







第14章 数据分析案例
14.1 来自Bitly的USA.gov数据
2011年,URL缩短服务Bitly跟美国政府网站USA.gov合作,提供了一份从生成.gov或.mil短链接的用户那里收集来的匿名数据。在2011年,除实时数据之外,还可以下载文本文件形式的每小时快照。
以每小时快照为例,文件中各行的格式为JSON(即JavaScript Object Notation,这是一种常用的Web数据格式)。例如,如果我们只读取某个文件中的第一行,那么所看到的结果应该是下面这样:

Python有内置或第三方模块可以将JSON字符串转换成Python字典对象。这里将使用json模块及其loads函数逐行加载已经下载好的数据文件:

现在,records对象就成为一组Python字典了:

- 用纯python代码对时区进行计数
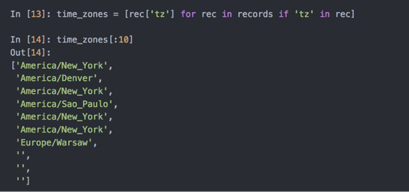
想要知道该数据集中最常出现的是哪个时区(即tz字段),先用列表推导式取出一组时区,但并不是所有记录都有时区字段,这时只需在列表推导式末尾加上一个if ‘tz’ un rec判断即可:
对时区计数,有两个办法,一个较难(只使用标准Python库),另一个较简单(使用pandas)。计数的办法之一是在遍历时区的过程中将计数值保存在字典中:

使用python标准库的更高级工具,简化代码:
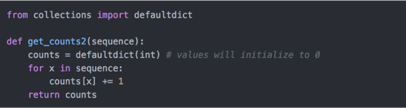
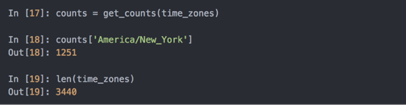
将逻辑写到函数中是为了获得更高的复用性,要用它对时区进行处理,只需将time_zones传入即可:
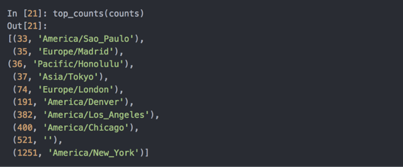
想要得到前10位的时区及其计数值,需要用到一些有关字典的处理技巧:
collections.Counter类,可以使这项工作更简单:

- 用pandas对时区进行计数
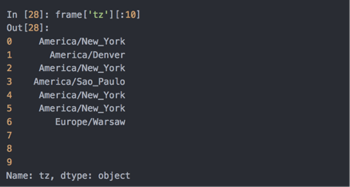
从原始记录的集合创建DateFrame,与将记录列表传递到pandas.DataFrame一样简单,这里frame的输出形式使摘要视图(summary view),主要用于较大的dataframe对象:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









