Z空间中可分的数据集 {(zn,yn)} ;
- 使用线性分类算法通过数据集 {(zn,yn)} 获得寻找最优权值向量 w ;
- 回到X空间得到需要的返回假设函数
g(x)=sign(wTΦ(xn)) .
其实,我们以前处理机器学习问题的时候,已经做过类似的特征变换了。比如数字识别问题,我们从原始的像素值特征转换为一些实际的concrete特征,比如密度、对称性等等,这也用到了feature transform的思想。如图四所示

这种非线性模型算法结合了非线性转换和线性算法,因此包含两个重要的特征:转换函数和线性模型。这种求解非线性分类的思路不仅可以解决二次分类的问题,也可以用在三次感知器、三次回归,甚至多项式回归的问题上。
3. Price of Nonlinear Transform
这一节我们要通过评估使用非线性转换说需要的代价来评估这种方法是否值得使用。下面将从2个问题去讨论:1.空间复杂度 2.能否保证机器能学习(模型的泛化能力会变差)
1.首先,若x空间含有d个类别,即d个特征,特征维度是d维的,那么二次多项式个数,即z空间特征维度是如公式(4)所示
比如说d为2的时候,那么二次多项式为
(1,x1,x2,x21,x22,x1x2,x22)
共6个
进一步推导到更高维度Q的多项式,那么z空间的特征维度如公式(5)所示
由上式可以看出,计算z域特征维度个数的时间复杂度是Q的d次方,随着Q和d的增大,计算量会变得很大。同时,空间复杂度也大。也就是说,这种特征变换的一个代价是计算的时间、空间复杂度都比较大。如图五所示

2.另一方面,关于泛化能力的问题,因为z域中特征个数随着Q和d增加变得很大,同时权重w也会增大,即自由度增加,VC Dimension增大。根据之前课程的讨论:VC Dimension过大,模型的泛化能力会比较差。
下面举例说明。首先分类结果如图六所示

上图中,左边是用直线进行线性分类,存在分类错误的点;右边是用四次曲线进行非线性分类,所有点都分类正确。
- 从分类结果来看:单从平面上这些训练数据来看,右边的图(四次曲线)的分类效果更好
- 但是从泛化能力来看的话:四次曲线模型很容易带来过拟合(下一节会讨论)的问题,虽然它的 Ein 比较小,从泛化能力上来说,还是左边的分类器更好一些。也就是说VC Dimension过大会带来过拟合问题, d˘+1 不能太大了。
那么如何选择合适的Q,来保证不会出现过拟合问题,确保模型的泛化能力足够强呢?一般情况下,为了尽量减少特征自由度,我们会根据训练样本的分布情况,人为地减少、省略一些项。但是,这种人为地删减特征又将会带来一些“自我分析”代价,虽然对训练样本分类效果好,但是对训练样本外的样本,不一定效果好。所以,一般情况下,还是要保存所有的多项式特征,避免对训练样本的人为选择。这种人为的判断好坏已经是人类的大脑处理过后的结果,在机器学习中应避免。
4. Structured Hypothesis Sets
这一节我们先通过举例,最终总结出从x空间到y空间的多项式变化
1.首先如果d为1维的话,如公式(6)所示,多项式中只有常数项
2.如果d为2维的时候,如公式(7)所示,多项式中包含了1维的多项式
3.如果d为3维的时候,如公式(8)所示,多项式中包含了2维的多项式
3.以此类推,如果d为Q维的时候,如公式(9)所示,多项式中包含了(Q-1)维的多项式
并且可以发现,不能维度的Hypotheses存在以下关系,如公式(10)所示
上述过程如图七所示,另外我们把这种结构叫做Structured Hypothesis Sets,如图八所示


从图八可以看出,随着变换多项式的阶数d增大,虽然 Ein 逐渐减小,但是model complexity会逐渐增大,造成 Eout 很大,所以阶数不能太高。所以,如果选择的阶数d很大,确实能使 Ein 接近于0,但是泛化能力通常很差,我们把这种情况叫做tempting sin。所以,一般最合适的做法是先从低阶开始,如先选择一阶hypothesis,看看 Ein 是否足够小,如果 Ein 足够小的话就选择一阶,如果 Ein 太大不满足需求,那么我们就逐次增加阶数,直到满足要求为止。也就是说,尽量选择低阶的hypothes,这样才能得到较强的泛化能力。
Summary
- 首先介绍了非线性分类模型,通过非线性的特征变化,将非线性模型映射到一个线性空间进行相信分类。
- 接着分析非线性模型的代价:时间和空间复杂度高,而且随着特征纬度的增加,模型的泛化能力变差
- 最后我们通过数学分析得到如何能在使用非线性转化的过程中,尽可能的提高模型泛化能力:尽可能使用简单模型(低阶)。
Reference
[1] 机器学习基石(台湾大学-林轩田)\12\12 - 1 - Quadratic Hypothesis (23-47)
[2] 机器学习基石(台湾大学-林轩田)\12\12 - 3 - Price of Nonlinear Transform (15-37)
[3] 机器学习基石(台湾大学-林轩田)\12\12 - 4 - Structured Hypothesis Sets (09-36)














 5277
5277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









